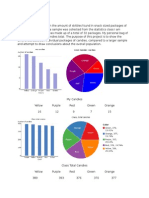
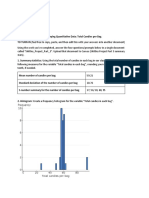
You might also like
- Skittles FinalDocument12 pagesSkittles Finalapi-241861434No ratings yet
- Skittles AssignmentDocument8 pagesSkittles Assignmentapi-291800396No ratings yet
- Final ProjectDocument9 pagesFinal Projectapi-262329757No ratings yet
- The Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer QuestionsDocument7 pagesThe Science of Collecting, Organizing, Summarizing, and Analyzing Information To Draw Conclusions or Answer Questionsapi-438148756No ratings yet
- The Rainbow ReportDocument11 pagesThe Rainbow Reportapi-316991888No ratings yet
- EportfolioDocument12 pagesEportfolioapi-251934892No ratings yet
- Final Math ProjectDocument7 pagesFinal Math Projectapi-316775963No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-242873849No ratings yet
- Math 1040 Statistics Term Project: Blake FreemanDocument10 pagesMath 1040 Statistics Term Project: Blake Freemanapi-252919218No ratings yet
- Math 1040 Skittles Term Project EportfolioDocument7 pagesMath 1040 Skittles Term Project Eportfolioapi-260817278No ratings yet
- Croot Part6 EportfolioDocument16 pagesCroot Part6 Eportfolioapi-276896975No ratings yet
- Math 1040Document3 pagesMath 1040api-219553415No ratings yet
- Term Project ReportDocument9 pagesTerm Project Reportapi-238585685No ratings yet
- Eportfolio StatisticsDocument8 pagesEportfolio Statisticsapi-325734103No ratings yet
- Math 1040 Skittles Term ProjectDocument9 pagesMath 1040 Skittles Term Projectapi-319881085No ratings yet
- Math 1040Document5 pagesMath 1040api-534403229No ratings yet
- Stats ProjectDocument14 pagesStats Projectapi-302666758No ratings yet
- Term Project - EportfolioDocument7 pagesTerm Project - Eportfolioapi-251981709No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-441660843No ratings yet
- Skittles Project 1Document7 pagesSkittles Project 1api-299868669100% (2)
- Skittles Project 2Document10 pagesSkittles Project 2api-316655135No ratings yet
- SkittlesdataclassprojectDocument8 pagesSkittlesdataclassprojectapi-399586872No ratings yet
- SkittleDocument6 pagesSkittleapi-378470372No ratings yet
- Skittles 2 FinalDocument12 pagesSkittles 2 Finalapi-242194552No ratings yet
- StatsfinalprojectDocument7 pagesStatsfinalprojectapi-325102852No ratings yet
- EportfolioDocument8 pagesEportfolioapi-242211470No ratings yet
- Skittles ProDocument9 pagesSkittles Proapi-241124972No ratings yet
- Team Project Part 6 Final ReportDocument8 pagesTeam Project Part 6 Final Reportapi-316794103No ratings yet
- Skittle Pareto ChartDocument7 pagesSkittle Pareto Chartapi-272391081No ratings yet
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Document8 pagesTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832No ratings yet
- Skittles Project Stats 1040Document8 pagesSkittles Project Stats 1040api-301336765No ratings yet
- Math ProfileDocument9 pagesMath Profileapi-454376679No ratings yet
- Skittles Proyect Part 5Document7 pagesSkittles Proyect Part 5api-509398997No ratings yet
- 1040 Term ProjectDocument8 pages1040 Term Projectapi-316127151No ratings yet
- Math 1040 Final ProjectDocument3 pagesMath 1040 Final Projectapi-285380759No ratings yet
- Math 1040 Term ProjectDocument7 pagesMath 1040 Term Projectapi-340188424No ratings yet
- Statistics Project 17Document13 pagesStatistics Project 17api-271978152No ratings yet
- Skittles Project 2Document5 pagesSkittles Project 2api-355504623No ratings yet
- Stats StuffDocument7 pagesStats Stuffapi-242298926No ratings yet
- Skittles ProjectDocument17 pagesSkittles Projectapi-359548770No ratings yet
- Skittles Term Project 11 9 14Document5 pagesSkittles Term Project 11 9 14api-192489685No ratings yet
- Final ProjectDocument6 pagesFinal Projectapi-283261340No ratings yet
- Statistics Term Project E-Portfolio ReflectionDocument8 pagesStatistics Term Project E-Portfolio Reflectionapi-258147701No ratings yet
- Skittles FinalDocument7 pagesSkittles Finalapi-470226556No ratings yet
- Final Stats ProjectDocument8 pagesFinal Stats Projectapi-238717717100% (2)
- Skittles Project CompleteDocument8 pagesSkittles Project Completeapi-312645878No ratings yet
- Skittles Project FinalDocument5 pagesSkittles Project Finalapi-271348941No ratings yet
- Skittles Project Part 1Document6 pagesSkittles Project Part 1api-457501806No ratings yet
- Skittles Term ProjectDocument10 pagesSkittles Term Projectapi-273060240No ratings yet
- Skittles Final ProjectDocument5 pagesSkittles Final Projectapi-251571777No ratings yet
- Skittles Project 5-02Document8 pagesSkittles Project 5-02api-354040698No ratings yet
- Skittle Part 3Document3 pagesSkittle Part 3api-325020845No ratings yet
- The Skittles Project FinalDocument8 pagesThe Skittles Project Finalapi-316760667No ratings yet
- Skittles ProjectDocument6 pagesSkittles Projectapi-319345408No ratings yet
- Skittles New Part3Document1 pageSkittles New Part3api-241435600No ratings yet
- Skittles ProjectDocument5 pagesSkittles Projectapi-271444168No ratings yet
- TP 2 StatsDocument5 pagesTP 2 Statsapi-240850453No ratings yet
- Skittles ProjectDocument9 pagesSkittles Projectapi-252747849No ratings yet
- Math for Grownups: Re-Learn the Arithmetic you Forgot from School so you can calculate how much that raise will really amount to, Figure out if that new fridge will actually fit, help a third grader with his fraction homework, and convert calories into cardio timeFrom EverandMath for Grownups: Re-Learn the Arithmetic you Forgot from School so you can calculate how much that raise will really amount to, Figure out if that new fridge will actually fit, help a third grader with his fraction homework, and convert calories into cardio timeRating: 1 out of 5 stars1/5 (1)
- Random Variables and Probability Distributions: Topic 5Document7 pagesRandom Variables and Probability Distributions: Topic 5Sana SiniNo ratings yet
- Betournay 1Document12 pagesBetournay 1Mouhammed AbdallahNo ratings yet
- Imtc 2005 1604396Document4 pagesImtc 2005 1604396PushpakNo ratings yet
- LearningDocument23 pagesLearningallanNo ratings yet
- Engineering Data AnalysisDocument82 pagesEngineering Data AnalysisAngel Antonio100% (1)
- Spss DeskriptiveDocument9 pagesSpss Deskriptiverivki giyoni ameliaNo ratings yet
- VvenDocument7 pagesVvenAdvendro Chandra0% (1)
- Normal Distribution (Activity Sheet)Document3 pagesNormal Distribution (Activity Sheet)sh1n 23No ratings yet
- How To Use Excel To Conduct An AnovaDocument19 pagesHow To Use Excel To Conduct An AnovakingofdealNo ratings yet
- College Midterm Week 5Document11 pagesCollege Midterm Week 5Adrian AndalNo ratings yet
- 02-Descriptive StatisticsDocument17 pages02-Descriptive StatisticsAva FarjadNo ratings yet
- Raman Spectro Adv DisadvDocument6 pagesRaman Spectro Adv Disadvmanthan212No ratings yet
- CH-2 CompDocument10 pagesCH-2 Compsamuel TesfayeNo ratings yet
- Statistics (Unit-1)Document101 pagesStatistics (Unit-1)mannu02.manishNo ratings yet
- CBSE Class 10 Mathematics Chapter 14 - Statistics Important Questions 2022-23 PDFDocument49 pagesCBSE Class 10 Mathematics Chapter 14 - Statistics Important Questions 2022-23 PDFShaunak BasuNo ratings yet
- C 1045 - 07 (2013)Document13 pagesC 1045 - 07 (2013)Roberto Colonia100% (1)
- (Assignment) : Business OrganizationDocument51 pages(Assignment) : Business Organizationashok kumarNo ratings yet
- Chapter - 1.sampling and Sampling DistrabutionDocument43 pagesChapter - 1.sampling and Sampling DistrabutionNagiib Haibe Ibrahim Awale 6107No ratings yet
- Quality ProgressDocument68 pagesQuality Progressمحمد يسرNo ratings yet
- Comparing Data Worksheet - Mean Median Mode RangeDocument4 pagesComparing Data Worksheet - Mean Median Mode RangechelseaNo ratings yet
- IE 443 Lesson 4 Maintainability and Availability AnalysisDocument46 pagesIE 443 Lesson 4 Maintainability and Availability Analysishamidu athumaniNo ratings yet
- Predicting The Sex of Dovekies by Discriminant AnalysisDocument6 pagesPredicting The Sex of Dovekies by Discriminant AnalysisIvan JerkovićNo ratings yet
- Assessment in Learning 2Document23 pagesAssessment in Learning 2Anjeanette Baltazar CayoteNo ratings yet
- Process Capability: Specification Limits Set atDocument3 pagesProcess Capability: Specification Limits Set atNazia SyedNo ratings yet
- Reevaluation of A Weighted Application Blank For Office PersonnelDocument3 pagesReevaluation of A Weighted Application Blank For Office PersonnelJae H. HaNo ratings yet
- Action Research Improving Schools and Empowering Educators 5th Edition Mertler Test Bank Full Chapter PDFDocument32 pagesAction Research Improving Schools and Empowering Educators 5th Edition Mertler Test Bank Full Chapter PDFnoxiousslop18uus100% (12)
- Averaging Wind Speeds and DirectionsDocument13 pagesAveraging Wind Speeds and DirectionsHamish LaingNo ratings yet
- Statistics - Methods of Describing Sets of DataDocument12 pagesStatistics - Methods of Describing Sets of DataAshraf AminNo ratings yet
- CSP Unit 7 Lesson 3 Ramen RadarDocument4 pagesCSP Unit 7 Lesson 3 Ramen Radarabdelrahmanadelm2008No ratings yet
- One Sample TDocument4 pagesOne Sample TMarven LaudeNo ratings yet