33% found this document useful (3 votes)
3K views12 pagesWine Quality Analysis Project Report
its a machine learning project report, it has classification algorithms like knn, naive bayes and random forest
Uploaded by
Karishma KurickalCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
33% found this document useful (3 votes)
3K views12 pagesWine Quality Analysis Project Report
its a machine learning project report, it has classification algorithms like knn, naive bayes and random forest
Uploaded by
Karishma KurickalCopyright
© © All Rights Reserved
We take content rights seriously. If you suspect this is your content, claim it here.
Available Formats
Download as DOCX, PDF, TXT or read online on Scribd
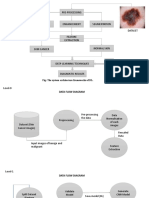
- Introduction
- Implementation
- Conclusion
- Results and Discussion
- References