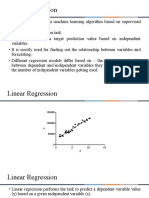
You might also like
- Python Quick GuideDocument27 pagesPython Quick GuideGonzoNo ratings yet
- 1694600777-Unit2.2 Logistic Regression CU 2.0Document37 pages1694600777-Unit2.2 Logistic Regression CU 2.0prime9316586191100% (1)
- Machine Learning NotesDocument19 pagesMachine Learning NotesAbir BaidyaNo ratings yet
- Logistic RegressionDocument12 pagesLogistic Regressionomar mohsenNo ratings yet
- A Gentle Introduction To Logistic RegressionDocument12 pagesA Gentle Introduction To Logistic RegressionamitkrayNo ratings yet
- Machine Learning (Analytics Vidhya) : What Is Logistic Regression?Document5 pagesMachine Learning (Analytics Vidhya) : What Is Logistic Regression?pradeep100% (1)
- Logistic RegressionDocument16 pagesLogistic RegressionBhakti BetageriNo ratings yet
- Module 3.3 Classification Models, An OverviewDocument11 pagesModule 3.3 Classification Models, An OverviewDuane Eugenio AniNo ratings yet
- 03 A Logistic Regression 2018Document13 pages03 A Logistic Regression 2018Reham TarekNo ratings yet
- Report Logistic RegressionDocument21 pagesReport Logistic Regressionimane bousslimeNo ratings yet
- Modelos - Sem15 - Logit - Probit - Logistic RegressionDocument8 pagesModelos - Sem15 - Logit - Probit - Logistic RegressionEmmanuelNo ratings yet
- Logistic+Regression - DoneDocument41 pagesLogistic+Regression - DonePinaki Ghosh100% (1)
- Unit IIDocument13 pagesUnit IImananrawat537100% (1)
- spss10 LOGITDocument17 pagesspss10 LOGITDebarati Das GuptaNo ratings yet
- Logistic Regression ReportDocument39 pagesLogistic Regression ReportCherry Mea BahoyNo ratings yet
- Logistic RegressionDocument32 pagesLogistic RegressionRaja100% (1)
- Samatrix Kaa KaamDocument3 pagesSamatrix Kaa KaamYash KumarNo ratings yet
- Exp2 MilfDocument7 pagesExp2 Milfojdsouza16No ratings yet
- Logistic RegressionDocument25 pagesLogistic RegressionSHRAVANI VISSAMSETTINo ratings yet
- Probit Model for Predicting AdmissionsDocument17 pagesProbit Model for Predicting AdmissionsNidhi KaushikNo ratings yet
- Multinomial Logistic Regression Models: Newsom Psy 525/625 Categorical Data Analysis, Spring 2021 1Document5 pagesMultinomial Logistic Regression Models: Newsom Psy 525/625 Categorical Data Analysis, Spring 2021 1Deo TuremeNo ratings yet
- Module3-Fitting A Model To DataDocument57 pagesModule3-Fitting A Model To DataGreen MongorNo ratings yet
- Logistic RegressionDocument25 pagesLogistic RegressiontsandrasanalNo ratings yet
- Logistic - Poly RegressionDocument13 pagesLogistic - Poly RegressionAmrin MulaniNo ratings yet
- 03 Logistic RegressionDocument23 pages03 Logistic RegressionHarold CostalesNo ratings yet
- Advice: sciences/business/economics/kit-baum-workshops/Bham13P4slides PDFDocument11 pagesAdvice: sciences/business/economics/kit-baum-workshops/Bham13P4slides PDFAhmad Bello DogarawaNo ratings yet
- Unit 7Document43 pagesUnit 7Yuvraj RanaNo ratings yet
- Logistic Regression For Machine Learning Complete TutorialUnderstand This Popular Supervised ClassifiDocument10 pagesLogistic Regression For Machine Learning Complete TutorialUnderstand This Popular Supervised ClassifiJuanito AlimañaNo ratings yet
- ML Mod 3Document4 pagesML Mod 3FREDRICK AMBROSENo ratings yet
- Logistic RegressionDocument13 pagesLogistic RegressionDakshNo ratings yet
- 5 ClassificationDocument72 pages5 Classificationsharad100% (1)
- Classification AlgorithmsDocument23 pagesClassification Algorithmsshyma na100% (1)
- ML Assignment3 SolutionDocument13 pagesML Assignment3 SolutionNeha GowdaNo ratings yet
- LogregDocument26 pagesLogregroy royNo ratings yet
- DSDocument2 pagesDSYash WaghNo ratings yet
- Logistic Regression Example IllustratedDocument20 pagesLogistic Regression Example IllustratedKEERTHANA V 20BCE1561No ratings yet
- Cost Function For Logistic RegressionDocument42 pagesCost Function For Logistic RegressionSwapnil BeraNo ratings yet
- Unit 2 - DSADocument15 pagesUnit 2 - DSARoshanaa RNo ratings yet
- Practical - Logistic RegressionDocument84 pagesPractical - Logistic Regressionwhitenegrogotchicks.619No ratings yet
- Logistic Regression IntermediateDocument5 pagesLogistic Regression IntermediateSrinidhi AdyaNo ratings yet
- What is Logistic RegressionDocument20 pagesWhat is Logistic RegressionSHRAVANI VISSAMSETTINo ratings yet
- Presentation (FA20 BCS 104)Document9 pagesPresentation (FA20 BCS 104)umair hasanNo ratings yet
- 2-Logistic RegressionDocument15 pages2-Logistic Regressionabdala sabryNo ratings yet
- ENCODING & Logistic RegressionDocument3 pagesENCODING & Logistic Regressionreshma acharyaNo ratings yet
- Everything You Need To Know About Linear RegressionDocument19 pagesEverything You Need To Know About Linear RegressionRohit Umbare100% (1)
- Module IV - Logistic RegressionDocument16 pagesModule IV - Logistic RegressionFMFMFMFmNo ratings yet
- ML Assignment 2: Tutorial: Linear Regression With Stochastic Gradient Descent - by Raimi Karim - Towards Data ScienceDocument3 pagesML Assignment 2: Tutorial: Linear Regression With Stochastic Gradient Descent - by Raimi Karim - Towards Data SciencesonuNo ratings yet
- Introduction To Logistic RegressionDocument20 pagesIntroduction To Logistic Regressionjaishree jainNo ratings yet
- Kill Your Data Science & ML Interview with Logistic RegressionDocument12 pagesKill Your Data Science & ML Interview with Logistic RegressionvenkatNo ratings yet
- UNIt-3 TYDocument67 pagesUNIt-3 TYPrathmesh Mane DeshmukhNo ratings yet
- Logistic Regression ExplainedDocument8 pagesLogistic Regression ExplainedRahul sharmaNo ratings yet
- Introduction To Logistic Regression: Implement Linear EquationDocument7 pagesIntroduction To Logistic Regression: Implement Linear EquationsudeepvmenonNo ratings yet
- Research Paper Logistic RegressionDocument7 pagesResearch Paper Logistic Regressionfvf2ffp6100% (1)
- Machine Learning AlgorithmDocument20 pagesMachine Learning AlgorithmSiva Gana100% (2)
- Bio2 Module 5 - Logistic RegressionDocument19 pagesBio2 Module 5 - Logistic Regressiontamirat hailuNo ratings yet
- UNIT4 CostFunctionsDocument23 pagesUNIT4 CostFunctionsJaya SankarNo ratings yet
- 新增 Microsoft Word DocumentDocument10 pages新增 Microsoft Word DocumentAlex MacNo ratings yet
- 2-Logistic RegressionDocument17 pages2-Logistic RegressionSafaa KahilNo ratings yet
- 7.logistics Regression - BDSM - Oct - 2020Document49 pages7.logistics Regression - BDSM - Oct - 2020rakeshNo ratings yet
- Lec1 PDFDocument56 pagesLec1 PDFAshish PadhyNo ratings yet
- Logistic RegressionDocument14 pagesLogistic RegressionYogesh RaiNo ratings yet
- NG N Bioethics4thedition 2014 GlobalJusticeDocument11 pagesNG N Bioethics4thedition 2014 GlobalJusticeAbir BaidyaNo ratings yet
- OSCE Report on Laws Affecting Religious CommunitiesDocument43 pagesOSCE Report on Laws Affecting Religious Communitiesfuad arifinNo ratings yet
- IPRL&PDocument265 pagesIPRL&PRomit Raja SrivastavaNo ratings yet
- 07 - Chapter - 3, PDFDocument75 pages07 - Chapter - 3, PDFAbir BaidyaNo ratings yet