You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5796)
- DBA Certification ShortDocument38 pagesDBA Certification ShortKarthi KeyaNo ratings yet
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Web Developer Interview Questions AnswersDocument27 pagesWeb Developer Interview Questions AnswersAbdul Samad Malik100% (1)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
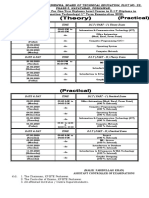
- DIT 1st Term Exam 2020 Date Sheet (Theory & Practical)Document1 pageDIT 1st Term Exam 2020 Date Sheet (Theory & Practical)Sana KhanNo ratings yet
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shell Test For Ball ValveDocument40 pagesShell Test For Ball Valvemohamadhakim.19789No ratings yet
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- What's New in DocuWare Version 7Document29 pagesWhat's New in DocuWare Version 7Mauricio CruzNo ratings yet
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Final Assignment: 1 InstructionsDocument5 pagesFinal Assignment: 1 InstructionsLanjun ShaoNo ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- 10E-5 Status Signals XLRTEH4300G033850Document1 page10E-5 Status Signals XLRTEH4300G033850Miller Andres ArocaNo ratings yet
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Business Strategy of MicrosoftDocument17 pagesBusiness Strategy of MicrosoftMustafa AhmedNo ratings yet
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- Jacob LeistenDocument1 pageJacob Leistenapi-542817921No ratings yet
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Exit Clearance Form: CompletedDocument1 pageExit Clearance Form: CompletedUjang BaniNo ratings yet
- MX6000 Pro LED Display Controller User Manual V1.1.1Document76 pagesMX6000 Pro LED Display Controller User Manual V1.1.1Erick RiveraNo ratings yet
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Unknown 2Document5 pagesUnknown 2Aqila HilaluddinNo ratings yet
- Module 3 NotesDocument27 pagesModule 3 NotesmNo ratings yet
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Terms and ConditionsDocument6 pagesTerms and ConditionsakanemelanieNo ratings yet
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- English Electricity Tariff 2024Document60 pagesEnglish Electricity Tariff 2024UNNI KUTTANNo ratings yet
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Mocur0508 IntroDocument27 pagesMocur0508 Introapi-516943376No ratings yet
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Linux: 1. Naloga - Mape in DatotekeDocument14 pagesLinux: 1. Naloga - Mape in DatotekeAnonymous 9K7CnytNo ratings yet
- Detection of Driving Fatigue Based On Grip Force On Steering Wheel With Wavelet Transformation and Support Vector MachineDocument2 pagesDetection of Driving Fatigue Based On Grip Force On Steering Wheel With Wavelet Transformation and Support Vector MachinePirvuNo ratings yet
- 8 Node Js Challenges in ImplementationDocument13 pages8 Node Js Challenges in ImplementationGamalliel SharonNo ratings yet
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- 02 Maintenance Strategies PDFDocument35 pages02 Maintenance Strategies PDFIrfannurllah Shah100% (1)
- How To Use EasyditaDocument12 pagesHow To Use Easyditaapi-529798489No ratings yet
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- VMware KB - Changing A Monolithic Disk To A Split Disk in VMware WorkstationDocument2 pagesVMware KB - Changing A Monolithic Disk To A Split Disk in VMware WorkstationAnonymous 0wXXmp1No ratings yet
- BERT SlidesDocument62 pagesBERT Slidessshahid183No ratings yet
- MELNG XC-268L (ML9020814) 220V50Hz EOMDocument20 pagesMELNG XC-268L (ML9020814) 220V50Hz EOMRichard FernandezNo ratings yet
- Chapter 3 Technology and Operations ManagementDocument17 pagesChapter 3 Technology and Operations ManagementaassweNo ratings yet
- Project Management Proposa1lDocument7 pagesProject Management Proposa1lAbdalrahman AlgedNo ratings yet
- Player Tracking and Slot Accounting SystemsDocument14 pagesPlayer Tracking and Slot Accounting SystemsAngela BrownNo ratings yet
- GSM/GPRS Communication Module For AS220 and AS1440 Meter: Product ManualDocument36 pagesGSM/GPRS Communication Module For AS220 and AS1440 Meter: Product ManualCarmenDicuNo ratings yet
- Mapeh Vi ArtsDocument6 pagesMapeh Vi ArtsVALERIE Y. DIZONNo ratings yet
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- Currency Recognition System: A Final Project ReportDocument35 pagesCurrency Recognition System: A Final Project ReportAndreea ElenaNo ratings yet
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)