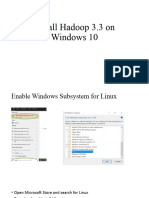
You might also like
- 2 - InstallationDocument15 pages2 - Installationboxbe9876No ratings yet
- Lab WRK On HadoopDocument17 pagesLab WRK On HadoopPallavi SharmaNo ratings yet
- Install SqoopDocument7 pagesInstall SqoopKajalNo ratings yet
- UntitledDocument7 pagesUntitledRavi Chandra ReddyNo ratings yet
- Installationof Hadoop 3Document6 pagesInstallationof Hadoop 3renaudNo ratings yet
- Install Hadoop in Pseudo and Fully Distributed ModesDocument50 pagesInstall Hadoop in Pseudo and Fully Distributed ModesMrunal BhilareNo ratings yet
- Yarn Tutorial PDFDocument30 pagesYarn Tutorial PDFvishnuNo ratings yet
- Hadoop Installation Manual 2.odtDocument20 pagesHadoop Installation Manual 2.odtGurasees SinghNo ratings yet
- Expt 1 - Hadoop InstallationDocument10 pagesExpt 1 - Hadoop InstallationNimesh NaikNo ratings yet
- Hadoop On WindowsDocument6 pagesHadoop On WindowsgeorgedavidcseNo ratings yet
- Hadoop 1Document39 pagesHadoop 1akshaydsarafNo ratings yet
- Hadoop Installation Step by StepDocument8 pagesHadoop Installation Step by StepRamkumar GopalNo ratings yet
- Hadoop Single Node Cluster Setup StepsDocument7 pagesHadoop Single Node Cluster Setup StepsShushrutha Reddy KNo ratings yet
- Hadoop 2.6.5 Installing On Ubuntu 16.04 and 18.04 (Single-Node Cluster)Document7 pagesHadoop 2.6.5 Installing On Ubuntu 16.04 and 18.04 (Single-Node Cluster)RAMI REDDYNo ratings yet
- Install Hadoop 2.8 on Windows 10Document9 pagesInstall Hadoop 2.8 on Windows 10Alvaro RivasNo ratings yet
- Big Data Manual AiDocument33 pagesBig Data Manual Aismitcse2021No ratings yet
- Hadoop Single Node Installation on UbuntuDocument8 pagesHadoop Single Node Installation on Ubuntumanish singhNo ratings yet
- BDA LAB ProgramsDocument56 pagesBDA LAB Programsraghu rama teja vegesnaNo ratings yet
- Lab 1Document12 pagesLab 1quyên nguyễnNo ratings yet
- SSH Hadoop Cluster on EC2Document5 pagesSSH Hadoop Cluster on EC2Vidhyasagar B S NaiduNo ratings yet
- Bda LabDocument47 pagesBda LabpawanNo ratings yet
- Step by Step Hadoop 2.8 InstallationDocument14 pagesStep by Step Hadoop 2.8 InstallationNazia GulNo ratings yet
- Unit No. 7Document45 pagesUnit No. 7vishal phuleNo ratings yet
- Tutorial Installasi Hadoop PDFDocument10 pagesTutorial Installasi Hadoop PDFErwin KurniawanNo ratings yet
- Tutorial Installasi Hadoop PDFDocument10 pagesTutorial Installasi Hadoop PDFErwin KurniawanNo ratings yet
- Hadoop Installation StepsDocument12 pagesHadoop Installation StepssangamNo ratings yet
- Hadoop Multi-Node InstallDocument4 pagesHadoop Multi-Node InstallJay LakshmiNo ratings yet
- Hadoop All InstallationsDocument19 pagesHadoop All InstallationsFernando Andrés Hinojosa VillarrealNo ratings yet
- OriginalDocument17 pagesOriginalYulia AnggianiNo ratings yet
- Hadoop InstallationDocument6 pagesHadoop InstallationPooja BanNo ratings yet
- There Are Two Ways To Install Hadoop in UbantuDocument10 pagesThere Are Two Ways To Install Hadoop in UbantuSrinivasa Rao TNo ratings yet
- Online:: Setting Up The EnvironmentDocument9 pagesOnline:: Setting Up The EnvironmentJanuari SagaNo ratings yet
- Hadoop Installation StepsDocument6 pagesHadoop Installation StepsYashi Shekhar100% (1)
- Install HadoopDocument17 pagesInstall HadoopAshwiniNo ratings yet
- Bda LabDocument37 pagesBda LabDhanush KumarNo ratings yet
- Hadoop Installation StepsDocument16 pagesHadoop Installation StepsSrinivasa Rao TNo ratings yet
- Install Hadoop Multi-NodeDocument2 pagesInstall Hadoop Multi-NodeaadifxNo ratings yet
- Hands On-ExerciesDocument17 pagesHands On-Exerciesapi-281821827No ratings yet
- Bda ManualDocument80 pagesBda Manualbhuvans80_mNo ratings yet
- BDAODocument23 pagesBDAOSujamoni 824No ratings yet
- Bda A1Document15 pagesBda A1Deepti AgrawalNo ratings yet
- BDA Lab Manual-1Document60 pagesBDA Lab Manual-1pavan chittalaNo ratings yet
- Hadoop Multi Node ClusterDocument7 pagesHadoop Multi Node Clusterchandu102103No ratings yet
- How To Install and Set Up A 3-Node Hadoop ClusterDocument36 pagesHow To Install and Set Up A 3-Node Hadoop ClusterFernovy GesnerNo ratings yet
- Hadoop/HBase Installation GuideDocument11 pagesHadoop/HBase Installation Guideshiva_1912-1No ratings yet
- Big Data FileDocument16 pagesBig Data FileArnav ShrivastavaNo ratings yet
- Setting-up HDFS ClusterDocument3 pagesSetting-up HDFS ClusterRoberto MartinezNo ratings yet
- Setup and Configure a 3-Node Hadoop ClusterDocument10 pagesSetup and Configure a 3-Node Hadoop ClusterPhạm Đức LongNo ratings yet
- Hadoop 2.6.0-Installation Guide-L-UpdatedDocument19 pagesHadoop 2.6.0-Installation Guide-L-UpdatedLavanyaNo ratings yet
- Lab 0-Cluster With Multiple VMs-30-01-2024Document6 pagesLab 0-Cluster With Multiple VMs-30-01-2024Rihane FarahNo ratings yet
- Hadoop TutorialDocument30 pagesHadoop TutorialHasanNo ratings yet
- Installation Process of HADOOPDocument12 pagesInstallation Process of HADOOPDaisy KawatraNo ratings yet
- Hadoop 2.7.3 Setup On Ubuntu 15.10Document7 pagesHadoop 2.7.3 Setup On Ubuntu 15.10BeschiAntonyDNo ratings yet
- Install and Configure Hadoop on Ubuntu in Pseudo-Distributed ModeDocument17 pagesInstall and Configure Hadoop on Ubuntu in Pseudo-Distributed ModeMIFTAHUL JANNAH SISTEM INFORMASI 2020No ratings yet
- Hadoop Installation StepsDocument4 pagesHadoop Installation StepsB49 Pravin TeliNo ratings yet
- HADOOP PPTDocument21 pagesHADOOP PPT[L]Akshat ModiNo ratings yet
- Install Single Node Hadoop ClusterDocument13 pagesInstall Single Node Hadoop ClusterTameem AhmedNo ratings yet
- Install Hadoop-2.6.0 On Windows10Document8 pagesInstall Hadoop-2.6.0 On Windows10Sana LatifNo ratings yet
- How to install Hadoop on Ubuntu 18.04Document15 pagesHow to install Hadoop on Ubuntu 18.04Koné Mikpan HervéNo ratings yet
- Quick Configuration of Openldap and Kerberos In Linux and Authenicating Linux to Active DirectoryFrom EverandQuick Configuration of Openldap and Kerberos In Linux and Authenicating Linux to Active DirectoryNo ratings yet
- Raju Chinthapatla: Oracle Applications 11i Order To Cash (O2C) Implementation StepsDocument12 pagesRaju Chinthapatla: Oracle Applications 11i Order To Cash (O2C) Implementation Stepssuj pNo ratings yet
- Example Oracle Forms 6i Training - SLIDESDocument7 pagesExample Oracle Forms 6i Training - SLIDESsuj pNo ratings yet
- YARN Installation PDFDocument7 pagesYARN Installation PDFsuj pNo ratings yet
- Inv Basic SetupsDocument1 pageInv Basic Setupssuj pNo ratings yet
- Tally FundamentalsDocument3 pagesTally FundamentalsInformation Point KapurthalaNo ratings yet
- LockboxprocessDocument19 pagesLockboxprocesssuj pNo ratings yet
- Rectifying Lockbox Errors PDFDocument7 pagesRectifying Lockbox Errors PDFsuj pNo ratings yet
- Rectifyinglc Errors PDFDocument7 pagesRectifyinglc Errors PDFsuj pNo ratings yet
- DFF Registration in AppsDocument4 pagesDFF Registration in Appssuj pNo ratings yet
- Implementing LockboxDocument31 pagesImplementing Lockboxespee29No ratings yet
- Visual Foxpro ErrorsDocument18 pagesVisual Foxpro ErrorsLucianGhNo ratings yet
- Advantages of the database approachDocument13 pagesAdvantages of the database approachAhmad Hussain Shafi SE-3rdNo ratings yet
- PICmicro MCU C - An Introduction To Programming The Microchip PIC in CCS CDocument135 pagesPICmicro MCU C - An Introduction To Programming The Microchip PIC in CCS Cvaibhav6820100% (34)
- 3 Intermediate Code GenerationDocument20 pages3 Intermediate Code GenerationAKASH PALNo ratings yet
- It8076 Software TestingDocument2 pagesIt8076 Software Testingdassdass22No ratings yet
- Srikanth Gottimukkula Professional SummaryDocument3 pagesSrikanth Gottimukkula Professional SummaryVrahtaNo ratings yet
- Web Deploy From Visual Studio 2012 To A Remote IIS 8 ServerDocument5 pagesWeb Deploy From Visual Studio 2012 To A Remote IIS 8 ServermajeedsterNo ratings yet
- IT 205 Chapter 1: Introduction to Integrative Programming and TechnologiesDocument42 pagesIT 205 Chapter 1: Introduction to Integrative Programming and TechnologiesAaron Jude Pael100% (2)
- Writing Effective Use CasesDocument8 pagesWriting Effective Use CasesAn Mwangi100% (1)
- RAR (File Format)Document5 pagesRAR (File Format)xerosNo ratings yet
- SPSS Sop7Document2 pagesSPSS Sop7agnesNo ratings yet
- Unit-6 Concurrent and Parallel Programming:: C++ AMP (Accelerated Massive Programming)Document21 pagesUnit-6 Concurrent and Parallel Programming:: C++ AMP (Accelerated Massive Programming)Sandhya GubbalaNo ratings yet
- FALLSEM2021-22 SWE1004 ELA VL2021220100875 Reference Material I 02-Aug-2021 SQL STATEMENTSDocument15 pagesFALLSEM2021-22 SWE1004 ELA VL2021220100875 Reference Material I 02-Aug-2021 SQL STATEMENTSPal BootsNo ratings yet
- Installation of WagTailDocument10 pagesInstallation of WagTailmuhadmrNo ratings yet
- IT Companies List - Geeth 13112021Document21 pagesIT Companies List - Geeth 13112021mohan kumarNo ratings yet
- PART1-MPP NotesDocument37 pagesPART1-MPP Notesapi-3746151No ratings yet
- Linkers and Libraries GuideDocument344 pagesLinkers and Libraries GuidePawełGolińskiNo ratings yet
- Collections in JavaDocument4 pagesCollections in JavaUmashankarNo ratings yet
- InDesign CS5.5 IDML ReadMeDocument6 pagesInDesign CS5.5 IDML ReadMeJesse YangNo ratings yet
- NRU Observability Presenter Deck TDDocument99 pagesNRU Observability Presenter Deck TDalok singhNo ratings yet
- Reversal of Open Items - New - DocumentDocument8 pagesReversal of Open Items - New - DocumentShruti IyerNo ratings yet
- hw4 MongodbDocument5 pageshw4 Mongodbapi-526395450No ratings yet
- Linux Installation Guide - JASP - Free and User-Friendly Statistical SoftwareDocument5 pagesLinux Installation Guide - JASP - Free and User-Friendly Statistical SoftwareIyo Barracuda MsdcNo ratings yet
- ProjectName Test Strategy DocumentDocument11 pagesProjectName Test Strategy DocumentVishakha NaiduNo ratings yet
- VMware vSphere 6 torrentDocument3 pagesVMware vSphere 6 torrentmulikvishalNo ratings yet
- Acabi OracleDocument257 pagesAcabi OracleSgsi ClassroomRobotNo ratings yet
- Web Tech Lab Manual NetDocument49 pagesWeb Tech Lab Manual Netomprakkash1509100% (1)
- A Better Way of Sending Break MessagesDocument10 pagesA Better Way of Sending Break MessagesblackwolfNo ratings yet
- Student Result Management System Project ReportDocument47 pagesStudent Result Management System Project ReportAppuzz VfcNo ratings yet
- Assembler (PC Underground)Document548 pagesAssembler (PC Underground)api-3746617No ratings yet