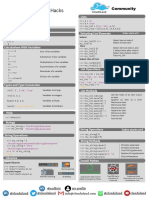
You might also like
- Pyspark Vs Pandas CheatsheetDocument3 pagesPyspark Vs Pandas Cheatsheetapi-261489892No ratings yet
- Python Cheat Sheet 2.0Document10 pagesPython Cheat Sheet 2.0Dario Camargo100% (1)
- Python The Inventory ProjectDocument52 pagesPython The Inventory ProjectPrajith SprinťèřNo ratings yet
- RedBooks-InfoSphere DataStage For Enterprise XML Data Integration PDFDocument404 pagesRedBooks-InfoSphere DataStage For Enterprise XML Data Integration PDFRicardo Zonta Santos100% (1)
- EDA Cheat Sheet - Exploratory Data AnalysisDocument2 pagesEDA Cheat Sheet - Exploratory Data AnalysisVanshika RastogiNo ratings yet
- Pandas: Reference SheetDocument9 pagesPandas: Reference SheetdeveshagNo ratings yet
- Data Handing Using Pandas-IDocument46 pagesData Handing Using Pandas-IPriyanka Porwal JainNo ratings yet
- Pandas Cheat Sheet PDFDocument1 pagePandas Cheat Sheet PDFmoraleseconomia50% (2)
- Pandas Cheat SheetDocument6 pagesPandas Cheat Sheetshan halder100% (2)
- Data Science Cheat Sheet: KEY ImportsDocument1 pageData Science Cheat Sheet: KEY ImportsMihai Dragomir100% (1)
- Pandas: ImportDocument13 pagesPandas: Importhello100% (1)
- Python: Backend Roadmap Till Language SelectionDocument1 pagePython: Backend Roadmap Till Language SelectionPeterlogeNo ratings yet
- Final Cheat Sheet TemplateDocument3 pagesFinal Cheat Sheet TemplateCloudnLoud TechnologiesNo ratings yet
- Python ML BookDocument211 pagesPython ML BookLeo PackNo ratings yet
- Class XII (As Per CBSE Board) : Informatics PracticesDocument43 pagesClass XII (As Per CBSE Board) : Informatics PracticesAnushya RavikumarNo ratings yet
- CheatSheet Python 10 Machine Learning SVMDocument1 pageCheatSheet Python 10 Machine Learning SVMSATYAJEET SARFARE (Alumni)No ratings yet
- Data Science With Python 1620448217Document4 pagesData Science With Python 1620448217Kavin Karthikeyan100% (1)
- Python Regular Expressions Quick ReferenceDocument2 pagesPython Regular Expressions Quick ReferenceSaurav LamaNo ratings yet
- Acceleo User GuideDocument56 pagesAcceleo User GuiderrefusnikNo ratings yet
- International Indian School, Riyadh WORKSHEET (2020-2021) Grade - Xii - Informatics Practices - Second TermDocument9 pagesInternational Indian School, Riyadh WORKSHEET (2020-2021) Grade - Xii - Informatics Practices - Second Termsofia guptaNo ratings yet
- 14-Lesson Cloudera HiveDocument9 pages14-Lesson Cloudera Hiveadchy7No ratings yet
- Data Engineering & GCP Basic Services 2. Data Storage in GCP 3. Database Offering by GCP 4. Data Processing in GCP 5. ML/AI Offering in GCPDocument3 pagesData Engineering & GCP Basic Services 2. Data Storage in GCP 3. Database Offering by GCP 4. Data Processing in GCP 5. ML/AI Offering in GCPvenkat rajNo ratings yet
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif HasanNo ratings yet
- Jupyter Shortcuts PDFDocument7 pagesJupyter Shortcuts PDFdebadutta21No ratings yet
- API Reference - Scikit-Learn 0.19.2 DocumentationDocument21 pagesAPI Reference - Scikit-Learn 0.19.2 Documentation08mpe026No ratings yet
- R Cheat Sheet 3 PDFDocument2 pagesR Cheat Sheet 3 PDFapakuniNo ratings yet
- Pythonfree PDFDocument77 pagesPythonfree PDFRosca Cristina100% (1)
- Python Pandas CheatsheetyDocument7 pagesPython Pandas CheatsheetyMansi MaheshwariNo ratings yet
- PySpark SQL Cheat Sheet Python PDFDocument1 pagePySpark SQL Cheat Sheet Python PDFCamilo AvilaNo ratings yet
- Pandas VisualisationDocument27 pagesPandas VisualisationSabrine BENZARTINo ratings yet
- PythonGuide V1.2.9Document2 pagesPythonGuide V1.2.9Samir Al-Bayati100% (1)
- Cheat Sheet: Tableau-DesktopDocument1 pageCheat Sheet: Tableau-DesktopNitish YadavNo ratings yet
- RDD Programing 8Document28 pagesRDD Programing 8chandrasekhar yerragandhulaNo ratings yet
- 03 - SQL Server Data Types and FunctionsDocument37 pages03 - SQL Server Data Types and FunctionsChowdhury Golam KibriaNo ratings yet
- Essential Python LibrariesDocument41 pagesEssential Python LibrariesEkoms GamingNo ratings yet
- Python OOPDocument46 pagesPython OOPSanchit BalchandaniNo ratings yet
- 02 - Lecture Note - TensorFlow OpsDocument21 pages02 - Lecture Note - TensorFlow OpsRoberto PereiraNo ratings yet
- Advanced Bash ScriptingDocument31 pagesAdvanced Bash ScriptingSaich MusaichNo ratings yet
- Python Regex CheatsheetDocument1 pagePython Regex CheatsheetBarouja ParosNo ratings yet
- PySpark RDD Basics PDFDocument1 pagePySpark RDD Basics PDFCOCONo ratings yet
- Unit-03: Capturing, Preparing and Working With DataDocument41 pagesUnit-03: Capturing, Preparing and Working With DataMubaraka KundawalaNo ratings yet
- Data Exploration in Python PDFDocument1 pageData Exploration in Python PDFSadek BPNo ratings yet
- DSA Cheat SheetDocument24 pagesDSA Cheat SheetDebasish SenapatyNo ratings yet
- Python: Sample Interview QuestionsDocument4 pagesPython: Sample Interview Questionsmanisha DubeyNo ratings yet
- Django Deployment CheatsheetDocument1 pageDjango Deployment CheatsheetJosé CuevasNo ratings yet
- Python Data Science 101Document41 pagesPython Data Science 101consania100% (1)
- Top 9 Data Science AlgorithmsDocument152 pagesTop 9 Data Science AlgorithmsManjunath.RNo ratings yet
- 8 Best Python Cheat Sheets For Beginners and Intermediate LearnersDocument17 pages8 Best Python Cheat Sheets For Beginners and Intermediate LearnersMOHAN S100% (1)
- PandasDocument698 pagesPandasisuruovinNo ratings yet
- Python Date TimeDocument6 pagesPython Date TimeNataliaNo ratings yet
- Python Cheatsheets 1635792640Document9 pagesPython Cheatsheets 1635792640Mokhtar Alerte100% (1)
- Python Tutorial For Beginners in HindiDocument34 pagesPython Tutorial For Beginners in HindiSubhadeep Deb RoyNo ratings yet
- Cleaning Data With PySpark Chapter3Document25 pagesCleaning Data With PySpark Chapter3FgpeqwNo ratings yet
- Python 2 Python 3Document4 pagesPython 2 Python 3Shubham Sati100% (1)
- HDFS Exercises - BasicDocument5 pagesHDFS Exercises - BasicPrabhu KushwahaNo ratings yet
- PandasDocument5 pagesPandasSmart CrazyNo ratings yet
- Commands SQL, Python (BASICS)Document7 pagesCommands SQL, Python (BASICS)Kuldeep GangwarNo ratings yet
- Pandas CommandsDocument3 pagesPandas Commandsvijayagajula1359No ratings yet
- Data Science Basics CheatsheetDocument1 pageData Science Basics Cheatsheetacutotu67% (3)
- Imp DetailsDocument6 pagesImp DetailsJyotirmay SahuNo ratings yet
- PythonForDataScience PDFDocument1 pagePythonForDataScience PDFMaisarah Mohd PauziNo ratings yet
- NumPy, SciPy, Pandas, Quandl Cheat SheetDocument4 pagesNumPy, SciPy, Pandas, Quandl Cheat Sheetseanrwcrawford100% (3)
- Binance Research Latest Insights and Analytics (3.2019 5.2019)Document108 pagesBinance Research Latest Insights and Analytics (3.2019 5.2019)Nenad JanjicNo ratings yet
- Numpy Python Cheat Sheet PDFDocument1 pageNumpy Python Cheat Sheet PDFnyh rmoNo ratings yet
- Plotly Cheat SheetDocument2 pagesPlotly Cheat SheetkoolawaisNo ratings yet