
You might also like
- Data Management for Researchers: Organize, maintain and share your data for research successFrom EverandData Management for Researchers: Organize, maintain and share your data for research successNo ratings yet
- Pasquetto 2017Document9 pagesPasquetto 2017IHNo ratings yet
- Whose Data Do You Trust? Integrity Issues in The Preservation of Scientific DataDocument11 pagesWhose Data Do You Trust? Integrity Issues in The Preservation of Scientific DataCristina AntociNo ratings yet
- Schneider Et Al-2019-Methods in Ecology and EvolutionDocument14 pagesSchneider Et Al-2019-Methods in Ecology and Evolutiondavidcosmin186832No ratings yet
- BES Guide Data Management 2019Document40 pagesBES Guide Data Management 2019James RomaNo ratings yet
- The International Journal of Digital Curation: The Publication of Research Data: Researcher Attitudes and BehaviourDocument11 pagesThe International Journal of Digital Curation: The Publication of Research Data: Researcher Attitudes and BehaviourAaron GriffithsNo ratings yet
- Fundamentos de EpidemiologiaDocument3 pagesFundamentos de EpidemiologiavictorcborgesNo ratings yet
- Swanson ECIS2021 Final DEcourseDocument15 pagesSwanson ECIS2021 Final DEcourseTrang DongNo ratings yet
- What Do We Know About The Stewardship Gap?Document32 pagesWhat Do We Know About The Stewardship Gap?Ania PeNo ratings yet
- More Is Less: Signal Processing and The Data Deluge: SpecialsectionDocument4 pagesMore Is Less: Signal Processing and The Data Deluge: SpecialsectionGilbertNo ratings yet
- Geology Icws 2007Document8 pagesGeology Icws 2007Dragos PopescuNo ratings yet
- Data PublicationDocument4 pagesData PublicationrehabbedNo ratings yet
- Better Management Reduces Data Loss RiskDocument3 pagesBetter Management Reduces Data Loss RiskAparna GoliNo ratings yet
- Towards Data Science: Yangyong Zhu and Yun XiongDocument7 pagesTowards Data Science: Yangyong Zhu and Yun XiongSan Dinakar DheenaNo ratings yet
- Analysis of Big Data Technologies For Use in Agro-Environmental ScienceDocument11 pagesAnalysis of Big Data Technologies For Use in Agro-Environmental ScienceDxtr MedinaNo ratings yet
- Big Data MiningDocument6 pagesBig Data MiningAnupamShNo ratings yet
- Challenges and Opportunities in Coding The Commons: Problems, Procedures, and Potential Solutions in Large-N Comparative Case StudiesDocument27 pagesChallenges and Opportunities in Coding The Commons: Problems, Procedures, and Potential Solutions in Large-N Comparative Case StudiesAlan HartogNo ratings yet
- Data at Work: Supporting Sharing in Science and Engineering: Jeremy Birnholtz Matthew BietzDocument10 pagesData at Work: Supporting Sharing in Science and Engineering: Jeremy Birnholtz Matthew BietzdirtysockNo ratings yet
- Liu ISPRS Photo Rethinking Big DataDocument9 pagesLiu ISPRS Photo Rethinking Big DataMoazzma AsifNo ratings yet
- Reduce Reuse Research: Secondary Data IssuesDocument6 pagesReduce Reuse Research: Secondary Data IssuesJay PrasathNo ratings yet
- Big_Research_Information_in_Data_LakeDocument5 pagesBig_Research_Information_in_Data_Lakehelios1949No ratings yet
- 2021RDMandSharing AwarnessAttitudeBehaviourDocument15 pages2021RDMandSharing AwarnessAttitudeBehaviourLRC Acquisition DepartmentNo ratings yet
- Aitken Et Al 2018 - A Role For Data Richness Mapping in Exploration Decision MakingDocument13 pagesAitken Et Al 2018 - A Role For Data Richness Mapping in Exploration Decision MakingEsmeralda 'LermaNo ratings yet
- A Survey On Data FusionDocument26 pagesA Survey On Data FusionAbdurrahman WachidNo ratings yet
- Future of Genomic DataDocument3 pagesFuture of Genomic DataNachoNo ratings yet
- Introduction Data ManagementDocument12 pagesIntroduction Data ManagementGeofrey BasalirwaNo ratings yet
- IJDC - Peer-Reviewed PaperDocument19 pagesIJDC - Peer-Reviewed PaperAkshat DubeyNo ratings yet
- River Basin Information System Open EnvironmentalDocument20 pagesRiver Basin Information System Open EnvironmentalayoubNo ratings yet
- Data MiningDocument6 pagesData Miningthegreatwriters8No ratings yet
- DRISCOLL ET AL-2007-Merging Qualitative and Quantitative DataDocument11 pagesDRISCOLL ET AL-2007-Merging Qualitative and Quantitative DatageralddsackNo ratings yet
- 2022_Jurnal_Q1_PNA_How Do Information Flows Affect Impact From Environmental Research_An Analysis of a Science-policy NetworkDocument18 pages2022_Jurnal_Q1_PNA_How Do Information Flows Affect Impact From Environmental Research_An Analysis of a Science-policy Networkwijoyo.adi89No ratings yet
- IQ of The CrowdDocument41 pagesIQ of The CrowdsaxycbNo ratings yet
- Frma 08 1177903Document2 pagesFrma 08 1177903Aleksandar BogicevicNo ratings yet
- Gomez Et Al.2014.data Integration in The Era of OmicsDocument10 pagesGomez Et Al.2014.data Integration in The Era of OmicsLAURA SOFIA AVILA CANTORNo ratings yet
- 08-MBA-DATA ANALYTICS - Data Science and Business Analysis - Unit 1Document40 pages08-MBA-DATA ANALYTICS - Data Science and Business Analysis - Unit 1Aamir RezaNo ratings yet
- CoDa Preprint PPSDocument45 pagesCoDa Preprint PPSshaniasinha612No ratings yet
- 336QQML Journal 2014 Johnston Sept 619-626Document8 pages336QQML Journal 2014 Johnston Sept 619-626Sovin ChauhanNo ratings yet
- Kitchin yMcArlden, 2016Document10 pagesKitchin yMcArlden, 2016Celeste BoxNo ratings yet
- Datos Dinamicos HarvardDocument30 pagesDatos Dinamicos HarvardCesarEspindolaArellanoNo ratings yet
- Long Tail Data ReportDocument18 pagesLong Tail Data ReportaniricNo ratings yet
- Perspective Materials Informatics and Big Data ReaDocument11 pagesPerspective Materials Informatics and Big Data ReaSrToshiNo ratings yet
- Texto 1 InglesDocument2 pagesTexto 1 InglesMariana Zuluaga TabaresNo ratings yet
- Big Data Quality Issues and SolutionsDocument22 pagesBig Data Quality Issues and SolutionsHassan SiddiquiNo ratings yet
- Introduction To Data Models Special Collection: Nicholas M. Weber and Karen M. WickettDocument3 pagesIntroduction To Data Models Special Collection: Nicholas M. Weber and Karen M. WickettRijal RojaliNo ratings yet
- Large-Scale Reasoning SurveyDocument53 pagesLarge-Scale Reasoning SurveyXiaolin ChengNo ratings yet
- MILLERAND & BOWKER - Metadata Standards. Trajectories and Enactment in The Life of An OntologyDocument17 pagesMILLERAND & BOWKER - Metadata Standards. Trajectories and Enactment in The Life of An OntologyCecilia SindonaNo ratings yet
- Andreotta 2019Document16 pagesAndreotta 2019GustavoNo ratings yet
- What Could Possibly Go Wrong: The Impact of Poor Data ManagementDocument27 pagesWhat Could Possibly Go Wrong: The Impact of Poor Data ManagementLNo ratings yet
- 2017 - Computational Reproducibility in Archaeological Re - 1Document48 pages2017 - Computational Reproducibility in Archaeological Re - 1b3d.dharoharNo ratings yet
- Ethical Sharing and Reuse of Qualitative DataDocument18 pagesEthical Sharing and Reuse of Qualitative DataMARIA LOMBANANo ratings yet
- Big Data MetodsDocument23 pagesBig Data MetodsvfryhnNo ratings yet
- Methods Ecol Evol - 2017 - Gerstner - Will Your Paper Be Used in A Meta Analysis Make The Reach of Your Research BroaderDocument8 pagesMethods Ecol Evol - 2017 - Gerstner - Will Your Paper Be Used in A Meta Analysis Make The Reach of Your Research BroaderSalehNo ratings yet
- Data Science vs. Statistics: Two Cultures?Document22 pagesData Science vs. Statistics: Two Cultures?ميلاد نوروزي رهبرNo ratings yet
- The Rise of Big Data What Does It Mean For Education Technology and Media ResearchDocument5 pagesThe Rise of Big Data What Does It Mean For Education Technology and Media ResearchMarco RamirezNo ratings yet
- Clarke, 2018Document31 pagesClarke, 20181921 Kaushal MistryNo ratings yet
- An Integrated Conceptual Framework For SDI Research: Experiences From French Case StudiesDocument32 pagesAn Integrated Conceptual Framework For SDI Research: Experiences From French Case StudiesJanab GNo ratings yet
- A Data Warehouse Architecture For Clinical Data Warehousing: Tony R. Sahama and Peter R. CrollDocument6 pagesA Data Warehouse Architecture For Clinical Data Warehousing: Tony R. Sahama and Peter R. CrollIrna SenikaNo ratings yet
- The State of Assessing Data Stewardship Maturity - An OverviewDocument12 pagesThe State of Assessing Data Stewardship Maturity - An OverviewDaniel TrejoNo ratings yet
- Little Science Confronts The Data Deluge: Habitat Ecology, Embedded Sensor Networks, and Digital LibrariesDocument14 pagesLittle Science Confronts The Data Deluge: Habitat Ecology, Embedded Sensor Networks, and Digital LibrariesMihaela Barbulescu0% (1)
- The Limitations of Observation StudiesDocument5 pagesThe Limitations of Observation StudiesalbgomezNo ratings yet
- Interviews of Notable Statistics and Data Science EducatorsDocument3 pagesInterviews of Notable Statistics and Data Science EducatorsalbgomezNo ratings yet
- Principal Component Analysis 2016Document16 pagesPrincipal Component Analysis 2016Gustavo Andres Fuentes RodriguezNo ratings yet
- Student Success in A University First-Year Statistics Course Do Students Characteristics Affect Their Academic PerformanceDocument13 pagesStudent Success in A University First-Year Statistics Course Do Students Characteristics Affect Their Academic PerformancealbgomezNo ratings yet
- Teaching Statistical Inference Through A Conceptual Lens A Spin On Existing Methods With ExamplesDocument20 pagesTeaching Statistical Inference Through A Conceptual Lens A Spin On Existing Methods With ExamplesalbgomezNo ratings yet
- Teaching Statistics - 2024 - Saccenti - A Gentle Introduction To Principal Component Analysis Using Tea Pots DinosaursDocument15 pagesTeaching Statistics - 2024 - Saccenti - A Gentle Introduction To Principal Component Analysis Using Tea Pots DinosaursalbgomezNo ratings yet
- Teaching Statistics and Data Analysis With RDocument16 pagesTeaching Statistics and Data Analysis With RalbgomezNo ratings yet
- On The P-ValueDocument15 pagesOn The P-ValuealbgomezNo ratings yet
- GEOMETRIC MORPHOMETRICS A CardiniDocument17 pagesGEOMETRIC MORPHOMETRICS A CardinialbgomezNo ratings yet
- Discriminant Correspondence AnDocument10 pagesDiscriminant Correspondence AnalbgomezNo ratings yet
- Dual Scaling For The Analysis of Categorical DataDocument9 pagesDual Scaling For The Analysis of Categorical DataalbgomezNo ratings yet
- Thirty Years of Geometric Morphometrics: Achievements, Challenges, and The Ongoing Quest For Biological MeaningfulnessDocument30 pagesThirty Years of Geometric Morphometrics: Achievements, Challenges, and The Ongoing Quest For Biological MeaningfulnessalbgomezNo ratings yet
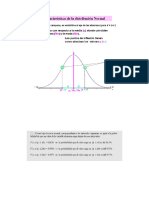
- Tabla Dist NormalDocument5 pagesTabla Dist NormalalbgomezNo ratings yet
- Sciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovalDocument7 pagesSciencedirect: Categorical Principal Component Logistic Regression: A Case Study For Housing Loan ApprovallaylaNo ratings yet
- The 3 One-Minute Daily Habits That'Ve Actually Saved Me Thousands of HoursDocument6 pagesThe 3 One-Minute Daily Habits That'Ve Actually Saved Me Thousands of HoursalbgomezNo ratings yet
- Civil Engineering Student Blog MexicoDocument948 pagesCivil Engineering Student Blog MexicoalbgomezNo ratings yet
- Principal Component AnalysisDocument27 pagesPrincipal Component AnalysisdsdamosNo ratings yet
- Agostinhoetal.2022 J Fish Biol. 2022 1-18.Document18 pagesAgostinhoetal.2022 J Fish Biol. 2022 1-18.albgomezNo ratings yet
- Variants of Simple Correspondence Analysis: Ontributed Esearch RticlesDocument18 pagesVariants of Simple Correspondence Analysis: Ontributed Esearch Rticlesjames ryerNo ratings yet
- Sherratt 2022 - ALOMETRIADocument7 pagesSherratt 2022 - ALOMETRIAalbgomezNo ratings yet
- The 3 One-Minute Daily Habits That'Ve Actually Saved Me Thousands of HoursDocument6 pagesThe 3 One-Minute Daily Habits That'Ve Actually Saved Me Thousands of HoursalbgomezNo ratings yet
- An Introduction To Correspondence AnalysisDocument23 pagesAn Introduction To Correspondence AnalysisalbgomezNo ratings yet
- An Introduction To Correspondence AnalysisDocument23 pagesAn Introduction To Correspondence AnalysisalbgomezNo ratings yet
- Multiple Factor Analysis OverviewDocument14 pagesMultiple Factor Analysis OverviewalbgomezNo ratings yet
- Multiple Factor Analysis Main FeaturesDocument26 pagesMultiple Factor Analysis Main FeaturesalbgomezNo ratings yet
- Multiple Factor Analysis OverviewDocument14 pagesMultiple Factor Analysis OverviewalbgomezNo ratings yet
- Ceramic Investigation How To Perform Statistical AnalysesDocument19 pagesCeramic Investigation How To Perform Statistical AnalysesalbgomezNo ratings yet
- R Studio Info For 272Document13 pagesR Studio Info For 272samrasamara2014No ratings yet
- V27i08 PDFDocument25 pagesV27i08 PDFalbgomezNo ratings yet
- Social Distancing Merely Stabilized COVID-19 in The United StatesDocument19 pagesSocial Distancing Merely Stabilized COVID-19 in The United StatesalbgomezNo ratings yet
- ORL Guidelines - Karger PublishersDocument20 pagesORL Guidelines - Karger PublishersAlexandraGuajánNo ratings yet
- Research Data Management by DR RC GaurDocument29 pagesResearch Data Management by DR RC Gaursudheer babu arumbakaNo ratings yet
- (PDF) 14 Websites To Download Research Paper For Free - 2022Document19 pages(PDF) 14 Websites To Download Research Paper For Free - 2022hatemaaNo ratings yet
- IJSME Instructions For Authors (7th APA) - 2021Document7 pagesIJSME Instructions For Authors (7th APA) - 2021sree vNo ratings yet
- Generalist Repository Comparison ChartDocument6 pagesGeneralist Repository Comparison ChartNikolasFlemotomosNo ratings yet
- 101 Free Online Journal and Research Databases For AcademicsDocument13 pages101 Free Online Journal and Research Databases For Academicsdj31No ratings yet
- The Top 21 Free Online Journal and Research DatabasesDocument2 pagesThe Top 21 Free Online Journal and Research DatabasessamNo ratings yet
- 101 Free Online Journal and Research Databases For Academics Free ResourceDocument13 pages101 Free Online Journal and Research Databases For Academics Free ResourceDIVEEJANo ratings yet
- Point of View: Syst. Biol. 69 (6) :1231-1253, 2020Document23 pagesPoint of View: Syst. Biol. 69 (6) :1231-1253, 2020arisNo ratings yet
- 101 Free Online Journal and Research Databases For Academics Free ResourceDocument13 pages101 Free Online Journal and Research Databases For Academics Free ResourceW CreativeNo ratings yet
- Find Free Online Journals & Research with 21 ResourcesDocument5 pagesFind Free Online Journals & Research with 21 ResourcesAsteria GojoNo ratings yet
- Dark Data: Why What You Don’t Know MattersFrom EverandDark Data: Why What You Don’t Know MattersRating: 4.5 out of 5 stars4.5/5 (3)
- Agile Metrics in Action: How to measure and improve team performanceFrom EverandAgile Metrics in Action: How to measure and improve team performanceNo ratings yet
- ITIL 4: Digital and IT strategy: Reference and study guideFrom EverandITIL 4: Digital and IT strategy: Reference and study guideRating: 5 out of 5 stars5/5 (1)
- Blockchain Basics: A Non-Technical Introduction in 25 StepsFrom EverandBlockchain Basics: A Non-Technical Introduction in 25 StepsRating: 4.5 out of 5 stars4.5/5 (24)
- Mastering PostgreSQL 12 - Third Edition: Advanced techniques to build and administer scalable and reliable PostgreSQL database applications, 3rd EditionFrom EverandMastering PostgreSQL 12 - Third Edition: Advanced techniques to build and administer scalable and reliable PostgreSQL database applications, 3rd EditionNo ratings yet
- Monitored: Business and Surveillance in a Time of Big DataFrom EverandMonitored: Business and Surveillance in a Time of Big DataRating: 4 out of 5 stars4/5 (1)
- SQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLFrom EverandSQL QuickStart Guide: The Simplified Beginner's Guide to Managing, Analyzing, and Manipulating Data With SQLRating: 4.5 out of 5 stars4.5/5 (46)
- IBM DB2 Administration Guide: Installation, Upgrade and Configuration of IBM DB2 on RHEL 8, Windows 10 and IBM Cloud (English Edition)From EverandIBM DB2 Administration Guide: Installation, Upgrade and Configuration of IBM DB2 on RHEL 8, Windows 10 and IBM Cloud (English Edition)No ratings yet
- Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]From EverandMicrosoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]Rating: 5 out of 5 stars5/5 (8)
- Business Intelligence Strategy and Big Data Analytics: A General Management PerspectiveFrom EverandBusiness Intelligence Strategy and Big Data Analytics: A General Management PerspectiveRating: 5 out of 5 stars5/5 (5)
- Joe Celko's SQL for Smarties: Advanced SQL ProgrammingFrom EverandJoe Celko's SQL for Smarties: Advanced SQL ProgrammingRating: 3 out of 5 stars3/5 (1)
- COBOL Basic Training Using VSAM, IMS and DB2From EverandCOBOL Basic Training Using VSAM, IMS and DB2Rating: 5 out of 5 stars5/5 (2)
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureFrom EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNo ratings yet



















































































































![Microsoft Access Guide to Success: From Fundamentals to Mastery in Crafting Databases, Optimizing Tasks, & Making Unparalleled Impressions [III EDITION]](https://imgv2-2-f.scribdassets.com/img/word_document/610686937/149x198/9ccfa6158e/1713743787?v=1)







