You might also like
- 2 Pointers To ReviewDocument8 pages2 Pointers To ReviewISAACNo ratings yet
- Minding the Machines: Building and Leading Data Science and Analytics TeamsFrom EverandMinding the Machines: Building and Leading Data Science and Analytics TeamsNo ratings yet
- Knowledge Management Processes and SystemsDocument24 pagesKnowledge Management Processes and SystemsmokeNo ratings yet
- Analytics in a Business Context: Practical guidance on establishing a fact-based cultureFrom EverandAnalytics in a Business Context: Practical guidance on establishing a fact-based cultureNo ratings yet
- Knowledge ManagementDocument22 pagesKnowledge ManagementP VNo ratings yet
- ON Knowledge ManagementDocument8 pagesON Knowledge ManagementNiyati SethNo ratings yet
- Building Knowledge in The WorkplaceDocument20 pagesBuilding Knowledge in The WorkplaceAcornNo ratings yet
- "Knowledge & Knowledge Management": © 2008 Maria JohnsenDocument8 pages"Knowledge & Knowledge Management": © 2008 Maria JohnsenMariaNo ratings yet
- Principles of Management: Knowledge Management Refers To A Range of Practices andDocument9 pagesPrinciples of Management: Knowledge Management Refers To A Range of Practices andDipesh KhandelwalNo ratings yet
- The Importance of Knowledge Management Management Essa1Document6 pagesThe Importance of Knowledge Management Management Essa1HND Assignment HelpNo ratings yet
- Knowledge ManagementDocument10 pagesKnowledge ManagementAi'nun NadzirahNo ratings yet
- What Is Knowledge Management, and Why Is It ImportantDocument8 pagesWhat Is Knowledge Management, and Why Is It ImportantBusoye SanniNo ratings yet
- Knowledge Management Thesis PDFDocument7 pagesKnowledge Management Thesis PDFjenniferalexanderfortlauderdale100% (2)
- Understanding Knowledge Management A Literature ReviewDocument6 pagesUnderstanding Knowledge Management A Literature ReviewsgfdsvbndNo ratings yet
- Knowledge ManagementDocument4 pagesKnowledge ManagementSurendaran SathiyanarayananNo ratings yet
- Knowledge and Information ManagementDocument7 pagesKnowledge and Information Managementhimanshu_ymca01No ratings yet
- Implementation of Knowledge Management in InfosysDocument8 pagesImplementation of Knowledge Management in InfosysTest mailNo ratings yet
- Knowlge MGMTDocument18 pagesKnowlge MGMTSumit SharmaNo ratings yet
- Assignment HRMDocument25 pagesAssignment HRMZobaer AhmedNo ratings yet
- Knowledge Management 1Document10 pagesKnowledge Management 1sid_didNo ratings yet
- Knowledge ManagementDocument26 pagesKnowledge ManagementSahar MetwallyNo ratings yet
- It For Managers Project - 1 Knowledge ManagementDocument21 pagesIt For Managers Project - 1 Knowledge ManagementAbhishek MajumdarNo ratings yet
- Knowledge Management LectureDocument7 pagesKnowledge Management LectureKay RiveroNo ratings yet
- Knowledge Management ProcessDocument27 pagesKnowledge Management ProcessAakashvashistha100% (1)
- Information Management and Knowledge Culture in The Legal Profession - Masterclass ArticleDocument7 pagesInformation Management and Knowledge Culture in The Legal Profession - Masterclass ArticleArk GroupNo ratings yet
- Literature Review of Knowledge Management SystemDocument7 pagesLiterature Review of Knowledge Management SystemaflsmperkNo ratings yet
- Knowledge ManagementDocument17 pagesKnowledge ManagementRajaRajeswari.L50% (2)
- KM (Unit 1)Document22 pagesKM (Unit 1)Pooja R AakulwadNo ratings yet
- Banking Management Online ModelDocument5 pagesBanking Management Online ModelNIET Journal of Engineering & Technology(NIETJET)No ratings yet
- PSPA 3204 - Knowledge Management and ICT For PA - IntroductionDocument19 pagesPSPA 3204 - Knowledge Management and ICT For PA - IntroductionRichard JonsonNo ratings yet
- Knowledge Management LectureDocument6 pagesKnowledge Management LectureKay RiveroNo ratings yet
- Name:-Saniya Kazi Roll No: - 21 Subject: - Knowledge Management Assignment: - No:02 Topic: - Introduction To Knowledge ManagementDocument9 pagesName:-Saniya Kazi Roll No: - 21 Subject: - Knowledge Management Assignment: - No:02 Topic: - Introduction To Knowledge ManagementSaniya KaziNo ratings yet
- Assignment For Knowledge ManagementDocument10 pagesAssignment For Knowledge Managementfahad BataviaNo ratings yet
- Assessment Task 2: Executive SummaryDocument5 pagesAssessment Task 2: Executive SummaryPahn PanrutaiNo ratings yet
- Knowledge Management (KM)Document132 pagesKnowledge Management (KM)mokeNo ratings yet
- Knowledge Mangement. Batch 1Document48 pagesKnowledge Mangement. Batch 1Jayesh MartinNo ratings yet
- Knowledge MGMTDocument22 pagesKnowledge MGMTVishalini YoganathanNo ratings yet
- Knowledge Transfer Process ThesisDocument7 pagesKnowledge Transfer Process Thesisdenisemillerdesmoines100% (2)
- PHD Thesis in Knowledge Management PDFDocument6 pagesPHD Thesis in Knowledge Management PDFrebeccarogersbaltimore100% (2)
- CHK-166 Knowledge ManagementDocument6 pagesCHK-166 Knowledge ManagementSofiya BayraktarovaNo ratings yet
- PSPMGT012 Facilitate Knowledge Management Written Knowledge Questions: Briefly Reflect On The Following Public Sector LegislationDocument11 pagesPSPMGT012 Facilitate Knowledge Management Written Knowledge Questions: Briefly Reflect On The Following Public Sector LegislationShahwarNo ratings yet
- HASSANALI - Critical Success Factors of Knowledge ManagementDocument4 pagesHASSANALI - Critical Success Factors of Knowledge ManagementMaira Pinto Cauchioli RodriguesNo ratings yet
- Running Head: Topic In-Depth Analysis 1Document8 pagesRunning Head: Topic In-Depth Analysis 1Nirajan MahatoNo ratings yet
- HRM2Document9 pagesHRM2Mohammed AhmedNo ratings yet
- Building Knowledge CorporationsDocument7 pagesBuilding Knowledge Corporationspuneethsmg100% (1)
- Components of Knowledge ManagementDocument9 pagesComponents of Knowledge Managementakoprogram1No ratings yet
- Thesis On Knowledge ManagementDocument4 pagesThesis On Knowledge Managementijofwkiig100% (2)
- Characteristc N Scope of KM Print TKNDocument2 pagesCharacteristc N Scope of KM Print TKNShilpy Ravneet KaurNo ratings yet
- Types of Knowledge Management: 1. Push StrategyDocument6 pagesTypes of Knowledge Management: 1. Push StrategyddeekshitadharaniNo ratings yet
- Knowledge Management: DSC3213 Strategic Information SystemsDocument23 pagesKnowledge Management: DSC3213 Strategic Information SystemsjieminaNo ratings yet
- Knowledge Management Practices in Indian Information Technology CompaniesDocument14 pagesKnowledge Management Practices in Indian Information Technology CompaniesPiyush GuptaNo ratings yet
- Knowledge Management in Business Programs: Faiza JavaidDocument4 pagesKnowledge Management in Business Programs: Faiza JavaidFaiza JavaidNo ratings yet
- What Is Knowledge ManagementDocument6 pagesWhat Is Knowledge ManagementDwi AniNo ratings yet
- PSM Assignment Table of Contents and Executive SummaryDocument11 pagesPSM Assignment Table of Contents and Executive SummaryAdam Nadeem KhanNo ratings yet
- Research Paper On Impact of Information Technology On Human Resource ManagementDocument5 pagesResearch Paper On Impact of Information Technology On Human Resource ManagementruvojbbkfNo ratings yet
- KC 1 1.3, 1.4 Knowledge ManagementDocument5 pagesKC 1 1.3, 1.4 Knowledge Managementprincikanabar.officeNo ratings yet
- Knowledge CreationDocument6 pagesKnowledge CreationCatalina StoianNo ratings yet
- Department of Management Sciences, National University of Modern LanguagesDocument15 pagesDepartment of Management Sciences, National University of Modern LanguagesSheiryNo ratings yet
- Challenges and Strategies To Knowledge Management: Case Studies of Selected CompaniesDocument15 pagesChallenges and Strategies To Knowledge Management: Case Studies of Selected CompaniesFOUNDER- Grey But YoungNo ratings yet
- How To Introduce YourselfDocument9 pagesHow To Introduce YourselfAnkita Bhatia100% (5)
- Bata Case StudyDocument9 pagesBata Case StudyAnkita BhatiaNo ratings yet
- CSRDocument14 pagesCSRAnkita BhatiaNo ratings yet
- Assignment HRMDocument20 pagesAssignment HRMAnkita BhatiaNo ratings yet
- Demand ForecastingDocument13 pagesDemand ForecastingAnkita BhatiaNo ratings yet
- Operations Management: William J. StevensonDocument19 pagesOperations Management: William J. StevensonAnkita BhatiaNo ratings yet
- Assignment: (MT413) Knowledge ManagementDocument11 pagesAssignment: (MT413) Knowledge ManagementAnkita BhatiaNo ratings yet
- Department of Management Birla Institute of Technology, Mesra, Ranchi - 835215 (India)Document227 pagesDepartment of Management Birla Institute of Technology, Mesra, Ranchi - 835215 (India)MohitAhujaNo ratings yet
- A Seminar On Cloud ComputingDocument23 pagesA Seminar On Cloud ComputinglarabataNo ratings yet
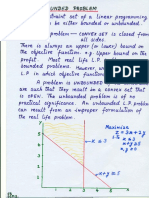
- Unbounded ProblemDocument2 pagesUnbounded ProblemAnkita BhatiaNo ratings yet
- LIQUIDATION STRATEGY Case StudyDocument10 pagesLIQUIDATION STRATEGY Case StudyAnkita BhatiaNo ratings yet
- MarketingDocument1 pageMarketingAnkita BhatiaNo ratings yet
- Solicited LetterDocument1 pageSolicited LetterAnkita BhatiaNo ratings yet
- Harper's Bazaar-: Lower Parel (W) Mumbai-400013 Subject: Application For The Post of Marketing Manager Dear SirDocument1 pageHarper's Bazaar-: Lower Parel (W) Mumbai-400013 Subject: Application For The Post of Marketing Manager Dear SirAnkita BhatiaNo ratings yet
- Human Resource Information Systems and Strategic Workforce PlanningDocument18 pagesHuman Resource Information Systems and Strategic Workforce PlanningAnkita BhatiaNo ratings yet
- BayanMuna On The Decline of Linguistic and Cultural Traditions of The Indigenous Eskaya Tribe The Cultural Minority of The Island of BoholDocument3 pagesBayanMuna On The Decline of Linguistic and Cultural Traditions of The Indigenous Eskaya Tribe The Cultural Minority of The Island of BoholperezkellyNo ratings yet
- CHI 211 Intermediate Chinese I SyllabusDocument3 pagesCHI 211 Intermediate Chinese I SyllabusMariah Elizabeth KarrisNo ratings yet
- Challenges SupragsegmentalDocument22 pagesChallenges SupragsegmentalraulNo ratings yet
- Hull m3sp5Document30 pagesHull m3sp5Firstface LastbookNo ratings yet
- REVISED BLOOMS TAXONOMY-ppt-ADZ-050309Document48 pagesREVISED BLOOMS TAXONOMY-ppt-ADZ-050309Juhainie Candatu Anas100% (2)
- Delta To Wye and V.VDocument4 pagesDelta To Wye and V.VAiza CabolesNo ratings yet
- 12th INFORMATIC PRACTICES SET 1Document5 pages12th INFORMATIC PRACTICES SET 1ushavalsaNo ratings yet
- Adjectives + Prepositions: About / at / of / WithDocument3 pagesAdjectives + Prepositions: About / at / of / Withayb alhoceima100% (1)
- Narasimha SatakamDocument51 pagesNarasimha SatakamNaganath Sharma80% (5)
- National University of Science and Technology: Digital System Design (EE-421) Assignment #1Document23 pagesNational University of Science and Technology: Digital System Design (EE-421) Assignment #1Tariq UmarNo ratings yet
- Binder 1Document305 pagesBinder 1Md Ridwanul Haque ZawadNo ratings yet
- Basic 2 - Unit 4bDocument1 pageBasic 2 - Unit 4bBeatriz Mayda Sanca MorocharaNo ratings yet
- Action Plan in Reading Intervention For Struggling PupilsDocument2 pagesAction Plan in Reading Intervention For Struggling PupilsJollibee McDonaldsNo ratings yet
- 9 Living A Fruitful Life SIMBALAYDocument3 pages9 Living A Fruitful Life SIMBALAYSherlaine MendozaNo ratings yet
- Reading Questions 3 - Waiting For Godot 2020Document4 pagesReading Questions 3 - Waiting For Godot 2020Rocío Martínez HiguerasNo ratings yet
- Prayer Update Apr June 2023 1Document24 pagesPrayer Update Apr June 2023 1sunil CNo ratings yet
- Unit 1 - Exercises: A. Complete These Opinions With The Correct Forms of The Words GivenDocument2 pagesUnit 1 - Exercises: A. Complete These Opinions With The Correct Forms of The Words GivenAle GarciiaNo ratings yet
- The Knights Tale by Geoffrey ChaucerDocument2 pagesThe Knights Tale by Geoffrey Chaucerapi-222876920No ratings yet
- Value Proposition ModuleDocument22 pagesValue Proposition ModuleKhatylyn Madronero100% (1)
- MVC TutorialDocument166 pagesMVC Tutorialmanish srivastavaNo ratings yet
- DDDDDDDDocument7 pagesDDDDDDDrajNo ratings yet
- Final Exam Timetable and Portion - STD 5Document4 pagesFinal Exam Timetable and Portion - STD 5suvarna deshmukhNo ratings yet
- A Woman in Her PrimeDocument2 pagesA Woman in Her PrimeFola AdedejiNo ratings yet
- Generalized Wave Parameter For Rules Formulae: September 2016Document9 pagesGeneralized Wave Parameter For Rules Formulae: September 2016Youngkook KimNo ratings yet
- Artificial Intelligence High Technology PowerPoint TemplatesDocument48 pagesArtificial Intelligence High Technology PowerPoint TemplatesainnaayNo ratings yet
- DLL - English 4 - Q1 - W3Document4 pagesDLL - English 4 - Q1 - W3MA. KRISTINA VINUYANo ratings yet
- KAK English Year 1-6Document4 pagesKAK English Year 1-6Syazwani SeliNo ratings yet
- Anritsu QuiCCA SoftwareDocument8 pagesAnritsu QuiCCA SoftwareSEHATI TEKNOLOGINo ratings yet
- Shanghai Alumni Primary School Student CardDocument4 pagesShanghai Alumni Primary School Student CardMEI MEI CHONGNo ratings yet
- EMV v4.2 Book 3Document239 pagesEMV v4.2 Book 3systemcodingNo ratings yet
- A-level Biology Revision: Cheeky Revision ShortcutsFrom EverandA-level Biology Revision: Cheeky Revision ShortcutsRating: 5 out of 5 stars5/5 (5)
- An Introduction to the Periodic Table of Elements : Chemistry Textbook Grade 8 | Children's Chemistry BooksFrom EverandAn Introduction to the Periodic Table of Elements : Chemistry Textbook Grade 8 | Children's Chemistry BooksRating: 5 out of 5 stars5/5 (1)
- How to Teach Nature Journaling: Curiosity, Wonder, AttentionFrom EverandHow to Teach Nature Journaling: Curiosity, Wonder, AttentionRating: 4.5 out of 5 stars4.5/5 (3)
- Quantum Physics for Beginners: Simple Illustrated Guide to Discover with Practical Explanations the Paradoxes of the Life and Universe Reconsidering RealityFrom EverandQuantum Physics for Beginners: Simple Illustrated Guide to Discover with Practical Explanations the Paradoxes of the Life and Universe Reconsidering RealityRating: 2 out of 5 stars2/5 (1)
- A-Level Chemistry Revision: Cheeky Revision ShortcutsFrom EverandA-Level Chemistry Revision: Cheeky Revision ShortcutsRating: 4 out of 5 stars4/5 (5)
- The Periodic Table of Elements - Post-Transition Metals, Metalloids and Nonmetals | Children's Chemistry BookFrom EverandThe Periodic Table of Elements - Post-Transition Metals, Metalloids and Nonmetals | Children's Chemistry BookNo ratings yet
- Simple STEAM: 50+ Science Technology Engineering Art and Math Activities for Ages 3 to 6From EverandSimple STEAM: 50+ Science Technology Engineering Art and Math Activities for Ages 3 to 6No ratings yet
- How to Think Like a Lawyer--and Why: A Common-Sense Guide to Everyday DilemmasFrom EverandHow to Think Like a Lawyer--and Why: A Common-Sense Guide to Everyday DilemmasRating: 3 out of 5 stars3/5 (1)
- Stay Curious and Keep Exploring: 50 Amazing, Bubbly, and Creative Science Experiments to Do with the Whole FamilyFrom EverandStay Curious and Keep Exploring: 50 Amazing, Bubbly, and Creative Science Experiments to Do with the Whole FamilyNo ratings yet
- Lower Secondary Science Workbook: Stage 8From EverandLower Secondary Science Workbook: Stage 8Rating: 5 out of 5 stars5/5 (1)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- On Teaching Science: Principles and Strategies That Every Educator Should KnowFrom EverandOn Teaching Science: Principles and Strategies That Every Educator Should KnowRating: 4 out of 5 stars4/5 (2)
- GCSE Biology Revision: Cheeky Revision ShortcutsFrom EverandGCSE Biology Revision: Cheeky Revision ShortcutsRating: 4.5 out of 5 stars4.5/5 (2)
- Cool Science Experiments for Kids | Science and Nature for KidsFrom EverandCool Science Experiments for Kids | Science and Nature for KidsNo ratings yet
- Science Action Labs Science Fun: Activities to Encourage Students to Think and Solve ProblemsFrom EverandScience Action Labs Science Fun: Activities to Encourage Students to Think and Solve ProblemsNo ratings yet
- Nature-Based Learning for Young Children: Anytime, Anywhere, on Any BudgetFrom EverandNature-Based Learning for Young Children: Anytime, Anywhere, on Any BudgetRating: 5 out of 5 stars5/5 (1)
- Little Rocks & Small Minerals! | Rocks And Mineral Books for Kids | Children's Rocks & Minerals BooksFrom EverandLittle Rocks & Small Minerals! | Rocks And Mineral Books for Kids | Children's Rocks & Minerals BooksRating: 4 out of 5 stars4/5 (1)