You might also like
- Managing Multivendor Networks 06Document13 pagesManaging Multivendor Networks 06AwaisAdnanNo ratings yet
- Unit 1: Premendra Kumar Sahu Asst. ProfessorDocument38 pagesUnit 1: Premendra Kumar Sahu Asst. ProfessorPremendra SahuNo ratings yet
- Solution Manual For MIS 7th Edition Bidgoli 1305667573 9781305667570Document36 pagesSolution Manual For MIS 7th Edition Bidgoli 1305667573 9781305667570daviddennissicrnqpxfz100% (22)
- 1538 - CSC Week One Lecture NoteDocument15 pages1538 - CSC Week One Lecture NoteArun Kumar UpadhyayNo ratings yet
- Computer Networks Research Papers 2012Document5 pagesComputer Networks Research Papers 2012gvzwyd4n100% (1)
- Unit 1 Hand Out ItcDocument10 pagesUnit 1 Hand Out ItcMukhtaar CaseNo ratings yet
- DATACENTER-WPS OfficeDocument8 pagesDATACENTER-WPS Officefrederic canayNo ratings yet
- Database Management System: ProgramDocument9 pagesDatabase Management System: ProgramShannett WalcottNo ratings yet
- Face Recognization Based Car Security SystemDocument86 pagesFace Recognization Based Car Security Systemkartheekkumar2812No ratings yet
- 3252computer Cracker FinalDocument16 pages3252computer Cracker FinalArjun PeralasseryNo ratings yet
- EE120 Information Technology 1Document10 pagesEE120 Information Technology 1Maajith MarzookNo ratings yet
- Unit 1: Premendra Kumar Sahu Asst. ProfessorDocument46 pagesUnit 1: Premendra Kumar Sahu Asst. ProfessorPremendra SahuNo ratings yet
- Google File SystemDocument6 pagesGoogle File SystemVIVA-TECH IJRINo ratings yet
- MIS Mip FinalDocument7 pagesMIS Mip FinalsagarkhambhalyaNo ratings yet
- Proposed Answers Section A: Marking GuideDocument7 pagesProposed Answers Section A: Marking Guidetezom techeNo ratings yet
- RFS: Efficient and Flexible Remote File Access For Mpi-Io: Jonghyun Lee $ Xiaosong Mat5 Rajeev MarianneDocument12 pagesRFS: Efficient and Flexible Remote File Access For Mpi-Io: Jonghyun Lee $ Xiaosong Mat5 Rajeev MariannePercival Jacinto Leigh511No ratings yet
- USe of Sqlite On Embedded SystemsDocument4 pagesUSe of Sqlite On Embedded SystemsAruna RajanNo ratings yet
- University of Greenwich: Assignment Submission CoversheetDocument8 pagesUniversity of Greenwich: Assignment Submission CoversheetJanar RajaseheranNo ratings yet
- Thesis Topics Embedded SystemsDocument8 pagesThesis Topics Embedded Systemsglennabeitelspachersiouxfalls100% (2)
- Research Paper On Computer HardwareDocument5 pagesResearch Paper On Computer Hardwarec9spy2qz100% (1)
- Thesis Computer HardwareDocument8 pagesThesis Computer Hardwaremariestarsnorthlasvegas100% (2)
- On Comprehensive Project: BCA (Session 2010-2013)Document74 pagesOn Comprehensive Project: BCA (Session 2010-2013)Yadwinder SinghNo ratings yet
- CH 3 Management Info SystemsDocument3 pagesCH 3 Management Info SystemsMelissa Jean HintonNo ratings yet
- Computer Programming Lecture Notes PDFDocument134 pagesComputer Programming Lecture Notes PDFAnik DuttaNo ratings yet
- Lesson 1.3 TechnologyDocument7 pagesLesson 1.3 TechnologyJastine Managbanag DautilNo ratings yet
- A Walk in The Cloud:: Broadband Computing and CommunicationsDocument8 pagesA Walk in The Cloud:: Broadband Computing and CommunicationsaptureincNo ratings yet
- Sbec-Internet and It's ApplicationsDocument102 pagesSbec-Internet and It's ApplicationsNAGARAJ GNo ratings yet
- Short Questions Other BoardsDocument50 pagesShort Questions Other BoardsZaheer AhmedNo ratings yet
- Generation of Computer ': Rajiv Academy For Technology and Management, Mathura ONDocument26 pagesGeneration of Computer ': Rajiv Academy For Technology and Management, Mathura ONsouarvNo ratings yet
- Computer Hardware Literature ReviewDocument5 pagesComputer Hardware Literature Reviewtxklbzukg100% (1)
- EDM - Presentation - V4Document11 pagesEDM - Presentation - V4ITImagingNo ratings yet
- Multimedia Database (MMDB) Is A Collection of Related Multimedia Data. The MultimediaDocument3 pagesMultimedia Database (MMDB) Is A Collection of Related Multimedia Data. The MultimediaKevin BaladadNo ratings yet
- Computer Hardware Research Paper TopicsDocument7 pagesComputer Hardware Research Paper Topicscaq5s6ex100% (1)
- Csc4306 Net-Centric ComputingDocument5 pagesCsc4306 Net-Centric ComputingAli musa baffa100% (1)
- Computer Networking Research PapersDocument8 pagesComputer Networking Research Papersfyrqkxfq100% (1)
- Embedded Systems Thesis ReportDocument7 pagesEmbedded Systems Thesis Reportnadugnlkd100% (1)
- Think-Tank It-Training Nov 2 2014Document7 pagesThink-Tank It-Training Nov 2 2014Olabooye AyodejiNo ratings yet
- Assignment 1Document4 pagesAssignment 1Alexander QuemadaNo ratings yet
- Latest Research Papers On Embedded SystemsDocument6 pagesLatest Research Papers On Embedded Systemsfvg2xg5r100% (1)
- Data Center OverviewDocument8 pagesData Center OverviewMTU650100% (2)
- Research Paper On Embedded Operating SystemsDocument5 pagesResearch Paper On Embedded Operating Systemszeiqxsbnd100% (1)
- Product 112Document15 pagesProduct 112cementsaimNo ratings yet
- 1 - Final 503 NotesDocument7 pages1 - Final 503 NotesApril Rose SuarezNo ratings yet
- CAB - Data Processing File &recordsDocument19 pagesCAB - Data Processing File &recordsRohit MalhotraNo ratings yet
- Jithendran Segaran FOL3 AnswerscriptDocument4 pagesJithendran Segaran FOL3 AnswerscriptJTD xFREAKNo ratings yet
- 1 - IT - Systems-Intro RevisedDocument9 pages1 - IT - Systems-Intro RevisedJosh TorcedoNo ratings yet
- Self-Test QuestionsDocument14 pagesSelf-Test QuestionsMary Benedict AbraganNo ratings yet
- Networking Term Paper TopicsDocument4 pagesNetworking Term Paper Topicsafmzahfnjwhaat100% (1)
- Question 1: Differences Between System Software and Application SoftwareDocument5 pagesQuestion 1: Differences Between System Software and Application SoftwareDarlington ChikwashuNo ratings yet
- Lecture 1: IT Infrastructure: After Completing This Topic, You Will Be Able ToDocument21 pagesLecture 1: IT Infrastructure: After Completing This Topic, You Will Be Able ToGabby OperarioNo ratings yet
- IsrishDocument5 pagesIsrishAssefaTayachewNo ratings yet
- Mphil Thesis in Computer Science NetworkingDocument8 pagesMphil Thesis in Computer Science Networkingafknojbcf100% (3)
- A Multi-Model Edge Computing Offloading Framework For Deep Learning Application Based On Bayesian OptimizationDocument13 pagesA Multi-Model Edge Computing Offloading Framework For Deep Learning Application Based On Bayesian OptimizationAbdullah Mansour AlgashwiNo ratings yet
- 07 Office AutomationDocument17 pages07 Office AutomationNeo wayneNo ratings yet
- Open-Source Robotics and Process Control Cookbook: Designing and Building Robust, Dependable Real-time SystemsFrom EverandOpen-Source Robotics and Process Control Cookbook: Designing and Building Robust, Dependable Real-time SystemsRating: 3 out of 5 stars3/5 (1)
- Research Paper On Embedded Systems PDFDocument5 pagesResearch Paper On Embedded Systems PDFjrcrefvhf100% (1)
- 7 Layer Vs 5 LayerDocument4 pages7 Layer Vs 5 Layermariairah_duNo ratings yet
- Ict ModuleDocument26 pagesIct ModuleSai GuyoNo ratings yet
- Simmips A Mips System SimulatorDocument8 pagesSimmips A Mips System Simulatorpahia3118No ratings yet
- Evolution of Emacs Lisp: Stefan Monnier, Michael SperberDocument55 pagesEvolution of Emacs Lisp: Stefan Monnier, Michael Sperberpahia3118No ratings yet
- Fsharp CheatsheetDocument3 pagesFsharp CheatsheetOsmar HerreraNo ratings yet
- Os UnisysDocument23 pagesOs Unisyspahia3118No ratings yet
- Zseries800 TechIntro Feb02Document170 pagesZseries800 TechIntro Feb02pahia3118No ratings yet
- PIC16F Seminar PresentationDocument58 pagesPIC16F Seminar Presentationpahia3118No ratings yet
- Akiba KShortest 2015Document7 pagesAkiba KShortest 2015pahia3118No ratings yet
- Cells in Picolisp: Idea: @Tankf33Der Review: @regenaxer Revision: 24 June 2020 Cc0Document31 pagesCells in Picolisp: Idea: @Tankf33Der Review: @regenaxer Revision: 24 June 2020 Cc0pahia3118No ratings yet
- FsharpcheatsheetDocument7 pagesFsharpcheatsheettrevoureNo ratings yet
- P2 DataSheetDocument4 pagesP2 DataSheetpahia3118No ratings yet
- F# Cheat SheetDocument3 pagesF# Cheat SheetHowTo HackNo ratings yet
- Glorp TutorialDocument65 pagesGlorp Tutorialpahia3118No ratings yet
- Branch Cuts For Complex Elementary FunctionsDocument24 pagesBranch Cuts For Complex Elementary Functionspahia3118No ratings yet
- RM 2-0 PDFDocument284 pagesRM 2-0 PDFpahia3118No ratings yet
- PIC17C4XDocument241 pagesPIC17C4XhuvillamilNo ratings yet
- SML 97.psDocument33 pagesSML 97.pspahia3118No ratings yet
- New Features of Oo2c v2: Michael Van AckenDocument13 pagesNew Features of Oo2c v2: Michael Van Ackenpahia3118No ratings yet
- The Evolution of Effective B-Tree: Page Organization and Techniques: A Personal AccountDocument6 pagesThe Evolution of Effective B-Tree: Page Organization and Techniques: A Personal Accountpahia3118No ratings yet
- A Personal Computer For Children of All Ages Kay72a PDFDocument11 pagesA Personal Computer For Children of All Ages Kay72a PDFJuan Luis Chulilla CanoNo ratings yet
- Bericht Ihu3 0205 eDocument2 pagesBericht Ihu3 0205 epahia3118No ratings yet
- RTX4000Document3 pagesRTX4000pahia3118No ratings yet
- FIGnition User ManualDocument19 pagesFIGnition User Manualpahia3118No ratings yet
- Revised 7th Report On SchemeDocument88 pagesRevised 7th Report On Schemepahia3118No ratings yet
- Bottles 551Document3 pagesBottles 551pahia3118No ratings yet
- Mil STD 1750a - Notice 6Document1 pageMil STD 1750a - Notice 6pahia3118No ratings yet
- ContextsDocument2 pagesContextspahia3118No ratings yet
- Ericsson Openness in AXEDocument10 pagesEricsson Openness in AXEyahoo234422No ratings yet
- Ud923 Birrell Paper PDFDocument36 pagesUd923 Birrell Paper PDFBurtNo ratings yet
- 65 XXXDocument6 pages65 XXXpahia3118No ratings yet
- User Guide: Storage Executive Command Line InterfaceDocument51 pagesUser Guide: Storage Executive Command Line InterfaceTihamér CsertaNo ratings yet
- Shi Et Al. - 2023 - SFCGDroid Android Malware Detection Based On SensDocument10 pagesShi Et Al. - 2023 - SFCGDroid Android Malware Detection Based On Senstrinhhtk.5903No ratings yet
- Prayer For Thesis Final DefenseDocument8 pagesPrayer For Thesis Final Defenseashleydavisshreveport100% (2)
- 1 3) External Style Sheets Can Contain HTML Tags FalseDocument5 pages1 3) External Style Sheets Can Contain HTML Tags FalseAniKet BNo ratings yet
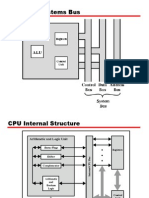
- CPU With Systems BusDocument35 pagesCPU With Systems BusTanafe33% (3)
- Web-Based Student Result Management System: October 2018Document21 pagesWeb-Based Student Result Management System: October 2018Tarzon Bagh Official100% (1)
- Ultra Low Power 32-Mbit Serial SPI Page EEPROM With Dual and Quad OutputsDocument70 pagesUltra Low Power 32-Mbit Serial SPI Page EEPROM With Dual and Quad OutputsJuanNo ratings yet
- 31 Famous Sharepoint URLs & LocationsDocument66 pages31 Famous Sharepoint URLs & LocationsBatmanNo ratings yet
- DSDPlusDocument11 pagesDSDPlusMariano Rubén JurczyszynNo ratings yet
- Mansions of Madness Second Edition - Investigator GuideDocument3 pagesMansions of Madness Second Edition - Investigator GuideDBGMax The WolfNo ratings yet
- Create Table SQLDocument2 pagesCreate Table SQLrockin034No ratings yet
- Ewb-E100 VPNDocument4 pagesEwb-E100 VPNAntonio CamposNo ratings yet
- Document Finder CustomizingDocument7 pagesDocument Finder CustomizingetiennehanfNo ratings yet
- Lab Manual: MCT-334L Industrial AutomationDocument38 pagesLab Manual: MCT-334L Industrial AutomationAhmed ChNo ratings yet
- LNMIIT Shines in Google Summer of Code 2014Document1 pageLNMIIT Shines in Google Summer of Code 2014Arpit KathuriaNo ratings yet
- Sentiment Analysys of Tweets Using Machine LearningDocument74 pagesSentiment Analysys of Tweets Using Machine LearningArNo ratings yet
- CS Project - Pranay KuhiteDocument13 pagesCS Project - Pranay KuhiteAryan KhandkaNo ratings yet
- Python MySQL Tutorial Using MySQL Connector Python (Complete Guide)Document6 pagesPython MySQL Tutorial Using MySQL Connector Python (Complete Guide)ahmedNo ratings yet
- Green Water Fix at Skyrim Nexus - Mods and Community PDFDocument4 pagesGreen Water Fix at Skyrim Nexus - Mods and Community PDFNikosIoannouNo ratings yet
- This Is A List of Tags That Will Be Replaced With Your InformationsDocument2 pagesThis Is A List of Tags That Will Be Replaced With Your InformationsJosé CarlosNo ratings yet
- CSE-111-04-Unit 3Document50 pagesCSE-111-04-Unit 3Yogi100% (1)
- Investigating Windows Systems Harlan Carvey Full ChapterDocument51 pagesInvestigating Windows Systems Harlan Carvey Full Chapterharriett.schmitke952100% (4)
- Strategy and Management Dissertation Handbook 2021 PTDocument26 pagesStrategy and Management Dissertation Handbook 2021 PTJohnathan AUNo ratings yet
- USER MANUAL InSite Pro MDocument96 pagesUSER MANUAL InSite Pro MDavid ZacariasNo ratings yet
- Cisco Switch Catalyst 6500 Series DatasheetDocument12 pagesCisco Switch Catalyst 6500 Series DatasheetDmitryNo ratings yet
- Introduction To Cryptography: Homework 4: Alvin Lin January 2018 - May 2018Document6 pagesIntroduction To Cryptography: Homework 4: Alvin Lin January 2018 - May 2018Nguyễn Quang MinhNo ratings yet
- Vulnerability Scanning StandardDocument7 pagesVulnerability Scanning StandardLayer8 IOTNo ratings yet
- Project 1Document11 pagesProject 1teferi GetachewNo ratings yet
- Backup AND Restore / Update Firmware: Doug WendykerDocument12 pagesBackup AND Restore / Update Firmware: Doug WendykerJahaziel Rubio GerardoNo ratings yet
- PROG3113 Part 2Document7 pagesPROG3113 Part 2GuideLinesNo ratings yet