You might also like
- Cloud-Based Blur and Illumination Invariant Object ClassificationDocument10 pagesCloud-Based Blur and Illumination Invariant Object ClassificationMuhammad Usman YaseenNo ratings yet
- A Practical Method For Measuring The Spatial Frequency Response of Light Field CamerasDocument5 pagesA Practical Method For Measuring The Spatial Frequency Response of Light Field CamerasYang YangNo ratings yet
- Practical SVBRDF Capture in The Frequency DomainDocument12 pagesPractical SVBRDF Capture in The Frequency DomainZStepan11No ratings yet
- 2005.00305v3 - Defocus Deblurring Using Dual-Pixel DataDocument27 pages2005.00305v3 - Defocus Deblurring Using Dual-Pixel DatageilsonNo ratings yet
- Fuchs 1994 VirtualDocument7 pagesFuchs 1994 VirtualFoton y JacNo ratings yet
- Chang Variable Aperture Light CVPR 2016 Paper PDFDocument9 pagesChang Variable Aperture Light CVPR 2016 Paper PDFWafa BenzaouiNo ratings yet
- Robust Dynamic Radiance FieldsDocument11 pagesRobust Dynamic Radiance FieldsDal TaylorNo ratings yet
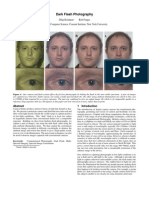
- Dark Flash Photography: F A R LDocument11 pagesDark Flash Photography: F A R LayreonautaNo ratings yet
- A Review On Video and Image Defogging Algorithms Image Restoration EnhancementDocument4 pagesA Review On Video and Image Defogging Algorithms Image Restoration EnhancementerpublicationNo ratings yet
- Gnerf: Gan-Based Neural Radiance Field Without Posed CameraDocument12 pagesGnerf: Gan-Based Neural Radiance Field Without Posed CameraZQQNo ratings yet
- Lee Iterative Filter Adaptive Network For Single Image Defocus Deblurring CVPR 2021 PaperDocument9 pagesLee Iterative Filter Adaptive Network For Single Image Defocus Deblurring CVPR 2021 PaperJunyong LeeNo ratings yet
- Fast Bilateral-Space Stereo For Synthetic DefocusDocument9 pagesFast Bilateral-Space Stereo For Synthetic Defocusyuheng weiNo ratings yet
- Range Security System For Vehicle Navigation: M. URA ofDocument6 pagesRange Security System For Vehicle Navigation: M. URA ofmkollamNo ratings yet
- Den Dere 2011Document4 pagesDen Dere 2011KEREN EVANGELINE I (RA1913011011002)No ratings yet
- SPIE - Design of Mobile Phone Lens With Extended Depth of Field Based On Point-Spread Function Focus InvarianceDocument11 pagesSPIE - Design of Mobile Phone Lens With Extended Depth of Field Based On Point-Spread Function Focus InvarianceChang MingNo ratings yet
- Green 2007Document8 pagesGreen 2007Ghazlan HishamNo ratings yet
- Software IntroductionDocument62 pagesSoftware Introductiong_31682896No ratings yet
- 3. 2020 - 04 - MẪU VIẾT BÁO CÁO THEO CHUẨN IEEEDocument6 pages3. 2020 - 04 - MẪU VIẾT BÁO CÁO THEO CHUẨN IEEEKhánh PhạmNo ratings yet
- 06.11.fast Software Image Stabilization With Color RegistrationDocument6 pages06.11.fast Software Image Stabilization With Color RegistrationAlessioNo ratings yet
- Defocus MagnificationDocument9 pagesDefocus MagnificationdefefalienNo ratings yet
- Depth Estimation From A Single Image Using Deep Learned Phase Coded MaskDocument12 pagesDepth Estimation From A Single Image Using Deep Learned Phase Coded MaskJ SpencerNo ratings yet
- Passive Depth Estimation Using Chromatic AberrationDocument13 pagesPassive Depth Estimation Using Chromatic Aberrationcynorr rainNo ratings yet
- Digital Signal Processing: Oh-Jin Kwon, Seungcheol Choi, Dukhyun Jang, Hee-Suk PangDocument11 pagesDigital Signal Processing: Oh-Jin Kwon, Seungcheol Choi, Dukhyun Jang, Hee-Suk PangWafa BenzaouiNo ratings yet
- Spatio-Angular Resolution Tradeoff in Integral PhotographyDocument10 pagesSpatio-Angular Resolution Tradeoff in Integral Photography劉永日樂No ratings yet
- S Patio Temporal Kernel RegressionDocument18 pagesS Patio Temporal Kernel Regressionsonalidhali157622No ratings yet
- Joint Image and Depth Estimation With Mask-Based Lensless CamerasDocument12 pagesJoint Image and Depth Estimation With Mask-Based Lensless CamerasJ SpencerNo ratings yet
- Deep Video DeblurringDocument10 pagesDeep Video DeblurringhhhNo ratings yet
- Li Lets See Clearly Contaminant Artifact Removal For Moving Cameras ICCV 2021 PaperDocument10 pagesLi Lets See Clearly Contaminant Artifact Removal For Moving Cameras ICCV 2021 PaperPS InnovationsNo ratings yet
- Advanced Renderer Cinema 4dDocument22 pagesAdvanced Renderer Cinema 4dbarakuparaNo ratings yet
- Abdullah Abuolaim Revisiting Autofocus For ECCV 2018 PaperDocument15 pagesAbdullah Abuolaim Revisiting Autofocus For ECCV 2018 PaperAnkit KumarNo ratings yet
- Nerf2Real: Sim2Real Transfer of Vision-Guided Bipedal Motion Skills Using Neural Radiance FieldsDocument12 pagesNerf2Real: Sim2Real Transfer of Vision-Guided Bipedal Motion Skills Using Neural Radiance Fields武怡No ratings yet
- Depth Camera Tehnology Comparison and EvaluationDocument7 pagesDepth Camera Tehnology Comparison and EvaluationDavidNo ratings yet
- 3D Shape Scanning With A Time-of-Flight CameraDocument8 pages3D Shape Scanning With A Time-of-Flight CameraDiego Bustos CervantesNo ratings yet
- On Computer Vision For Augmented RealityDocument4 pagesOn Computer Vision For Augmented RealityAditya IyerNo ratings yet
- Sensors 22 06923Document28 pagesSensors 22 06923jhvghvghjvgjhNo ratings yet
- IJETR031254Document4 pagesIJETR031254erpublicationNo ratings yet
- Brittan, Jones - 2019 - FWI Evolution - From A Monolith To A ToolkitDocument6 pagesBrittan, Jones - 2019 - FWI Evolution - From A Monolith To A ToolkitBSSNo ratings yet
- Tilde: A Temporally Invariant Learned Detector: (Yannick - Verdie, Kwang - Yi, Pascal - Fua) @epfl - CH, Lepetit@Icg - Tugraz.AtDocument10 pagesTilde: A Temporally Invariant Learned Detector: (Yannick - Verdie, Kwang - Yi, Pascal - Fua) @epfl - CH, Lepetit@Icg - Tugraz.AtSiva Jyothi ChandraNo ratings yet
- Removing Atmospheric Turbulence Via Space-Invariant Deconvolution PDFDocument14 pagesRemoving Atmospheric Turbulence Via Space-Invariant Deconvolution PDFagcarNo ratings yet
- Removing Motion Blur With SpaceTime ProcessingDocument11 pagesRemoving Motion Blur With SpaceTime ProcessingMarcoNo ratings yet
- Recent Advances in Space-Variant Deblurring and Image StabilizationDocument14 pagesRecent Advances in Space-Variant Deblurring and Image StabilizationKhan GiNo ratings yet
- Robust CVDDocument11 pagesRobust CVDqwertyNo ratings yet
- Engel Et Al Pami2018 PDFDocument17 pagesEngel Et Al Pami2018 PDFswagmanswagNo ratings yet
- REF 5 Lxy - IEEE-2010Document9 pagesREF 5 Lxy - IEEE-2010subhasaranya259No ratings yet
- ShaderX2 Real-TimeDepthOfFieldSimulationDocument30 pagesShaderX2 Real-TimeDepthOfFieldSimulationMateusz GralkaNo ratings yet
- Deblurring CVPR2021Document42 pagesDeblurring CVPR2021Junyong LeeNo ratings yet
- Hdrplus PreprintDocument12 pagesHdrplus PreprintBen KalziqiNo ratings yet
- An Integrated Image Motion Sensor For Micro CameraDocument7 pagesAn Integrated Image Motion Sensor For Micro CameraPons PlayNo ratings yet
- Efficient Hybrid Tree-Based Stereo Matching With Applications To Postcapture Image RefocusingDocument15 pagesEfficient Hybrid Tree-Based Stereo Matching With Applications To Postcapture Image RefocusingIsaac AnamanNo ratings yet
- CARATTERIZZAZIONE Nphoton.2015.279Document4 pagesCARATTERIZZAZIONE Nphoton.2015.279Claudio BiaginiNo ratings yet
- Hidden Camera Detection: Vaishali Koul, Rakshita Macheri, Ribhuvats, Liya Baby, Poonam BariDocument5 pagesHidden Camera Detection: Vaishali Koul, Rakshita Macheri, Ribhuvats, Liya Baby, Poonam Bariwaqar12No ratings yet
- Orbit CameraDocument29 pagesOrbit CameraKhatami OnikNo ratings yet
- Temporally Coherent General Dynamic Scene ReconstructionDocument19 pagesTemporally Coherent General Dynamic Scene ReconstructionJuan carlos Cuellar riveraNo ratings yet
- Two-Shot SVBRDF Capture For Stationary MaterialsDocument13 pagesTwo-Shot SVBRDF Capture For Stationary MaterialsZStepan11No ratings yet
- Deflectometry Based Android Application For Non-Destructive Testing of Different Optical ComponentsDocument11 pagesDeflectometry Based Android Application For Non-Destructive Testing of Different Optical ComponentsAmit ChatterjeeNo ratings yet
- Sum Modified Laplacian PDFDocument33 pagesSum Modified Laplacian PDFZagdsuren AsNo ratings yet
- Differences Between Fresnel and Fraunhofer Diffraction PatternsDocument5 pagesDifferences Between Fresnel and Fraunhofer Diffraction PatternsAndrea EspinosaNo ratings yet
- Design and Experimental Validation of A Wide Field of View Dual-Lens Antenna at Sub-Millimeter Wave FrequenciesDocument4 pagesDesign and Experimental Validation of A Wide Field of View Dual-Lens Antenna at Sub-Millimeter Wave FrequencieshosseinNo ratings yet
- Blind Motion Deblurring Using Multiple Images: A, B, A BDocument25 pagesBlind Motion Deblurring Using Multiple Images: A, B, A BBoraiah ParameswaraNo ratings yet
- Das - Driver Assistance System PDFDocument361 pagesDas - Driver Assistance System PDFAxx100% (2)
- Remotely Taking PhotographsDocument7 pagesRemotely Taking PhotographsAryo WicaksonoNo ratings yet
- Leica Nova Ms60 WHP LRDocument12 pagesLeica Nova Ms60 WHP LRMahmoud RajabiNo ratings yet
- Photo Technique 20120708Document60 pagesPhoto Technique 20120708Fratila CatalinNo ratings yet
- 400 Brochure Circuit Board Plotter Options Accessories enDocument4 pages400 Brochure Circuit Board Plotter Options Accessories enUlises Gordillo ZapanaNo ratings yet
- How To Shoot A Music VideoDocument9 pagesHow To Shoot A Music Videogaby yepesNo ratings yet
- Products Comparison NIKON Vs CANONDocument6 pagesProducts Comparison NIKON Vs CANONcomey_liezaNo ratings yet
- G0556Document72 pagesG0556lobosolitariobe100% (3)
- AAFT University Presents Communique Vol 02 Issue 01Document32 pagesAAFT University Presents Communique Vol 02 Issue 01Roopam ChandrakarNo ratings yet
- Manual DVR Elikon RT1608Document94 pagesManual DVR Elikon RT1608athorkNo ratings yet
- Sony DSR-300A ManualDocument12 pagesSony DSR-300A ManualChaitra ChAiNo ratings yet
- Reviewer BoardDocument17 pagesReviewer BoardTerrencio ReodavaNo ratings yet
- Course OutlineDocument11 pagesCourse OutlineIzzahImaniNo ratings yet
- 5545ddc0c36c77d2cb27aa6559bfab2cDocument2 pages5545ddc0c36c77d2cb27aa6559bfab2cWeber HahnNo ratings yet
- KHD 5000X ManualDocument2 pagesKHD 5000X ManualClaudel NgounouNo ratings yet
- Applsci 10 06945Document25 pagesApplsci 10 06945gurkanbasogluuNo ratings yet
- Review Notes in Police PhotographyDocument6 pagesReview Notes in Police PhotographyMelcon S. LapinaNo ratings yet
- PHOTOJOURNALISM LECTURE. Div - TrainingDocument78 pagesPHOTOJOURNALISM LECTURE. Div - TrainingCaloña Piañar Jinelyn100% (4)
- DH IPC HFW1431S1 S4 - Datasheet - 20201225Document3 pagesDH IPC HFW1431S1 S4 - Datasheet - 20201225carlo laguraNo ratings yet
- HUAWEI Nova Y61 User Guide - (EVE-LX3&LX9&LX9N, EMUI12.0 - 01, En-Us)Document56 pagesHUAWEI Nova Y61 User Guide - (EVE-LX3&LX9&LX9N, EMUI12.0 - 01, En-Us)Farhad H AbdullahNo ratings yet
- Digital Camera World - Complete Photography Guide - Mastering ExposureDocument48 pagesDigital Camera World - Complete Photography Guide - Mastering ExposurePepe Nojodan NojodanNo ratings yet
- Aesculap PV440 Camera System - User ManualDocument192 pagesAesculap PV440 Camera System - User Manualprzy3_14No ratings yet
- Automatic Number Plate RecognitionDocument16 pagesAutomatic Number Plate RecognitionVipin BaliyanNo ratings yet
- Brooke Shaden - Fine Art Compositing - Logic ChecklistDocument8 pagesBrooke Shaden - Fine Art Compositing - Logic ChecklistMarcos AntônioNo ratings yet
- Computer Hardware and SoftwareDocument105 pagesComputer Hardware and SoftwareAldrei TorresNo ratings yet
- LGS Product Specifications TerrainMapper LRDocument10 pagesLGS Product Specifications TerrainMapper LRAbhinandan PadhaNo ratings yet
- Review of Single-Camera Stereo-Digital Image Correlation Techniques For Full-Field 3D Shape and Deformation MeasurementDocument19 pagesReview of Single-Camera Stereo-Digital Image Correlation Techniques For Full-Field 3D Shape and Deformation Measurement'Jorge Garrido VargasNo ratings yet
- Mni Ision: Ov7950/Ov7451 Cmos Analog NTSC C C With Omnipixel TechnologyDocument31 pagesMni Ision: Ov7950/Ov7451 Cmos Analog NTSC C C With Omnipixel Technologymike chenNo ratings yet
- Samsung Plasma TV ManualDocument29 pagesSamsung Plasma TV ManualViquar AhmedhNo ratings yet
- Reference Manual IVC 2DDocument253 pagesReference Manual IVC 2DSergio Romano PadillaNo ratings yet