You might also like
- Standard and Super-Resolution Bioimaging Data Analysis: A PrimerFrom EverandStandard and Super-Resolution Bioimaging Data Analysis: A PrimerNo ratings yet
- Colour Face Recognition A Novel Recognition MethodDocument5 pagesColour Face Recognition A Novel Recognition MethodRamesh MallaiNo ratings yet
- Bai Multi-Scale Fully Convolutional CVPR 2017 PaperDocument10 pagesBai Multi-Scale Fully Convolutional CVPR 2017 PaperBOUMARAF IbtissamNo ratings yet
- Analysis of Facial Expression Using Gabor and SVM: Praseeda Lekshmi.V - , Dr.M.SasikumarDocument4 pagesAnalysis of Facial Expression Using Gabor and SVM: Praseeda Lekshmi.V - , Dr.M.SasikumarRahSamNo ratings yet
- Content Based Image Retrieval Using Feature CodingDocument4 pagesContent Based Image Retrieval Using Feature CodingInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Point Based Rendering Enhancement Via Deep Learning: December 16, 2018Document13 pagesPoint Based Rendering Enhancement Via Deep Learning: December 16, 2018ArmandoNo ratings yet
- A New Fast Skin Color Detection Technique Using Pixel Skipping and Image ResizingDocument5 pagesA New Fast Skin Color Detection Technique Using Pixel Skipping and Image Resizingxrang johnNo ratings yet
- Pattern Recognition Letters: Xiaohua Xia, Suping Fang, Yan XiaoDocument6 pagesPattern Recognition Letters: Xiaohua Xia, Suping Fang, Yan XiaoWafa BenzaouiNo ratings yet
- WCECS2008 pp1166-1171 2Document6 pagesWCECS2008 pp1166-1171 2PavanNo ratings yet
- Object-Based Image Enhancement Technique for Grayscale ImagesDocument15 pagesObject-Based Image Enhancement Technique for Grayscale ImagesBudi Utami FahnunNo ratings yet
- Performance Analysis of Ann Based Ycbcr Skin Detection AlgorithmDocument7 pagesPerformance Analysis of Ann Based Ycbcr Skin Detection AlgorithmshahadNo ratings yet
- cvpr10 Facereco PDFDocument8 pagescvpr10 Facereco PDFetyrtyrNo ratings yet
- Multi-Modal Human Verification Using Face and SpeechDocument6 pagesMulti-Modal Human Verification Using Face and SpeechIkram CheboutNo ratings yet
- Maier 2017 Intrinsic 3 DDocument14 pagesMaier 2017 Intrinsic 3 Damdj1No ratings yet
- Face Recognition Using Combined Multiscale Anisotropic and Texture Features Based On Sparse CodingDocument15 pagesFace Recognition Using Combined Multiscale Anisotropic and Texture Features Based On Sparse CodingVania V. EstrelaNo ratings yet
- Image Segmentation NO MLDocument24 pagesImage Segmentation NO MLdas.sandipan5102002No ratings yet
- Color Image Segmentation Using Vector Quantization TechniquesDocument7 pagesColor Image Segmentation Using Vector Quantization Techniqueshbkekre2378No ratings yet
- JournalPaper ASC UpdatedDocument16 pagesJournalPaper ASC UpdatedAdeeba AliNo ratings yet
- Performance Evaluation of Selected Feature Extraction Techniques in Digital Face Image ProcessingDocument9 pagesPerformance Evaluation of Selected Feature Extraction Techniques in Digital Face Image ProcessingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Artigo Pichai2017Document6 pagesArtigo Pichai2017Matheus AlborghettiNo ratings yet
- Face Palm PaperDocument11 pagesFace Palm PapervijetaNo ratings yet
- A Gender Recognition System From Facial ImageDocument10 pagesA Gender Recognition System From Facial Imageahtasham hussainNo ratings yet
- 3D Face Recognition Using Simulated Annealing and The Surface Interpenetration MeasureDocument14 pages3D Face Recognition Using Simulated Annealing and The Surface Interpenetration MeasureAneesha AzeezNo ratings yet
- Robust Face Recognition under Varying IlluminationDocument9 pagesRobust Face Recognition under Varying IlluminationAbdelhalim BouallegNo ratings yet
- Contour Detection and Hierarchical Image SegmentationDocument19 pagesContour Detection and Hierarchical Image SegmentationQuynhtrang NguyenNo ratings yet
- DCT Domain Face Recognition with Illumination Variance ReductionDocument7 pagesDCT Domain Face Recognition with Illumination Variance Reductionpioneerb64No ratings yet
- K-Nearest Neighbor Based Facial Emotion Recognition Using Effective FeaturesDocument9 pagesK-Nearest Neighbor Based Facial Emotion Recognition Using Effective FeaturesIAES IJAINo ratings yet
- Dissertation Proposal: Greg Coombe University of North Carolina August 22, 2005Document17 pagesDissertation Proposal: Greg Coombe University of North Carolina August 22, 2005LambertNo ratings yet
- A Fruit Recognition Technique Using Multiple Features and Artificial Neural NetworkDocument6 pagesA Fruit Recognition Technique Using Multiple Features and Artificial Neural NetworkEndalew SimieNo ratings yet
- Improving CBIR using wavelet-based feature extractionDocument8 pagesImproving CBIR using wavelet-based feature extractionCarolina WatanabeNo ratings yet
- Facial Expression Recognition by Fusing Gabor and Local Binary Pattern FeaturesDocument13 pagesFacial Expression Recognition by Fusing Gabor and Local Binary Pattern FeaturesAhadit ABNo ratings yet
- Plagiarism - ReportDocument11 pagesPlagiarism - ReportSanjay ShelarNo ratings yet
- Matlab PDFDocument12 pagesMatlab PDFNaveen Kumar RavillaNo ratings yet
- Reff29-A Gender Recognition System From Facial ImageDocument11 pagesReff29-A Gender Recognition System From Facial ImageJayaprada S. HiremathNo ratings yet
- A Novel Elimination-Based A Approach To Image RetrievalDocument6 pagesA Novel Elimination-Based A Approach To Image RetrievalPavan Kumar NsNo ratings yet
- Multimodality For Reliable Single Image Based Face Morphing Attack DetectionDocument16 pagesMultimodality For Reliable Single Image Based Face Morphing Attack DetectionSHARIFA KHATUN ANANYANo ratings yet
- A Skin Tone Detection Algorithm For An Adaptive Approach To SteganographyDocument23 pagesA Skin Tone Detection Algorithm For An Adaptive Approach To SteganographyLeela PavanNo ratings yet
- Devnagari Char Recognition PDFDocument4 pagesDevnagari Char Recognition PDFSaroj SahooNo ratings yet
- A New Approach For Face Image Enhancement and RecognitionDocument10 pagesA New Approach For Face Image Enhancement and RecognitionDinesh PudasainiNo ratings yet
- Signal Processing: Qiang Zhang, Li Zhuo, Jiafeng Li, Jing Zhang, Hui Zhang, Xiaoguang LiDocument8 pagesSignal Processing: Qiang Zhang, Li Zhuo, Jiafeng Li, Jing Zhang, Hui Zhang, Xiaoguang LiAlejo MorenoNo ratings yet
- Enhancement of Images Using Morphological Transformations: K.Sreedhar and B.PanlalDocument18 pagesEnhancement of Images Using Morphological Transformations: K.Sreedhar and B.PanlalRozita JackNo ratings yet
- Discriminant Analysis of The Two-Dimensional Gabor Features For Face RecognitionDocument13 pagesDiscriminant Analysis of The Two-Dimensional Gabor Features For Face RecognitionJoyce GeorgeNo ratings yet
- EdgeConnect Structure Guided Image Inpainting Using Edge PredictionDocument10 pagesEdgeConnect Structure Guided Image Inpainting Using Edge Predictiontthod37No ratings yet
- Face Recognition Via Local Directional PatternDocument10 pagesFace Recognition Via Local Directional PatternNeeraj KannaugiyaNo ratings yet
- Face Recognition Using Pca Lda and Various Distance Classifiers 30 35Document6 pagesFace Recognition Using Pca Lda and Various Distance Classifiers 30 35iwtm2005No ratings yet
- Paper 3Document6 pagesPaper 3Alejandro RodriguezNo ratings yet
- Journal Pre-ProofDocument41 pagesJournal Pre-ProofHARE KRISHNANo ratings yet
- DohoamaytinhDocument23 pagesDohoamaytinhngocvu7878No ratings yet
- 6e06 PDFDocument7 pages6e06 PDFviraj vastNo ratings yet
- Robust Face Verification Using Sparse RepresentationDocument7 pagesRobust Face Verification Using Sparse RepresentationSai Kumar YadavNo ratings yet
- 2102 013011kaprnDocument11 pages2102 013011kaprnTiến Việt PhạmNo ratings yet
- CBIR ReportDocument10 pagesCBIR Reportsadasiva19No ratings yet
- Study of The Pre-Processing Impact in A Facial Recognition SystemDocument11 pagesStudy of The Pre-Processing Impact in A Facial Recognition Systemalmudena aguileraNo ratings yet
- Intensification of Resolution in The Realm of Digital ImagingDocument4 pagesIntensification of Resolution in The Realm of Digital ImagingIJCERT PUBLICATIONSNo ratings yet
- Performance Improvement For 2-D Face Recognition Using Multi-Classifier and BPNDocument7 pagesPerformance Improvement For 2-D Face Recognition Using Multi-Classifier and BPNWadakam AnnaNo ratings yet
- Zernike Face RecognitonDocument22 pagesZernike Face RecognitonFodelman FidelNo ratings yet
- Facial Features ExtractionDocument12 pagesFacial Features ExtractionSohaib Lucky CharmNo ratings yet
- Image Retrieval Approach Based On Local Texture Information Derived From Predefined Patterns and Spatial Domain InformationDocument9 pagesImage Retrieval Approach Based On Local Texture Information Derived From Predefined Patterns and Spatial Domain InformationGilbertNo ratings yet
- Color Space Normalization Enhancing The Discriminating Power of Color Spaces For Face RecognitionDocument13 pagesColor Space Normalization Enhancing The Discriminating Power of Color Spaces For Face RecognitionJatiKrismanadiNo ratings yet
- Manual of Examination Automation SystemDocument11 pagesManual of Examination Automation SystemSabha NayaghamNo ratings yet
- Image and Vision Computing: Georgia Sandbach, Stefanos Zafeiriou, Maja Pantic, Lijun YinDocument15 pagesImage and Vision Computing: Georgia Sandbach, Stefanos Zafeiriou, Maja Pantic, Lijun YinSabha NayaghamNo ratings yet
- Ece Assessment ManualDocument68 pagesEce Assessment ManualSabha Nayagham0% (1)
- 2.1-Characterization of Learning ProblemsDocument14 pages2.1-Characterization of Learning ProblemsSabha NayaghamNo ratings yet
- Learning Multi-Scale Block Local Binary Patterns For Face RecognitionDocument10 pagesLearning Multi-Scale Block Local Binary Patterns For Face RecognitionSabha NayaghamNo ratings yet
- Pattern Recognition: Xijian Fan, Tardi TjahjadiDocument8 pagesPattern Recognition: Xijian Fan, Tardi TjahjadiSabha NayaghamNo ratings yet
- Pattern Recognition: Wei Zhang, Youmei Zhang, Lin Ma, Jingwei Guan, Shijie GongDocument12 pagesPattern Recognition: Wei Zhang, Youmei Zhang, Lin Ma, Jingwei Guan, Shijie GongSabha NayaghamNo ratings yet
- Aicte Exam Reforms Guidelines: by Prof. B.A.KhivsaraDocument49 pagesAicte Exam Reforms Guidelines: by Prof. B.A.KhivsaraSabha NayaghamNo ratings yet
- 100 Names Of The Hindu Goddess KaliDocument5 pages100 Names Of The Hindu Goddess KaliSabha NayaghamNo ratings yet
- Yajurveda Trikala SandhyavandanamDocument19 pagesYajurveda Trikala SandhyavandanamSabha NayaghamNo ratings yet
- 1812 10595Document12 pages1812 10595Sabha NayaghamNo ratings yet
- Sta Saiva Nitya AnushtanamDocument74 pagesSta Saiva Nitya AnushtanamSabha NayaghamNo ratings yet
- Anup K Singh, PHDDocument14 pagesAnup K Singh, PHDSabha NayaghamNo ratings yet
- Assessment: Dr. Jayesh PatidarDocument50 pagesAssessment: Dr. Jayesh PatidarSabha NayaghamNo ratings yet
- 1812 10595Document12 pages1812 10595Sabha NayaghamNo ratings yet
- Student Learning Time (SLT) & AssessmentDocument58 pagesStudent Learning Time (SLT) & AssessmentSabha NayaghamNo ratings yet
- 1702 03349Document5 pages1702 03349Sabha NayaghamNo ratings yet
- 1702 03349Document5 pages1702 03349Sabha NayaghamNo ratings yet
- MCP PDFDocument21 pagesMCP PDFSabha NayaghamNo ratings yet
- 978 3 319 10840 7 - 14Document2 pages978 3 319 10840 7 - 14Sabha NayaghamNo ratings yet
- 978 3 319 10840 7 - 14Document2 pages978 3 319 10840 7 - 14Sabha NayaghamNo ratings yet
- Pandemonium Architecture - WikipediaDocument7 pagesPandemonium Architecture - WikipediaSabha NayaghamNo ratings yet
- Software Engineering Assessments Using Blooms TaxonomyDocument7 pagesSoftware Engineering Assessments Using Blooms TaxonomySabha NayaghamNo ratings yet
- Types of PlagirismDocument3 pagesTypes of PlagirismSabha NayaghamNo ratings yet
- Basic Data Handling and Plotting With SCILAB: January 2013Document16 pagesBasic Data Handling and Plotting With SCILAB: January 2013Sabha NayaghamNo ratings yet
- AnswersDocument33 pagesAnswersRaj kumarNo ratings yet
- Chapter 2 - SVM (Support Vector Machine) - Theory - Machine Learning 101 - MediumDocument9 pagesChapter 2 - SVM (Support Vector Machine) - Theory - Machine Learning 101 - MediumSabha NayaghamNo ratings yet
- Biometric Facial Recognition - FindBiometrics PDFDocument10 pagesBiometric Facial Recognition - FindBiometrics PDFSabha NayaghamNo ratings yet
- Facial Recognition System - WikipediaDocument13 pagesFacial Recognition System - WikipediaSabha NayaghamNo ratings yet
- Physice 2013 Unsolved Paper Outside Delhi PDFDocument7 pagesPhysice 2013 Unsolved Paper Outside Delhi PDFAbhilashaNo ratings yet
- D 4 Development of Beam Equations: M X V XDocument1 pageD 4 Development of Beam Equations: M X V XAHMED SHAKERNo ratings yet
- Our Products: Powercore Grain Oriented Electrical SteelDocument20 pagesOur Products: Powercore Grain Oriented Electrical SteelkoalaboiNo ratings yet
- ICT - 81 - F32A - ISO - 13485 - and - MDD - IVDD - Checklist - Rev1 - 01.05.2020 - ALAMIN (1) (Recovered)Document41 pagesICT - 81 - F32A - ISO - 13485 - and - MDD - IVDD - Checklist - Rev1 - 01.05.2020 - ALAMIN (1) (Recovered)Basma ashrafNo ratings yet
- SCI 7 Q1 WK5 Solutions A LEA TOMASDocument5 pagesSCI 7 Q1 WK5 Solutions A LEA TOMASJoyce CarilloNo ratings yet
- Guidelines For Synopsis & Dissertation-DefenseDocument10 pagesGuidelines For Synopsis & Dissertation-DefenseRajni KumariNo ratings yet
- Awareness On Biomedical Waste Management Among Dental Students - A Cross Sectional Questionnaire SurveyDocument8 pagesAwareness On Biomedical Waste Management Among Dental Students - A Cross Sectional Questionnaire SurveyIJAR JOURNALNo ratings yet
- SARTIKA LESTARI PCR COVID-19 POSITIVEDocument1 pageSARTIKA LESTARI PCR COVID-19 POSITIVEsartika lestariNo ratings yet
- Narrative Report On Catch Up Friday ReadingDocument2 pagesNarrative Report On Catch Up Friday ReadingNova Mae AgraviadorNo ratings yet
- Dream Drills for High Hardened SteelDocument8 pagesDream Drills for High Hardened SteelPuneeth KumarNo ratings yet
- Medical Imaging - Seminar Topics Project Ideas On Computer ...Document52 pagesMedical Imaging - Seminar Topics Project Ideas On Computer ...Andabi JoshuaNo ratings yet
- Liquid Ring Vacuum Pumps: LPH 75320, LPH 75330, LPH 75340Document10 pagesLiquid Ring Vacuum Pumps: LPH 75320, LPH 75330, LPH 75340pablodugalNo ratings yet
- DLL in Science 5 Q1 W1Document3 pagesDLL in Science 5 Q1 W1Rhinalyn Andaya Barberan100% (2)
- UFO FILES Black Box Ufo SecretsDocument10 pagesUFO FILES Black Box Ufo SecretsNomad XNo ratings yet
- H Configurations V12 enDocument37 pagesH Configurations V12 enJerald SlaterNo ratings yet
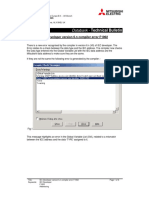
- IEC Developer version 6.n compiler error F1002Document6 pagesIEC Developer version 6.n compiler error F1002AnddyNo ratings yet
- Schmitt Trigger FinalDocument4 pagesSchmitt Trigger Finalsidd14feb92No ratings yet
- Unit 3 Digital Documentation: Multiple Choice QuestionsDocument7 pagesUnit 3 Digital Documentation: Multiple Choice Questions07tp27652% (21)
- 18.443 MIT Stats CourseDocument139 pages18.443 MIT Stats CourseAditya JainNo ratings yet
- Lesson 4: Mean and Variance of Discrete Random Variable: Grade 11 - Statistics & ProbabilityDocument26 pagesLesson 4: Mean and Variance of Discrete Random Variable: Grade 11 - Statistics & Probabilitynicole MenesNo ratings yet
- Pragmatics: The Study of Its Historical Overview, Meanings, Scope and The Context in Language UseDocument7 pagesPragmatics: The Study of Its Historical Overview, Meanings, Scope and The Context in Language UseIHINOSEN IYOHANo ratings yet
- Ici-Ultratech Build Beautiful Award For Homes: Indian Concrete InstituteDocument6 pagesIci-Ultratech Build Beautiful Award For Homes: Indian Concrete InstituteRavi NairNo ratings yet
- Is BN 9789526041957Document72 pagesIs BN 9789526041957supriya rakshitNo ratings yet
- Autochief® C20: Engine Control and Monitoring For General ElectricDocument2 pagesAutochief® C20: Engine Control and Monitoring For General ElectricВадим ГаранNo ratings yet
- ZFDC 20 1HDocument1 pageZFDC 20 1Hkentier21No ratings yet
- REHAU 20UFH InstallationDocument84 pagesREHAU 20UFH InstallationngrigoreNo ratings yet
- Fireclass: FC503 & FC506Document16 pagesFireclass: FC503 & FC506Mersal AliraqiNo ratings yet
- MCA 312 Design&Analysis of Algorithm QuestionBankDocument7 pagesMCA 312 Design&Analysis of Algorithm QuestionBanknbprNo ratings yet
- Registration Confirmation: 315VC18331 Aug 24 2009 7:47PM Devashish Chourasiya 24/05/1989 Mechanical RanchiDocument2 pagesRegistration Confirmation: 315VC18331 Aug 24 2009 7:47PM Devashish Chourasiya 24/05/1989 Mechanical Ranchicalculatorfc101No ratings yet
- Xerox University Microfilms: 300 North Zeeb Road Ann Arbor, Michigan 48106Document427 pagesXerox University Microfilms: 300 North Zeeb Road Ann Arbor, Michigan 48106Muhammad Haris Khan KhattakNo ratings yet
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryFrom EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNo ratings yet
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (54)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- AI Money Machine: Unlock the Secrets to Making Money Online with AIFrom EverandAI Money Machine: Unlock the Secrets to Making Money Online with AINo ratings yet
- 100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesFrom Everand100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesNo ratings yet
- Artificial Intelligence & Generative AI for Beginners: The Complete GuideFrom EverandArtificial Intelligence & Generative AI for Beginners: The Complete GuideRating: 5 out of 5 stars5/5 (1)
- How to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.From EverandHow to Make Money Online Using ChatGPT Prompts: Secrets Revealed for Unlocking Hidden Opportunities. Earn Full-Time Income Using ChatGPT with the Untold Potential of Conversational AI.No ratings yet
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)