You might also like
- Sample Theory With Questions Differential Calculus-I (MS) Unit-2 PDFDocument24 pagesSample Theory With Questions Differential Calculus-I (MS) Unit-2 PDFZERO TO VARIABLENo ratings yet
- Sample Theory of Maxwell's EquationDocument4 pagesSample Theory of Maxwell's EquationDhrithi RajputNo ratings yet
- Sample Theory - Joint Distribution (Unit-11) NMDocument13 pagesSample Theory - Joint Distribution (Unit-11) NMZERO TO VARIABLENo ratings yet
- Sample Theory With Ques. - Estimation (JAM MS Unit-14)Document25 pagesSample Theory With Ques. - Estimation (JAM MS Unit-14)ZERO TO VARIABLENo ratings yet
- Sample Theory With Ques. - Thermodynamics (Unit - 10) - 3Document26 pagesSample Theory With Ques. - Thermodynamics (Unit - 10) - 3ZERO TO VARIABLENo ratings yet
- Sample Theory With Questions Differential Calculus-I (MS) Unit-2 PDFDocument24 pagesSample Theory With Questions Differential Calculus-I (MS) Unit-2 PDFZERO TO VARIABLENo ratings yet
- Tech Spark Budget: Fine Arts & Creativity 2,850 683Document18 pagesTech Spark Budget: Fine Arts & Creativity 2,850 683ZERO TO VARIABLENo ratings yet
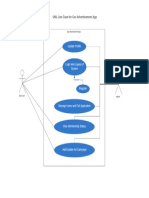
- Car Advertisement App-1Document1 pageCar Advertisement App-1ZERO TO VARIABLENo ratings yet
- ICT110 Introduction To Data Science: Semester 1, 2020Document7 pagesICT110 Introduction To Data Science: Semester 1, 2020ZERO TO VARIABLENo ratings yet
- 2.parth (Deputy) : Department Volunteers Contact Number Co-OrdinatorDocument6 pages2.parth (Deputy) : Department Volunteers Contact Number Co-OrdinatorZERO TO VARIABLENo ratings yet
- BT-Managing Data - Assessment 2Document17 pagesBT-Managing Data - Assessment 2ZERO TO VARIABLENo ratings yet
- Basic Use Case Diagram PDFDocument1 pageBasic Use Case Diagram PDFZERO TO VARIABLENo ratings yet
- In-Course Assessment (Ica) Specification: School of Computing, Engineering and Digital TechnologiesDocument5 pagesIn-Course Assessment (Ica) Specification: School of Computing, Engineering and Digital TechnologiesZERO TO VARIABLENo ratings yet
- ChemistryDocument12 pagesChemistryZERO TO VARIABLENo ratings yet
- 2 and 3Document4 pages2 and 3ZERO TO VARIABLENo ratings yet
- UML Class DiagramDocument1 pageUML Class DiagramZERO TO VARIABLENo ratings yet
- Car Advertisement App - Specification StatementDocument1 pageCar Advertisement App - Specification StatementZERO TO VARIABLENo ratings yet
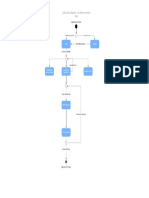
- UML Activity Diagram PDFDocument1 pageUML Activity Diagram PDFZERO TO VARIABLENo ratings yet
- UML Activity Diagram PDFDocument1 pageUML Activity Diagram PDFZERO TO VARIABLENo ratings yet
- LA AnnouncementsDocument1 pageLA AnnouncementsZERO TO VARIABLENo ratings yet
- Car Advertisement App-1Document1 pageCar Advertisement App-1ZERO TO VARIABLENo ratings yet
- UML State Diagram PDFDocument1 pageUML State Diagram PDFZERO TO VARIABLENo ratings yet
- LA AnnouncementsDocument1 pageLA AnnouncementsZERO TO VARIABLENo ratings yet
- By 6nokko6j29 1Document16 pagesBy 6nokko6j29 1ZERO TO VARIABLENo ratings yet
- UML Class DiagramDocument1 pageUML Class DiagramZERO TO VARIABLENo ratings yet
- ICT110 Introduction To Data Science: Semester 1, 2020Document7 pagesICT110 Introduction To Data Science: Semester 1, 2020ZERO TO VARIABLENo ratings yet
- Turnitin1 PlagDocument24 pagesTurnitin1 PlagZERO TO VARIABLENo ratings yet
- YR-ENGINEERING SCIENCE - UpdatedDocument29 pagesYR-ENGINEERING SCIENCE - UpdatedZERO TO VARIABLENo ratings yet
- SCMD Assignment 1 Report GuideDocument1 pageSCMD Assignment 1 Report GuideZERO TO VARIABLENo ratings yet
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (400)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (121)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Use of Information Technology in The Flight Catering ServicesDocument32 pagesUse of Information Technology in The Flight Catering ServicesAbhiroop SenNo ratings yet
- Ecological Fire MGMT Guidelines V5Document40 pagesEcological Fire MGMT Guidelines V5MeNo ratings yet
- Baño - Griferia - KOHLER - K-74013M+0.50GPMDocument3 pagesBaño - Griferia - KOHLER - K-74013M+0.50GPMGiordano Tuanama YapoNo ratings yet
- Bright Ideas 2 Unit 1 Test-Fusionado-Páginas-1-33Document33 pagesBright Ideas 2 Unit 1 Test-Fusionado-Páginas-1-33Eleonora Graziano100% (1)
- Introduction On Photogrammetry Paul R WolfDocument33 pagesIntroduction On Photogrammetry Paul R Wolfadnan yusufNo ratings yet
- ED1021 - I/O Expander With UART Interface & Analog Inputs: PreliminaryDocument9 pagesED1021 - I/O Expander With UART Interface & Analog Inputs: PreliminaryMilan NovakovićNo ratings yet
- Figure Eight Island Homeowners' Association, Inc. Case StudyDocument16 pagesFigure Eight Island Homeowners' Association, Inc. Case StudyYoong YingNo ratings yet
- DEH S4150BT Owners Manual PDFDocument96 pagesDEH S4150BT Owners Manual PDFfatih konaçoğluNo ratings yet
- Sustainability Schematic ReportDocument5 pagesSustainability Schematic ReportsakhrNo ratings yet
- Drugs and Tinnitus - Neil Bauman PHD - April '09Document2 pagesDrugs and Tinnitus - Neil Bauman PHD - April '09DownTheTheRabbitHole108No ratings yet
- Nokia 6131 NFCDocument5 pagesNokia 6131 NFCvetvetNo ratings yet
- 4mb/01r-Que-2023 Jun Edexcel PastpaperDocument24 pages4mb/01r-Que-2023 Jun Edexcel Pastpaperaugust.shwanNo ratings yet
- Pengaruh Volume Pemberian Air Terhadap Pertumbuhan Bibit Kelapa Sawit Di Pembibitan UtamaDocument11 pagesPengaruh Volume Pemberian Air Terhadap Pertumbuhan Bibit Kelapa Sawit Di Pembibitan UtamaTahum MatfuahNo ratings yet
- All About CupcakesDocument4 pagesAll About CupcakesRevtech RevalbosNo ratings yet
- Perbedaan Fermentasi Dan Respirasi Anaerob (Campbell Biology 12th Ed.)Document4 pagesPerbedaan Fermentasi Dan Respirasi Anaerob (Campbell Biology 12th Ed.)Oppof7 OppoNo ratings yet
- Marshall Abby - Chess Cafe - The Openings Explained - 1-63, 2015-OCR, 682pDocument682 pagesMarshall Abby - Chess Cafe - The Openings Explained - 1-63, 2015-OCR, 682pArtur MałkowskiNo ratings yet
- 12abmb2 Group4 Chapter1Document20 pages12abmb2 Group4 Chapter1Kenneth Del RosarioNo ratings yet
- Safe and Gentle Ventilation For Little Patients Easy - Light - SmartDocument4 pagesSafe and Gentle Ventilation For Little Patients Easy - Light - SmartSteven BrownNo ratings yet
- Full Download Test Bank For Financial Reporting Financial Statement Analysis and Valuation 8th Edition PDF Full ChapterDocument36 pagesFull Download Test Bank For Financial Reporting Financial Statement Analysis and Valuation 8th Edition PDF Full Chaptervespersrealizeravzo100% (18)
- Concrete Tunnel Design and Calculation Spreadsheet Based On AASHTO and ACIDocument3 pagesConcrete Tunnel Design and Calculation Spreadsheet Based On AASHTO and ACIFirat PulatNo ratings yet
- Experiments: Mouthpiece, Which Is A Short Tube of Length About Equal To The Radius of The Orifice That Projects Into TheDocument4 pagesExperiments: Mouthpiece, Which Is A Short Tube of Length About Equal To The Radius of The Orifice That Projects Into Thefrancis dimakilingNo ratings yet
- P1 - Duct Design IntroductionDocument30 pagesP1 - Duct Design IntroductionAndryx MartinezNo ratings yet
- Technical Datasheet: ENGUARD™ BP 75 ARF Multi Purpose Bonding Paste With FibresDocument2 pagesTechnical Datasheet: ENGUARD™ BP 75 ARF Multi Purpose Bonding Paste With FibresFernando Cesar PérezNo ratings yet
- Nigeria Certificate in Education Science ProgrammeDocument215 pagesNigeria Certificate in Education Science Programmemuhammadbinali77_465No ratings yet
- MIMSDocument3 pagesMIMSFrancineAntoinetteGonzalesNo ratings yet
- BJT Common Emitter Characteristics: Experiment 6Document5 pagesBJT Common Emitter Characteristics: Experiment 6beesahNo ratings yet
- What Is New in API 610 11th EdDocument6 pagesWhat Is New in API 610 11th EdAnonymous 1XHScfCINo ratings yet
- BFD-180-570 DN65 GBDocument25 pagesBFD-180-570 DN65 GBalexander100% (3)
- Renault Gearbox and Final Drive OilsDocument10 pagesRenault Gearbox and Final Drive OilsPhat0% (1)
- AidsDocument22 pagesAidsVicky Singh100% (2)