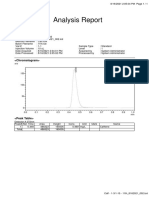
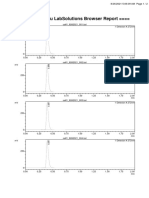
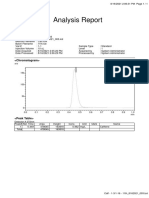
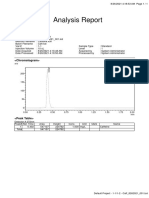
You might also like
- The Folin-Ciocalteu Assay RevisitedDocument10 pagesThe Folin-Ciocalteu Assay RevisitedoniatrdNo ratings yet
- Analytical Methods: Technical NoteDocument6 pagesAnalytical Methods: Technical NotelichenresearchNo ratings yet
- 2017 Fish Purge and TrapDocument10 pages2017 Fish Purge and TrapNANCY MONTES SALAZARNo ratings yet
- Principal Component Analysis of WineDocument20 pagesPrincipal Component Analysis of WineAdam Li PauNo ratings yet
- Qar 3Document7 pagesQar 3Raffy FlandesNo ratings yet
- New Approach For Determination of Volatile Fatty Acid in Anaerobic Digester SampleDocument19 pagesNew Approach For Determination of Volatile Fatty Acid in Anaerobic Digester SampleFelipe RomaniNo ratings yet
- Ứng dụng chiết SPE-MIPs để xử lý và định lượng rutin trong thuốc namDocument8 pagesỨng dụng chiết SPE-MIPs để xử lý và định lượng rutin trong thuốc namNguyen Le Yen NhungNo ratings yet
- Analytical Methods: PaperDocument5 pagesAnalytical Methods: PaperZulkarnain AjoiNo ratings yet
- Barrientos 2016 - Acido - SalicilicoDocument6 pagesBarrientos 2016 - Acido - SalicilicoMarco Vinicius Camboim BellanNo ratings yet
- HPLC-DAD Method For Metabolic Fingerprinting of The Phenotyping of Sugarcane GenotypesDocument9 pagesHPLC-DAD Method For Metabolic Fingerprinting of The Phenotyping of Sugarcane GenotypesNostimi SoupaNo ratings yet
- Analytical Methods: PaperDocument8 pagesAnalytical Methods: Paperchikh MELKAOUINo ratings yet
- Microwave Assisted Solid Phase Microextraction For Extraction and Selective Enrichment of Four Alkaloids in Lotus LeafDocument8 pagesMicrowave Assisted Solid Phase Microextraction For Extraction and Selective Enrichment of Four Alkaloids in Lotus LeafAndres Fernando Silvestre SuarezNo ratings yet
- Carbon Dots Prepared From CitricDocument8 pagesCarbon Dots Prepared From CitricHuỳnh ĐặngNo ratings yet
- Analytical Methods: PaperDocument11 pagesAnalytical Methods: PaperMANUEL ALEJANDRO CHACON FUENTESNo ratings yet
- #1 Anachem: Qualitative Analysis Is What. Quantitative Analysis Is How MuchDocument11 pages#1 Anachem: Qualitative Analysis Is What. Quantitative Analysis Is How MuchLapitan Jared Anne S.No ratings yet
- Toward Chemical Recycling of PU Foams Study of The Main Purification OptionsanalystDocument9 pagesToward Chemical Recycling of PU Foams Study of The Main Purification OptionsanalystmursyidNo ratings yet
- Simultaneous Determination of Metolazone and PDFDocument13 pagesSimultaneous Determination of Metolazone and PDFAlexandru GondorNo ratings yet
- Determination of Hemicellulose, Cellulose and Lignin in Moso Bamboo by Near Infrared SpectrosDocument12 pagesDetermination of Hemicellulose, Cellulose and Lignin in Moso Bamboo by Near Infrared SpectrosSang nguyễnNo ratings yet
- Zein Opt SensDocument8 pagesZein Opt SensVero ArellanoNo ratings yet
- NIR and MIR Spectral Data Fusion For Rapid DetectionDocument8 pagesNIR and MIR Spectral Data Fusion For Rapid DetectionJavi Moros PortolésNo ratings yet
- Ojabc 3 114Document4 pagesOjabc 3 114Mifa Nur fatikaNo ratings yet
- Anal Methods 2011Document9 pagesAnal Methods 2011artemNo ratings yet
- Cheng 2013Document6 pagesCheng 2013ngocan886979No ratings yet
- Artigo Paper SprayDocument9 pagesArtigo Paper SprayJean CarlosNo ratings yet
- 881-20141210231439281 UnlockDocument6 pages881-20141210231439281 UnlockNur AjiNo ratings yet
- Accurate Analysis of Parabens in Human Urine Using Isotope-Dilution Ultrahigh-Performance Liquid Chromatography-High Resolution Mass SpectrometryDocument5 pagesAccurate Analysis of Parabens in Human Urine Using Isotope-Dilution Ultrahigh-Performance Liquid Chromatography-High Resolution Mass SpectrometryHanum ぬめ Sekar PNo ratings yet
- Paper IR ATR PDFDocument7 pagesPaper IR ATR PDFari twovNo ratings yet
- Assignment SolutionsDocument4 pagesAssignment Solutionspatrickchiyangi6No ratings yet
- Alba Uv VisibleDocument4 pagesAlba Uv VisibleSankaraSatyadevNo ratings yet
- Method Development and Validation On RP-HPLC For Assay of Bulk and Formulation of CarmustineDocument11 pagesMethod Development and Validation On RP-HPLC For Assay of Bulk and Formulation of CarmustineVedant BhorNo ratings yet
- X-Ray Spectrometry - 2021 - Margu - Determination of Essential Elements MN Fe Cu and ZN in Herbal Teas by TXRF FAASDocument10 pagesX-Ray Spectrometry - 2021 - Margu - Determination of Essential Elements MN Fe Cu and ZN in Herbal Teas by TXRF FAASalex figueroaNo ratings yet
- Shaw R.A., Mantsch H.H. - Infrared Spectroscopy in Clinical and Diagnostic Analysis (2000)Document20 pagesShaw R.A., Mantsch H.H. - Infrared Spectroscopy in Clinical and Diagnostic Analysis (2000)Max TerNo ratings yet
- Ont.201711107 1117Document12 pagesOnt.201711107 1117Felix PrawiraNo ratings yet
- Analytical Methods: Volume 5 - Number 20 - 21 October 2013 - Pages 5353-5838Document10 pagesAnalytical Methods: Volume 5 - Number 20 - 21 October 2013 - Pages 5353-5838Ishu KilimNo ratings yet
- Experiment No. 6 - ThinLayerChromatographyDocument5 pagesExperiment No. 6 - ThinLayerChromatographyKarla Joy P. SucgangNo ratings yet
- AnalMeth SCFADocument7 pagesAnalMeth SCFAMayra SanchezNo ratings yet
- Optical Fiber-Based Synchronous Fluorescence Spectroscopy For Bacterial Discrimination Directly From Colonies On Agar PlatesDocument11 pagesOptical Fiber-Based Synchronous Fluorescence Spectroscopy For Bacterial Discrimination Directly From Colonies On Agar PlatesFrancisca MartinichNo ratings yet
- Iurian-Assessment of Measurement Result Uncertainty in Determination ofDocument9 pagesIurian-Assessment of Measurement Result Uncertainty in Determination ofBao Ngoc TranNo ratings yet
- Benzy Piper AzineDocument10 pagesBenzy Piper AzineAryl ChemNo ratings yet
- Quality Evaluation of Tender Jackfruit Using Near-Infrared Reflectance SpectrosDocument5 pagesQuality Evaluation of Tender Jackfruit Using Near-Infrared Reflectance SpectrosShailendra RajanNo ratings yet
- ExperimentDocument6 pagesExperimentMc Lin Gio DataNo ratings yet
- PH-UV Absorbance Dataset For The DeterminationDocument8 pagesPH-UV Absorbance Dataset For The DeterminationMinh Thu Ngo ThiNo ratings yet
- Sugarcane Quality Analysis by InfraredDocument4 pagesSugarcane Quality Analysis by InfraredDouglasNo ratings yet
- Alpinia Galanga and Alpinia Calcarata: Isolation and HPLC Quantification of Berberine Alkaloid FromDocument8 pagesAlpinia Galanga and Alpinia Calcarata: Isolation and HPLC Quantification of Berberine Alkaloid FromIinthand BEncii DyNo ratings yet
- Development and Validation of A Near InfDocument7 pagesDevelopment and Validation of A Near InfnolanNo ratings yet
- Validated Spectroscopic Method For Estimation of Naproxen From Tablet FormulationDocument3 pagesValidated Spectroscopic Method For Estimation of Naproxen From Tablet FormulationAdil AminNo ratings yet
- Undergraduate ThesisDocument89 pagesUndergraduate ThesishgNo ratings yet
- Wirasuta 2016Document8 pagesWirasuta 2016giyan77No ratings yet
- Supercritical Uid (CO2) Chromatography For Quantitative Determination of Selected Cancer Therapeutic Drugs in The Presence of Potential ImpuritiesDocument7 pagesSupercritical Uid (CO2) Chromatography For Quantitative Determination of Selected Cancer Therapeutic Drugs in The Presence of Potential ImpuritiesXuân ĐứcNo ratings yet
- Analytical Methods: PaperDocument8 pagesAnalytical Methods: PaperHulqiNo ratings yet
- Các thành phần hoạt tính sinh học của lá Annona squamosa LDocument5 pagesCác thành phần hoạt tính sinh học của lá Annona squamosa LNhư LâmNo ratings yet
- Optimization and Method Validation of Determining Polyphenolic Compounds by UFLC-DAD System Using Two Biphenyl and Pentafluorophenylpropyl ColumnsDocument10 pagesOptimization and Method Validation of Determining Polyphenolic Compounds by UFLC-DAD System Using Two Biphenyl and Pentafluorophenylpropyl ColumnsdiahfaradinaNo ratings yet
- Jiang 2018Document10 pagesJiang 2018Willian QuinteroNo ratings yet
- Duplicate Analysis in Geochemical Practice: Michael Thompson and Richard JDocument9 pagesDuplicate Analysis in Geochemical Practice: Michael Thompson and Richard JAlexNo ratings yet
- 28551-Article Text-142974-1-10-20181119Document5 pages28551-Article Text-142974-1-10-20181119Laksmi DwiNo ratings yet
- PLS-UV Spectrophotometric Method For The Simultaneous Determination of Paracetamol, Acetylsalicylic Acid and Caffeine in Pharmaceutical FormulationsDocument4 pagesPLS-UV Spectrophotometric Method For The Simultaneous Determination of Paracetamol, Acetylsalicylic Acid and Caffeine in Pharmaceutical FormulationselvidasariyunilarosiNo ratings yet
- Extractables in Drug ContainerDocument8 pagesExtractables in Drug ContainerTasNo ratings yet
- Jurnal Spektrofotometri 2Document5 pagesJurnal Spektrofotometri 2Alvin Wahyu Puspita SariNo ratings yet
- Estimation of Xipamide by Using HPLC in Pure and Pharmaceutical Dosage FormDocument8 pagesEstimation of Xipamide by Using HPLC in Pure and Pharmaceutical Dosage FormBaru Chandrasekhar RaoNo ratings yet
- PQ Test Protocol MPA Sphere 20231211 212421Document5 pagesPQ Test Protocol MPA Sphere 20231211 212421Ali RizviNo ratings yet
- MX Multi-Module Vortex MixerDocument1 pageMX Multi-Module Vortex MixerAli RizviNo ratings yet
- Final Lab Req ListDocument6 pagesFinal Lab Req ListAli RizviNo ratings yet
- D2 - Ho Check ResultDocument1 pageD2 - Ho Check ResultAli RizviNo ratings yet
- PQ Test Protocol MPA Sphere 20231211 212421Document5 pagesPQ Test Protocol MPA Sphere 20231211 212421Ali RizviNo ratings yet
- System Check ReportDocument1 pageSystem Check ReportAli RizviNo ratings yet
- Caff - 1-4 - 1-21 - H1st - 8162021 - 003Document1 pageCaff - 1-4 - 1-21 - H1st - 8162021 - 003Ali RizviNo ratings yet
- PQ Test Protocol MPA Sphere 20231211 212421Document5 pagesPQ Test Protocol MPA Sphere 20231211 212421Ali RizviNo ratings yet
- PQ Test Protocol MPA Sample Compartment 20231211 222536Document5 pagesPQ Test Protocol MPA Sample Compartment 20231211 222536Ali RizviNo ratings yet
- PQ Test Protocol MPA Sample Compartment 20231211 222536Document5 pagesPQ Test Protocol MPA Sample Compartment 20231211 222536Ali RizviNo ratings yet
- PQ Test Protocol MPA Sample Compartment 20231211 222536Document5 pagesPQ Test Protocol MPA Sample Compartment 20231211 222536Ali RizviNo ratings yet
- Default Project - 1-2 - 1-9 - Caff1 - 8262021 - 003Document1 pageDefault Project - 1-2 - 1-9 - Caff1 - 8262021 - 003Ali RizviNo ratings yet
- PQ Test Protocol MPA Sphere 20231211 212421Document5 pagesPQ Test Protocol MPA Sphere 20231211 212421Ali RizviNo ratings yet
- Din 96200-04Document4 pagesDin 96200-04Ali RizviNo ratings yet
- Default Project - 1-2 - 1-8 - Caff1 - 8262021 - 002Document1 pageDefault Project - 1-2 - 1-8 - Caff1 - 8262021 - 002Ali RizviNo ratings yet
- Caff - 1-3 - 1-15 - 11th - 8162021 - 002Document1 pageCaff - 1-3 - 1-15 - 11th - 8162021 - 002Ali RizviNo ratings yet
- Caff - 1-4 - 1-20 - H1st - 8162021 - 002Document1 pageCaff - 1-4 - 1-20 - H1st - 8162021 - 002Ali RizviNo ratings yet
- C - LabSolutions - System - 0 - Admin - LSS Quantitative Browser TableDocument2 pagesC - LabSolutions - System - 0 - Admin - LSS Quantitative Browser TableAli RizviNo ratings yet
- Default Project - 1-2 - 1-10 - Caff1 - 8262021 - 004Document1 pageDefault Project - 1-2 - 1-10 - Caff1 - 8262021 - 004Ali RizviNo ratings yet
- Caff - 1-3 - 1-16 - 11th - 8162021 - 003Document1 pageCaff - 1-3 - 1-16 - 11th - 8162021 - 003Ali RizviNo ratings yet
- Default Project - 1-1 - 1-2 - Caff - 8262021 - 001Document1 pageDefault Project - 1-1 - 1-2 - Caff - 8262021 - 001Ali RizviNo ratings yet
- Default Project - 1-2 - 1-7 - Caff1 - 8262021 - 001Document1 pageDefault Project - 1-2 - 1-7 - Caff1 - 8262021 - 001Ali RizviNo ratings yet
- Default Project - 1-1 - 1-4 - Caff - 8262021 - 003Document1 pageDefault Project - 1-1 - 1-4 - Caff - 8262021 - 003Ali RizviNo ratings yet
- Caff - 1-3 - 1-14 - 11th - 8162021 - 001 PDFDocument1 pageCaff - 1-3 - 1-14 - 11th - 8162021 - 001 PDFAli RizviNo ratings yet
- Default Project - 1-2 - 1-11 - Caff1 - 8262021 - 005Document1 pageDefault Project - 1-2 - 1-11 - Caff1 - 8262021 - 005Ali RizviNo ratings yet
- Co Hi2211-2210 en 280211Document4 pagesCo Hi2211-2210 en 280211Ali RizviNo ratings yet
- Default Project - 1-1 - 1-6 - Caff - 8262021 - 005Document1 pageDefault Project - 1-1 - 1-6 - Caff - 8262021 - 005Ali RizviNo ratings yet
- Hi83141 PH Meter AnalogDocument1 pageHi83141 PH Meter AnalogAli RizviNo ratings yet
- HI2002Document4 pagesHI2002Ali RizviNo ratings yet
- Hi8734 Multi Range Conductivity MeterDocument1 pageHi8734 Multi Range Conductivity MeterAli RizviNo ratings yet
- 2018-Bell-Abusos en La Infancia y Experiencias Psicóticas en La Edad Adulta-Hallazgos de Un Estudio Longitudinal de 35 AñosDocument6 pages2018-Bell-Abusos en La Infancia y Experiencias Psicóticas en La Edad Adulta-Hallazgos de Un Estudio Longitudinal de 35 Añosmvillar15_247536468No ratings yet
- Midterms (Case Study) - Gulbin, Tautho, VillamorDocument19 pagesMidterms (Case Study) - Gulbin, Tautho, VillamorEdy Halen L. TauthoNo ratings yet
- Chapter 1 - Introduction of BRMDocument54 pagesChapter 1 - Introduction of BRMHiep TrinhNo ratings yet
- Sample Questions: Subject Name: Semester: VIDocument17 pagesSample Questions: Subject Name: Semester: VIAlefiya RampurawalaNo ratings yet
- Mathematical Modeling Using Linear RegresionDocument52 pagesMathematical Modeling Using Linear RegresionIrinel IonutNo ratings yet
- Statistical Theory and Methodology in Science and EngineeringDocument607 pagesStatistical Theory and Methodology in Science and EngineeringNelson IsraelNo ratings yet
- J Jbusres 2016 01 013 PDFDocument8 pagesJ Jbusres 2016 01 013 PDFMary Jane CadagueNo ratings yet
- Procurement Fraud in The Construction Industry - The Nigerian Public Private Patnership (PPP) Dilemma By: Abubkr MurnaiDocument34 pagesProcurement Fraud in The Construction Industry - The Nigerian Public Private Patnership (PPP) Dilemma By: Abubkr Murnaiabubakar umar murnai murnaiNo ratings yet
- Econometrics - Functional FormsDocument22 pagesEconometrics - Functional FormsNidhi KaushikNo ratings yet
- Ch2 ResearchApproachesDocument13 pagesCh2 ResearchApproachesSoh Mei LingNo ratings yet
- Essentials of Machine Learning Algorithms (With Python and R Codes) PDFDocument20 pagesEssentials of Machine Learning Algorithms (With Python and R Codes) PDFTeodor von Burg100% (1)
- Economies of Scale in European Manufacturing Revisited: July 2001Document31 pagesEconomies of Scale in European Manufacturing Revisited: July 2001vladut_stan_5No ratings yet
- Rec 4B - Regression - n-1Document5 pagesRec 4B - Regression - n-1Skylar HsuNo ratings yet
- The Effects of Gender Inequality in Politics (Quantitative Research)Document11 pagesThe Effects of Gender Inequality in Politics (Quantitative Research)Teymur CəfərliNo ratings yet
- CH 02Document88 pagesCH 02Pan KanNo ratings yet
- Corporate Governance and Environmental Management: A Study of Quoted Industrial Goods Companies in NigeriaDocument9 pagesCorporate Governance and Environmental Management: A Study of Quoted Industrial Goods Companies in NigeriaIJAR JOURNALNo ratings yet
- Body-Esteem Scale For Adolescents and Adults: Journal of Personality AssessmentDocument18 pagesBody-Esteem Scale For Adolescents and Adults: Journal of Personality AssessmentIbec PagamentosNo ratings yet
- BRM NOTES 1 Donald CooperDocument31 pagesBRM NOTES 1 Donald CooperziashaukatNo ratings yet
- Employee Attrition Rate Prediction Using Machine Learning ApproachDocument8 pagesEmployee Attrition Rate Prediction Using Machine Learning ApproachThảoNo ratings yet
- 14 Different Types of Learning in Machine LearningDocument2 pages14 Different Types of Learning in Machine LearningWilliam OlissNo ratings yet
- Course2 - DataAnalysis With Python - Week3 - Exploratory Data AnalysisDocument23 pagesCourse2 - DataAnalysis With Python - Week3 - Exploratory Data AnalysisStefano PenturyNo ratings yet
- Four Question StrategyDocument8 pagesFour Question StrategyJamila Colleen M. Briones50% (2)
- Dividend Changes and FutureDocument23 pagesDividend Changes and FutureMifta HunadzirNo ratings yet
- Unit - 1Document10 pagesUnit - 1Prashant SinghNo ratings yet
- Notes - Goals of Psychological EnquiryDocument6 pagesNotes - Goals of Psychological Enquiryyashu sharmaNo ratings yet
- Format Action ResearchDocument8 pagesFormat Action Researchnorvel1950% (2)
- Application of Machine Learning To The Process of Crop Selection Based On Land DatasetDocument22 pagesApplication of Machine Learning To The Process of Crop Selection Based On Land DatasetResearch ParkNo ratings yet
- Improve - 6 - Full Factorial Experiments - v12-2Document65 pagesImprove - 6 - Full Factorial Experiments - v12-2okanboragameNo ratings yet
- Risks: Predicting Motor Insurance Claims Using Telematics Data-Xgboost Versus Logistic RegressionDocument16 pagesRisks: Predicting Motor Insurance Claims Using Telematics Data-Xgboost Versus Logistic RegressionvijayambaNo ratings yet
- Master Thesis Multiple Regression AnalysisDocument7 pagesMaster Thesis Multiple Regression Analysisqfsimwvff100% (2)