You might also like
- Classification DecisionTreesNaiveBayeskNNDocument75 pagesClassification DecisionTreesNaiveBayeskNNDev kartik AgarwalNo ratings yet
- Decision Tree Using Sci-Kit LearnDocument9 pagesDecision Tree Using Sci-Kit LearnsudeepvmenonNo ratings yet
- Ques 1.give Some Examples of Data Preprocessing Techniques?: Assignment - DWDM Submitted By-Tanya Sikka 1719210284Document7 pagesQues 1.give Some Examples of Data Preprocessing Techniques?: Assignment - DWDM Submitted By-Tanya Sikka 1719210284Sachin ChauhanNo ratings yet
- Prediction: All Topics in Scanned Copy "Adaptive Business Intelligence" by Zbigniewmichlewicz Martin Schmidt)Document46 pagesPrediction: All Topics in Scanned Copy "Adaptive Business Intelligence" by Zbigniewmichlewicz Martin Schmidt)rashNo ratings yet
- Data Mining Questions and AnswersDocument22 pagesData Mining Questions and AnswersdebmatraNo ratings yet
- Basic Concept of Classification (Data Mining)Document11 pagesBasic Concept of Classification (Data Mining)IQAC VMDCNo ratings yet
- Machine Learning TheoryDocument12 pagesMachine Learning TheoryairplaneunderwaterNo ratings yet
- Machine Learning & Data MiningDocument4 pagesMachine Learning & Data MiningPriyaprasad PandaNo ratings yet
- DWDM Unit-3: What Is Classification? What Is Prediction?Document12 pagesDWDM Unit-3: What Is Classification? What Is Prediction?Sai Venkat GudlaNo ratings yet
- Major Issues in Data MiningDocument9 pagesMajor Issues in Data MiningGaurav JaiswalNo ratings yet
- ML Unit 2Document41 pagesML Unit 2abhijit kateNo ratings yet
- ML - Machine Learning PDFDocument13 pagesML - Machine Learning PDFDavid Esteban Meneses RendicNo ratings yet
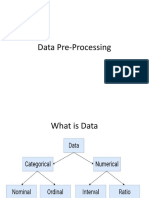
- ICS 2408 - Lecture 2 - Data PreprocessingDocument29 pagesICS 2408 - Lecture 2 - Data Preprocessingpetergitagia9781No ratings yet
- Supervised Learning (Classification and Regression)Document14 pagesSupervised Learning (Classification and Regression)shreya sarkarNo ratings yet
- Data Mining (Viva)Document18 pagesData Mining (Viva)Anubhav ShrivastavaNo ratings yet
- Data StructuresDocument203 pagesData StructuresInvictus InvictusNo ratings yet
- DWM Solution May 2019Document9 pagesDWM Solution May 2019new acc jeetNo ratings yet
- Clustering in RDocument12 pagesClustering in RRenukaNo ratings yet
- Solutions To DM I MID (A)Document19 pagesSolutions To DM I MID (A)jyothibellaryv100% (1)
- ML Unit 1Document27 pagesML Unit 1SUJATA SONWANENo ratings yet
- Unit-3, 4, 5 DWDMDocument31 pagesUnit-3, 4, 5 DWDMGukeshNo ratings yet
- Week 7 - Tree-Based ModelDocument8 pagesWeek 7 - Tree-Based ModelNguyễn Trường Sơn100% (1)
- Data Science AssignmentDocument9 pagesData Science AssignmentAnuja SuryawanshiNo ratings yet
- Lecture2 DataMiningFunctionalitiesDocument18 pagesLecture2 DataMiningFunctionalitiesinsaanNo ratings yet
- DS Midterm Review - Lecture NotesDocument14 pagesDS Midterm Review - Lecture NotesTara Ram MohanNo ratings yet
- Major Issues in Data MiningDocument5 pagesMajor Issues in Data MiningGaurav JaiswalNo ratings yet
- Summary - Data Analytics& Machine LearningDocument18 pagesSummary - Data Analytics& Machine Learningwzq0308chnNo ratings yet
- MLDocument49 pagesMLgetap85298No ratings yet
- Data PreprocessingDocument28 pagesData PreprocessingRahul SharmaNo ratings yet
- Big Data-Week4-2 s2122Document5 pagesBig Data-Week4-2 s2122Uyên Vy Phạm NgọcNo ratings yet
- Intro ML ApplicationsDocument26 pagesIntro ML Applicationsswetank.raut22No ratings yet
- Unit-3 ClassificationDocument28 pagesUnit-3 ClassificationAnand Kumar BhagatNo ratings yet
- Scikit - Notes MLDocument12 pagesScikit - Notes MLVulli Leela Venkata Phanindra100% (1)
- Course - Data Science Foundations - Data MiningDocument3 pagesCourse - Data Science Foundations - Data MiningImtiaz NNo ratings yet
- Data Pre ProcessingDocument48 pagesData Pre ProcessingjyothibellaryvNo ratings yet
- JAVA Advanced 3Document19 pagesJAVA Advanced 3Lucky MahantoNo ratings yet
- Machine LearningDocument9 pagesMachine LearningjetlinNo ratings yet
- Decision TreesDocument14 pagesDecision TreesJustin Russo Harry50% (2)
- MLA Lab 6:-Implementation of Decision TreeDocument16 pagesMLA Lab 6:-Implementation of Decision Treetushar3patil03No ratings yet
- Unit 3 - ClassificationDocument28 pagesUnit 3 - Classificationevanjames038No ratings yet
- Building Good Training Sets UNIT 1 PART2Document46 pagesBuilding Good Training Sets UNIT 1 PART2Aditya SharmaNo ratings yet
- Exp1 Data Visualization: 1.line Chart 2.area Chart 3.bar Chart 4.histogramDocument6 pagesExp1 Data Visualization: 1.line Chart 2.area Chart 3.bar Chart 4.histogramNihar ChalkeNo ratings yet
- Machine Learning and Real-World ApplicationsDocument19 pagesMachine Learning and Real-World ApplicationsMachinePulse100% (1)
- Unit 4Document20 pagesUnit 4aknumsn7724No ratings yet
- Q.1. Why Is Data Preprocessing Required?Document26 pagesQ.1. Why Is Data Preprocessing Required?Akshay Mathur100% (1)
- UNIT-2 Data PreprocessingDocument51 pagesUNIT-2 Data PreprocessingdeeuGirlNo ratings yet
- Data Warehousing/Mining Comp 150 DW Chapter 5: Concept Description: Characterization and ComparisonDocument59 pagesData Warehousing/Mining Comp 150 DW Chapter 5: Concept Description: Characterization and ComparisonkpchakNo ratings yet
- ML Chapter 1Document41 pagesML Chapter 1jkdprince3No ratings yet
- Decision Tree and Related Techniques For Classification in ScalationDocument12 pagesDecision Tree and Related Techniques For Classification in ScalationZazkyeyaNo ratings yet
- DATA MINING NotesDocument37 pagesDATA MINING Notesblack smithNo ratings yet
- Machine Learning - BriefDocument12 pagesMachine Learning - Briefالريس حمادةNo ratings yet
- Data Mining and Data WarehousingDocument47 pagesData Mining and Data WarehousingasdNo ratings yet
- Module2 Ids 240201 162026Document11 pagesModule2 Ids 240201 162026sachinsachitha1321No ratings yet
- Answers PDFDocument9 pagesAnswers PDFMuhammadRizvannIslamKhanNo ratings yet
- Dwdm-Unit-3 R16Document14 pagesDwdm-Unit-3 R16Manaswini BhaskaruniNo ratings yet
- Satyabhama BigdataDocument128 pagesSatyabhama BigdataVijaya Kumar VadladiNo ratings yet
- Data Preparation NotebookDocument14 pagesData Preparation Notebookhaythem.mejri.proNo ratings yet
- DM - Lesson 3 N 4Document3 pagesDM - Lesson 3 N 4romnelleNo ratings yet
- Data Mining Algorithms Classification L4Document7 pagesData Mining Algorithms Classification L4u- m-No ratings yet
- Compiler Design LabDocument2 pagesCompiler Design Labexe37 eatlerNo ratings yet
- Results: High Level Language Code Assembly CodeDocument5 pagesResults: High Level Language Code Assembly Codeexe37 eatlerNo ratings yet
- Assignment of Operating System: Assigned by - Pinki RoyDocument13 pagesAssignment of Operating System: Assigned by - Pinki Royexe37 eatlerNo ratings yet
- Assignment 1. MANET - CS 1424Document7 pagesAssignment 1. MANET - CS 1424exe37 eatlerNo ratings yet
- Kendo GridDocument9 pagesKendo GridAdalid Leonela AdalidNo ratings yet
- 344 Document ControllersDocument6 pages344 Document ControllersalbertNo ratings yet
- 8BITCIPRODMPFSDocument2 pages8BITCIPRODMPFSAntonello MazzaroNo ratings yet
- DD vcredistMSI449FDocument55 pagesDD vcredistMSI449FCristianCimpanuNo ratings yet
- GYM Website PaperDocument2 pagesGYM Website PaperAli AslamNo ratings yet
- WEB UI Application GuideDocument737 pagesWEB UI Application GuideHenryNo ratings yet
- Jack Base ManualDocument245 pagesJack Base ManualDenis PotočnikNo ratings yet
- Computer Padhanam Adobe PageMakerDocument15 pagesComputer Padhanam Adobe PageMakeraboobacker saqafi AgathiNo ratings yet
- Compressed Air Management SystemDocument24 pagesCompressed Air Management SystemAdiRiyanDwiPutraNo ratings yet
- Computer Systems and ApplicationsDocument5 pagesComputer Systems and ApplicationsJohn Gordon TettehNo ratings yet
- Part 2Document39 pagesPart 2JM BrowsingNo ratings yet
- IJECE DamWaterLevelMonitoringandAlertingSystemusingIOT DOI-10.1444523488549IJECE-V5I6P105Document5 pagesIJECE DamWaterLevelMonitoringandAlertingSystemusingIOT DOI-10.1444523488549IJECE-V5I6P105vincent john chattoNo ratings yet
- Informatica Certification Training OnlineDocument11 pagesInformatica Certification Training Onlinensr 2228No ratings yet
- Api Example 1: Vulnerability Type: Api Request's Response Leakage. Screenshot of ComponentDocument49 pagesApi Example 1: Vulnerability Type: Api Request's Response Leakage. Screenshot of ComponentAshlee GregoryNo ratings yet
- CS508 Mega File MCQs Final ByfaisalDocument28 pagesCS508 Mega File MCQs Final ByfaisalSaad Ebaad As-SheikhNo ratings yet
- Oracle Certleader 1z0-808 Vce V2019-Jun-04 by Solomon 95q VceDocument52 pagesOracle Certleader 1z0-808 Vce V2019-Jun-04 by Solomon 95q VceKudosSangNo ratings yet
- Wireless Sensor Networks, Reactjs and Functional Programming For Monitoring of Wild Animals in Puerto Vallarta, Jalisco, MexicoDocument16 pagesWireless Sensor Networks, Reactjs and Functional Programming For Monitoring of Wild Animals in Puerto Vallarta, Jalisco, MexicoLawrence AveryNo ratings yet
- Malware-Classification - Jupyter NotebookDocument7 pagesMalware-Classification - Jupyter Notebook2K18/CO/008 ABHAY LODHINo ratings yet
- NetSDK Programming Manual (Intelligent Event)Document116 pagesNetSDK Programming Manual (Intelligent Event)romarmoNo ratings yet
- RR AuthorDocument1,330 pagesRR AuthorKothasudarshan KumarNo ratings yet
- Assignment - 1 (Kiran Jamil)Document5 pagesAssignment - 1 (Kiran Jamil)Kiran JamilNo ratings yet
- How AI and Machine Learning Improve Enterprise CybersecurityDocument4 pagesHow AI and Machine Learning Improve Enterprise CybersecurityramramNo ratings yet
- Assignment 2 Data Defination Language: VVP Engineering CollegeDocument12 pagesAssignment 2 Data Defination Language: VVP Engineering CollegeFake 1No ratings yet
- (26.04) B2Rise - Sala Romário 11h - Visually Build A Full-Stack Application With SAP Build AppsDocument13 pages(26.04) B2Rise - Sala Romário 11h - Visually Build A Full-Stack Application With SAP Build AppsAntonio Braga FilhoNo ratings yet
- TMCM-6214 TMCL Firmware Manual: Simplified Block DiagramDocument147 pagesTMCM-6214 TMCL Firmware Manual: Simplified Block DiagramJan KubalaNo ratings yet
- Enterprise Resource Planning (ERP) in Improving Operational Efficiency: Case StudyDocument6 pagesEnterprise Resource Planning (ERP) in Improving Operational Efficiency: Case Studyjiby1No ratings yet
- Stop and Start OBIEE 11g LinuxDocument5 pagesStop and Start OBIEE 11g LinuxNawab ShariefNo ratings yet
- 3hac049105 001Document46 pages3hac049105 001Péter DaniNo ratings yet
- UNIX System Services Programming Assembler Callable Services ReferenceDocument1,370 pagesUNIX System Services Programming Assembler Callable Services ReferenceJackson SilvaNo ratings yet
- Itm Lab QuestionsDocument12 pagesItm Lab QuestionsBhagya RàhéjäNo ratings yet