You might also like
- Machine Learning - Home - Coursera Quiz PDFDocument5 pagesMachine Learning - Home - Coursera Quiz PDFMary Peace100% (1)
- CS 229, Public Course Problem Set #1 Solutions: Supervised LearningDocument10 pagesCS 229, Public Course Problem Set #1 Solutions: Supervised Learningsuhar adiNo ratings yet
- 8.linear Time-Invariant (LTI) Systems With Random InputsDocument4 pages8.linear Time-Invariant (LTI) Systems With Random InputsAhmed AlzaidiNo ratings yet
- 7 PDFDocument1 page7 PDFLaith BounenniNo ratings yet
- NotesDocument8 pagesNotes박이삭No ratings yet
- UniversityDocument3 pagesUniversitySudo27No ratings yet
- Taller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoDocument8 pagesTaller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoangieNo ratings yet
- 40 LogisticRegression-1Document2 pages40 LogisticRegression-1Abderrahmane KraiouchNo ratings yet
- Sam HW2Document4 pagesSam HW2Ali HassanNo ratings yet
- Applied Machine Learning: Multiple Linear RegressionDocument25 pagesApplied Machine Learning: Multiple Linear RegressionWanida KrataeNo ratings yet
- AC-ED L03 - RegressionDocument83 pagesAC-ED L03 - RegressionAbel EspinNo ratings yet
- RegularizationDocument3 pagesRegularizationToshinari TongNo ratings yet
- 220 Logistic RegressionDocument5 pages220 Logistic Regressionmihir thakkar100% (1)
- CS 229, Public Course Problem Set #4 Solutions: Unsupervised Learn-Ing and Reinforcement LearningDocument12 pagesCS 229, Public Course Problem Set #4 Solutions: Unsupervised Learn-Ing and Reinforcement Learninglalm9931No ratings yet
- Solutions To Selected Exercises From Chapter 9 Bain & Engelhardt - Second EditionDocument13 pagesSolutions To Selected Exercises From Chapter 9 Bain & Engelhardt - Second EditionMezika WahyuniNo ratings yet
- Notes 24 6382 Legendre FunctionsDocument30 pagesNotes 24 6382 Legendre FunctionsMohamed Al-OdatNo ratings yet
- Characterization of LipschitzDocument8 pagesCharacterization of LipschitzSufyanNo ratings yet
- Statistical Notes: 1 Normal Random VariableDocument5 pagesStatistical Notes: 1 Normal Random VariableNguyen HangNo ratings yet
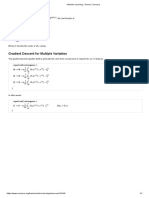
- Gradient Descent for Linear Regression: repeat until convergence: (:=:=) − α ( −) 1 ∑ − α ( ( −) ) 1 ∑Document1 pageGradient Descent for Linear Regression: repeat until convergence: (:=:=) − α ( −) 1 ∑ − α ( ( −) ) 1 ∑Laith BounenniNo ratings yet
- Boosting: I I I IDocument5 pagesBoosting: I I I ISNo ratings yet
- Statistics 580 Maximum Likelihood Estimation: 1 2 N 0 N 1 P 0 PDocument25 pagesStatistics 580 Maximum Likelihood Estimation: 1 2 N 0 N 1 P 0 PTawsif HasanNo ratings yet
- Ps 1Document25 pagesPs 1Khả UyênNo ratings yet
- Midterm 2010 SolutionsDocument8 pagesMidterm 2010 SolutionsErico ArchetiNo ratings yet
- Chapter Three: 3.2 Legendre Equation and Legendre PolynomialsDocument73 pagesChapter Three: 3.2 Legendre Equation and Legendre PolynomialsPatrick SibandaNo ratings yet
- CS229 Lecture 3 PDFDocument35 pagesCS229 Lecture 3 PDFAmr Abbas100% (1)
- 189 Cheat Sheet MinicardsDocument2 pages189 Cheat Sheet Minicardst rex422No ratings yet
- UniversityDocument2 pagesUniversitySudo27No ratings yet
- 2021 - w3 Math FoundationDocument24 pages2021 - w3 Math FoundationM. AnggaNo ratings yet
- Note 4: EECS 189 Introduction To Machine Learning Fall 2020 1 MLE and MAP For Regression (Part I)Document6 pagesNote 4: EECS 189 Introduction To Machine Learning Fall 2020 1 MLE and MAP For Regression (Part I)Rohan DebNo ratings yet
- Key - Maths - and - Physics - Notes (Jan24)Document5 pagesKey - Maths - and - Physics - Notes (Jan24)yunki.yauNo ratings yet
- 1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsDocument6 pages1 Lecture 5b: Probabilistic Perspectives On ML AlgorithmsJeremy WangNo ratings yet
- SVM Dual Problem ProofDocument2 pagesSVM Dual Problem ProofSat AdhaNo ratings yet
- Imaging SummaryDocument39 pagesImaging SummarylepenguinNo ratings yet
- AC-ED L04 - Logistic Regression, RegularizationDocument80 pagesAC-ED L04 - Logistic Regression, RegularizationAbel EspinNo ratings yet
- Assignment 1Document4 pagesAssignment 1PAPANo ratings yet
- Bayesian Methods - Home Exam: Dennis Uygur Andersson (Dean2175) 2021-10-19Document16 pagesBayesian Methods - Home Exam: Dennis Uygur Andersson (Dean2175) 2021-10-19Dennis Uygur AnderssonNo ratings yet
- BVP: Finite Differences or Method of Lines: Lecture #36: TA-Led Final ReviewDocument6 pagesBVP: Finite Differences or Method of Lines: Lecture #36: TA-Led Final ReviewEhsanMojtahediNo ratings yet
- Gradient Flow PDFDocument62 pagesGradient Flow PDFJhon Edison Bravo BuitragoNo ratings yet
- Chap5.4 HessianDocument15 pagesChap5.4 HessianabarniNo ratings yet
- Mid Term Solutions PDFDocument2 pagesMid Term Solutions PDFMd Nur-A-Adam DonyNo ratings yet
- Week5-LectureNotesDocument15 pagesWeek5-LectureNotesbarra alfaNo ratings yet
- DSP MidtermDocument4 pagesDSP MidtermRen Aldrin BobadillaNo ratings yet
- PegasosDocument4 pagesPegasosMelanie2023No ratings yet
- ML Lec 4Document38 pagesML Lec 4Saqlain ArshadNo ratings yet
- Opuscula Math 3205 PDFDocument8 pagesOpuscula Math 3205 PDFAntonio Torres PeñaNo ratings yet
- MATH207 - Assignment 1Document1 pageMATH207 - Assignment 1BinoNo ratings yet
- Massachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 4: SolutionsDocument8 pagesMassachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 4: Solutionsjuanagallardo01No ratings yet
- Video6 - Generating FunctionDocument5 pagesVideo6 - Generating Functionbig clapNo ratings yet
- The Fourier Transform and Its ApplicationsDocument4 pagesThe Fourier Transform and Its ApplicationsMurthyNo ratings yet
- Digital Image Processing - Sampling TheoryDocument56 pagesDigital Image Processing - Sampling TheoryLong Đặng HoàngNo ratings yet
- Signal Processing Review: 3.1 LTI SystemsDocument22 pagesSignal Processing Review: 3.1 LTI SystemsnctgayarangaNo ratings yet
- Signaalanalyse - College 5 - Properties of Continuous-Time Fourier TransformDocument11 pagesSignaalanalyse - College 5 - Properties of Continuous-Time Fourier TransformNick JanNo ratings yet
- Probabilistic Graphical Models CPSC 532c (Topics in AI) Stat 521a (Topics in Multivariate Analysis)Document35 pagesProbabilistic Graphical Models CPSC 532c (Topics in AI) Stat 521a (Topics in Multivariate Analysis)aofgubhNo ratings yet
- Lange TalkDocument40 pagesLange Talksanka csaatNo ratings yet
- مفاهيم 2ث علميDocument2 pagesمفاهيم 2ث علميDomaNo ratings yet
- Principles of CommunicationDocument42 pagesPrinciples of CommunicationSachin DoddamaniNo ratings yet
- 1 How Observables Generate Symmetries: Classical Mechanics, Lecture 10Document2 pages1 How Observables Generate Symmetries: Classical Mechanics, Lecture 10bgiangre8372No ratings yet
- V&N 354 - LectureLesing1Document4 pagesV&N 354 - LectureLesing1YemukelaniNo ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- Normal Equation: θ = (X X) X yDocument1 pageNormal Equation: θ = (X X) X yLaith BounenniNo ratings yet
- Gradient Descent Tips: X X X X XDocument1 pageGradient Descent Tips: X X X X XLaith BounenniNo ratings yet
- Gradient Descent for Linear Regression: repeat until convergence: (:=:=) − α ( −) 1 ∑ − α ( ( −) ) 1 ∑Document1 pageGradient Descent for Linear Regression: repeat until convergence: (:=:=) − α ( −) 1 ∑ − α ( ( −) ) 1 ∑Laith BounenniNo ratings yet
- Cost Function: y 2m 1 (Y ) 2m 1Document1 pageCost Function: y 2m 1 (Y ) 2m 1Laith BounenniNo ratings yet
- Support VectorDocument2 pagesSupport VectorLaith BounenniNo ratings yet