You might also like
- Matrix Calculus4mlDocument20 pagesMatrix Calculus4mlAlmog BendaNo ratings yet
- Dynamical Systems: Supplementary NotesDocument27 pagesDynamical Systems: Supplementary NotesRoy VeseyNo ratings yet
- 40 Functional Equations Problem 16 Solution - Adib HasanDocument1 page40 Functional Equations Problem 16 Solution - Adib HasanK. M. Junayed AhmedNo ratings yet
- Differential and Integral Calculus 2 - Homework 3 SolutionDocument6 pagesDifferential and Integral Calculus 2 - Homework 3 SolutionDominikNo ratings yet
- Solutions To Selected Exercises in Chapter TwoDocument31 pagesSolutions To Selected Exercises in Chapter TwoEDU CIPANANo ratings yet
- PSET-1 Sol PDFDocument3 pagesPSET-1 Sol PDFSarthak VoraNo ratings yet
- Chapter 4: Multiple Random VariablesDocument34 pagesChapter 4: Multiple Random VariablesMaximiliano OlivaresNo ratings yet
- Partial Derivatives ExplainedDocument37 pagesPartial Derivatives ExplainedNguyễnXuânNo ratings yet
- Big O Little O Notation and TaylorDocument7 pagesBig O Little O Notation and Taylorian_gibson44No ratings yet
- 7-Convex OptimizationDocument34 pages7-Convex OptimizationTuấn ĐỗNo ratings yet
- Hyperbolic Equations: 8.1 D'Alembert's SolutionDocument10 pagesHyperbolic Equations: 8.1 D'Alembert's Solutionrohit singhNo ratings yet
- 34 DerivativeProofsDocument30 pages34 DerivativeProofsapi-3738981No ratings yet
- Multiple IntegralsDocument25 pagesMultiple IntegralsAnshulNo ratings yet
- Algebra solutionsDocument9 pagesAlgebra solutionsNandhiniNo ratings yet
- Boundary Value ProblemsDocument14 pagesBoundary Value ProblemsBishnu LamichhaneNo ratings yet
- Introduction To Probability TheoryDocument13 pagesIntroduction To Probability TheoryarjunvenugopalacharyNo ratings yet
- Homework 3: X Z Y W X×Y X YDocument2 pagesHomework 3: X Z Y W X×Y X YLuis EduardoNo ratings yet
- ORF 523 Lecture on Convex FunctionsDocument14 pagesORF 523 Lecture on Convex FunctionsLuis Carlos RojanoNo ratings yet
- 265 F11 PT2 ASolnsDocument5 pages265 F11 PT2 ASolnsMartinho Moco OelNo ratings yet
- Econ 204 Problem Set 5 SolutionsDocument8 pagesEcon 204 Problem Set 5 SolutionsFunWithNumbers88No ratings yet
- Several Variable Differential Calculus: − ωt) representsDocument17 pagesSeveral Variable Differential Calculus: − ωt) representsPblock SaherNo ratings yet
- Math556 07 InequalitiesDocument7 pagesMath556 07 InequalitiesFrankie HuangNo ratings yet
- Numerical Integration: Msa / L-6 Cse-3512 - Numerical Methods 27 January, 2005Document3 pagesNumerical Integration: Msa / L-6 Cse-3512 - Numerical Methods 27 January, 2005Al Asad Nur RiyadNo ratings yet
- Solutions From The PutnamDocument4 pagesSolutions From The PutnamSai GokulNo ratings yet
- LIMITS AND CONTINUITYDocument4 pagesLIMITS AND CONTINUITYVetreivel KNo ratings yet
- Lec3 Convex Function ExerciseDocument4 pagesLec3 Convex Function Exercisezxm1485No ratings yet
- Problem Sheet 1Document2 pagesProblem Sheet 1Vivek SinhaNo ratings yet
- Lecture 4Document3 pagesLecture 4vinay PALNo ratings yet
- Eta H Convex Function MMDocument11 pagesEta H Convex Function MMLahore Regional Office PriceNo ratings yet
- Ross Elementary AnalysisDocument26 pagesRoss Elementary AnalysisVaibhav KumarNo ratings yet
- Langrange Multipliers PDFDocument8 pagesLangrange Multipliers PDFSehry SyedNo ratings yet
- Multivariable Linear Approximations & DifferentialsDocument9 pagesMultivariable Linear Approximations & DifferentialsExperimental BeXNo ratings yet
- 14 Partial DerivDocument26 pages14 Partial DerivEviVardakiNo ratings yet
- Implicit Function TheoremDocument4 pagesImplicit Function Theoremserialz dramazNo ratings yet
- Homotopy of Paths and Fundamental GroupDocument28 pagesHomotopy of Paths and Fundamental GroupEduar CastañedaNo ratings yet
- Problem Sheet 1Document2 pagesProblem Sheet 1Prateek sblNo ratings yet
- M110.3 Lec 1 - Polyomial RingsDocument5 pagesM110.3 Lec 1 - Polyomial RingsIsnihayaNo ratings yet
- EE376A/STATS376A Lecture 8 Channel Capacity and Continuous Random VariablesDocument6 pagesEE376A/STATS376A Lecture 8 Channel Capacity and Continuous Random Variablessanjay singhNo ratings yet
- STAT515 S19 Final ReviewproblemssolutionsDocument13 pagesSTAT515 S19 Final ReviewproblemssolutionsElias BeyeneNo ratings yet
- Proofs VI 3Document38 pagesProofs VI 3TOM DAVISNo ratings yet
- Lecture 05Document4 pagesLecture 05Damith ErangaNo ratings yet
- Calculus, Probability, and Statistics Primers: Dave GoldsmanDocument104 pagesCalculus, Probability, and Statistics Primers: Dave Goldsmanbanned minerNo ratings yet
- Week 3 Partial Derivatives, Chain Rule, Directional DerivativesDocument2 pagesWeek 3 Partial Derivatives, Chain Rule, Directional Derivativesstlonginus1942No ratings yet
- Section13 8Document10 pagesSection13 8rozemathNo ratings yet
- NUMERICAL Numerical Integration MethodsDocument10 pagesNUMERICAL Numerical Integration MethodsPratyush BarikNo ratings yet
- Rudin 5Document27 pagesRudin 5Cody SageNo ratings yet
- Unit VDocument20 pagesUnit Vapi-352822682No ratings yet
- Introduction to Differentiation: Find the DerivativeDocument14 pagesIntroduction to Differentiation: Find the DerivativeShafina Md ZanNo ratings yet
- IIT Madras Functions of Several Variables Exercise Set 1Document3 pagesIIT Madras Functions of Several Variables Exercise Set 1Kush Ganatra ch19b063No ratings yet
- UntitledDocument7 pagesUntitledAdrian CulicăNo ratings yet
- Homework 5: Solutions: (A) Find F and F When (X, Y) (0, 0)Document9 pagesHomework 5: Solutions: (A) Find F and F When (X, Y) (0, 0)Davidon JaniNo ratings yet
- M2C3 Solution of Algebraic and Transcendental Newton Raphson MethodDocument5 pagesM2C3 Solution of Algebraic and Transcendental Newton Raphson MethodRohit Kumar DasNo ratings yet
- HW6 SolutionsDocument4 pagesHW6 SolutionsJuan Carños Anaya BohorquezNo ratings yet
- 4.1 Motivation For Green's FunctionsDocument16 pages4.1 Motivation For Green's FunctionsfajesinNo ratings yet
- KKT conditions for convex optimizationDocument7 pagesKKT conditions for convex optimizationRupaj NayakNo ratings yet
- EE5143 Problem Set 1 practice problemsDocument4 pagesEE5143 Problem Set 1 practice problemsSarthak VoraNo ratings yet
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesFrom EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNo ratings yet
- Transformation of Axes (Geometry) Mathematics Question BankFrom EverandTransformation of Axes (Geometry) Mathematics Question BankRating: 3 out of 5 stars3/5 (1)
- E2 201: Information Theory (2019) Homework 4: Instructor: Himanshu TyagiDocument3 pagesE2 201: Information Theory (2019) Homework 4: Instructor: Himanshu Tyagis2211rNo ratings yet
- E2 201: Information Theory (2019) Homework 2: Instructor: Himanshu TyagiDocument2 pagesE2 201: Information Theory (2019) Homework 2: Instructor: Himanshu Tyagis2211rNo ratings yet
- New Text DocumentDocument1 pageNew Text Documents2211rNo ratings yet
- E2 201: Information Theory (2019) Homework 3: Instructor: Himanshu TyagiDocument2 pagesE2 201: Information Theory (2019) Homework 3: Instructor: Himanshu Tyagis2211rNo ratings yet
- E2 201: Information Theory (2019) Homework 3: Instructor: Himanshu TyagiDocument2 pagesE2 201: Information Theory (2019) Homework 3: Instructor: Himanshu Tyagis2211rNo ratings yet
- FFJGDocument1 pageFFJGs2211rNo ratings yet
- FFJGDocument1 pageFFJGs2211rNo ratings yet
- EEDocument1 pageEEs2211rNo ratings yet
- Introduction To Quantum Field Theory: Arthur Jaffe Harvard University Cambridge, MA 02138, USADocument137 pagesIntroduction To Quantum Field Theory: Arthur Jaffe Harvard University Cambridge, MA 02138, USAGustavo RondinaNo ratings yet
- CSDocument2 pagesCSs2211rNo ratings yet
- Introduction To Quantum Field Theory: Arthur Jaffe Harvard University Cambridge, MA 02138, USADocument137 pagesIntroduction To Quantum Field Theory: Arthur Jaffe Harvard University Cambridge, MA 02138, USAGustavo RondinaNo ratings yet
- FdhujdshDocument1 pageFdhujdshs2211rNo ratings yet
- Introduction To Quantum Field Theory: Arthur Jaffe Harvard University Cambridge, MA 02138, USADocument137 pagesIntroduction To Quantum Field Theory: Arthur Jaffe Harvard University Cambridge, MA 02138, USAGustavo RondinaNo ratings yet
- Phase Test I - FiitjeeDocument26 pagesPhase Test I - FiitjeeVanida NapoleonNo ratings yet
- BAUPC 2000 SolutionDocument8 pagesBAUPC 2000 Solutions2211rNo ratings yet
- Assignment 3: APSC 253 Fluid MechanicsDocument7 pagesAssignment 3: APSC 253 Fluid MechanicsDusty QueefNo ratings yet
- Student Workbook - Unit 2 - Understanding NumberDocument16 pagesStudent Workbook - Unit 2 - Understanding Numberapi-232099327100% (1)
- MATHS REVIEWDocument5 pagesMATHS REVIEWCristina AmantiadNo ratings yet
- Region-Based Convolutional Networks For Accurate Object Detection and SegmentationDocument21 pagesRegion-Based Convolutional Networks For Accurate Object Detection and SegmentationwdwdNo ratings yet
- MDM EverlynDocument15 pagesMDM EverlynSeth OderaNo ratings yet
- MonogramDocument2 pagesMonogramLaura Kallao KleckleyNo ratings yet
- Aeroservoelastic Modeling, Analysis, and Design Techniques PDFDocument12 pagesAeroservoelastic Modeling, Analysis, and Design Techniques PDFkarthekeyanmenonNo ratings yet
- Elitmus Guide - Guide To Solve Cryptic Multiplication QuestionDocument2 pagesElitmus Guide - Guide To Solve Cryptic Multiplication QuestionPraveen Pallav0% (1)
- ARS 131 & ARS 131.1Document33 pagesARS 131 & ARS 131.1Dave FortuNo ratings yet
- Muhammad Hassan Saeed-284223-Lab 6Document13 pagesMuhammad Hassan Saeed-284223-Lab 6Hassan SaeedNo ratings yet
- Database Management SystemsDocument19 pagesDatabase Management Systemsshreeya PatilNo ratings yet
- Budget LineDocument6 pagesBudget Linegyan|_vermaNo ratings yet
- NAPLAN 2011 Final Test Numeracy Year 7 CalculatorDocument13 pagesNAPLAN 2011 Final Test Numeracy Year 7 CalculatoraimanNo ratings yet
- Kirchhoff Love Plate Theory Wikipedia The Free EncyclopediaDocument12 pagesKirchhoff Love Plate Theory Wikipedia The Free EncyclopediajoneNo ratings yet
- Wheel Balancing Machine Inner SystemsDocument11 pagesWheel Balancing Machine Inner SystemsArmghan NaeemNo ratings yet
- Computational Mathematics and Physics of Fusion Reactors - Paul R. GarabedianDocument5 pagesComputational Mathematics and Physics of Fusion Reactors - Paul R. GarabediandougnovaesNo ratings yet
- Investment Decision Based On Entropy TheoryDocument18 pagesInvestment Decision Based On Entropy TheoryTiburcio MaldonadoNo ratings yet
- Bi Material BeamDocument22 pagesBi Material BeamPraveen KumaarNo ratings yet
- Wave HydrodynamicsDocument344 pagesWave HydrodynamicsSathishSrsNo ratings yet
- Assignment Problems For OsDocument4 pagesAssignment Problems For Osmanishbhavesh0% (1)
- DCF Analysis PDFDocument11 pagesDCF Analysis PDFanandbajaj0No ratings yet
- Constructing The Basic Bodice Block - OriginalDocument20 pagesConstructing The Basic Bodice Block - Originalpawan T100% (4)
- Role of Computer and Its Application in Scientific ResearchDocument11 pagesRole of Computer and Its Application in Scientific ResearchShinto Babu100% (1)
- Falling Ball Viscometer: Abhishek Suman Department of Energy Science and Engineering IIT BombayDocument12 pagesFalling Ball Viscometer: Abhishek Suman Department of Energy Science and Engineering IIT BombayPratham sehgalNo ratings yet
- Matlab Data TypesDocument5 pagesMatlab Data TypeskrishnagdeshpandeNo ratings yet
- Curriculum VitaeDocument4 pagesCurriculum VitaeTanveerNo ratings yet
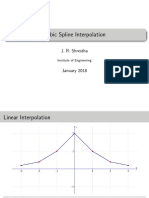
- Cubic Spline Interpolation: J. R. ShresthaDocument11 pagesCubic Spline Interpolation: J. R. ShresthaSashank GaudelNo ratings yet
- DFTDocument5 pagesDFTManojChowdaryNo ratings yet
- JavaScript: The Programming Language of the WebDocument15 pagesJavaScript: The Programming Language of the WebMary EcargNo ratings yet