You might also like
- Esaote FalcoDocument57 pagesEsaote FalcoPablo Ceretani50% (2)
- I7 ReportDocument20 pagesI7 ReportSethu ESNo ratings yet
- Jobo CPP2 ManualDocument83 pagesJobo CPP2 Manualron110nNo ratings yet
- Digital Design With HDLDocument29 pagesDigital Design With HDLw.nNo ratings yet
- Function Hooking For OSX and LinuxDocument127 pagesFunction Hooking For OSX and Linuxice799No ratings yet
- CSC3201 - Compiler Construction (Part II) - Lecture 5 - Code GenerationDocument64 pagesCSC3201 - Compiler Construction (Part II) - Lecture 5 - Code GenerationAhmad AbbaNo ratings yet
- Chapter2 Part3Document45 pagesChapter2 Part3Hồ Hương Vi ĐàoNo ratings yet
- Compiler Design - Code GenerationDocument62 pagesCompiler Design - Code Generationshanthi prabhaNo ratings yet
- 1 Davis Chisnall LLVM 2017Document166 pages1 Davis Chisnall LLVM 2017oreh2345No ratings yet
- Week 04Document68 pagesWeek 04aroosa naheedNo ratings yet
- Chapter 8 - Code GenerationDocument62 pagesChapter 8 - Code GenerationEkansh GuptaNo ratings yet
- Lecture 2 - Verilog HDL סונ ןמור) Web siteDocument92 pagesLecture 2 - Verilog HDL סונ ןמור) Web siteMack MastNo ratings yet
- Module 2 - Assemblers & Macro ProcessorDocument45 pagesModule 2 - Assemblers & Macro ProcessorSky JNo ratings yet
- Native Shader Compilation With LLVM PDFDocument37 pagesNative Shader Compilation With LLVM PDFthi minh phuong nguyenNo ratings yet
- Arm Instruction 2 - 001Document26 pagesArm Instruction 2 - 001Ankit SanghviNo ratings yet
- C Programming for Embedded SystemsDocument36 pagesC Programming for Embedded SystemsAbilashini jayakodyNo ratings yet
- EEE347 CNG336 Spring2017 Midterm2 - SLNDocument10 pagesEEE347 CNG336 Spring2017 Midterm2 - SLNEmre OnursoyNo ratings yet
- Lecture Slide 4Document48 pagesLecture Slide 4Sunil SahooNo ratings yet
- Unit 1 Lect 2,3Document20 pagesUnit 1 Lect 2,3Cse312 B. PraveenNo ratings yet
- Code OptiDocument26 pagesCode Optipad pestNo ratings yet
- Avoiding RTL Mistakespdf PDFDocument4 pagesAvoiding RTL Mistakespdf PDFAbhijeet SaNo ratings yet
- Pipeline - Instr - Super BranchDocument48 pagesPipeline - Instr - Super BranchSHEENA YNo ratings yet
- Unit 2 Mcu PDFDocument12 pagesUnit 2 Mcu PDFatulNo ratings yet
- 計組考古Document13 pages計組考古e24114100No ratings yet
- CP Lectures - 2Document176 pagesCP Lectures - 2Muhammad TariqNo ratings yet
- Floating Point Multipliers: Simulation & Synthesis Using VHDLDocument40 pagesFloating Point Multipliers: Simulation & Synthesis Using VHDLmdzakir_hussainNo ratings yet
- Low Level C ProgrammingDocument49 pagesLow Level C Programmingmspereira100% (1)
- 04 AVR ALU and SREG SetDocument12 pages04 AVR ALU and SREG SetDerbendeNo ratings yet
- What Are The Differences Between SIMULATION and SYNTHESISDocument12 pagesWhat Are The Differences Between SIMULATION and SYNTHESISiyanduraiNo ratings yet
- The Register Set of Msp430x5x SeriesDocument2 pagesThe Register Set of Msp430x5x SeriesTwinkle RatnaNo ratings yet
- Serial Communications: 2 Flavors: SynchronousDocument29 pagesSerial Communications: 2 Flavors: SynchronousNguyễn Trịnh Thành VinhNo ratings yet
- Computer Architecture - Floating Point LabDocument10 pagesComputer Architecture - Floating Point LabSok VyNo ratings yet
- Branching and Looping TechniquesDocument17 pagesBranching and Looping TechniquesioleNo ratings yet
- Introduction To SynthesisDocument39 pagesIntroduction To SynthesisJayanth bemesettyNo ratings yet
- Introduction To Compilers: Jun.-Prof. Dr. Christian Plessl Custom Computing University of PaderbornDocument51 pagesIntroduction To Compilers: Jun.-Prof. Dr. Christian Plessl Custom Computing University of PaderbornHariharan ElangandhiNo ratings yet
- C Programming in AVRDocument42 pagesC Programming in AVRرضا میرزانیاNo ratings yet
- ps1 SolDocument11 pagesps1 SolpradsepNo ratings yet
- Verilog UBCDocument29 pagesVerilog UBCsalNo ratings yet
- Spark V Exp 6Document10 pagesSpark V Exp 6yogeshNo ratings yet
- Dtrace Internals x86Document22 pagesDtrace Internals x86Bangari NaiduNo ratings yet
- Ca Lec4Document20 pagesCa Lec4Sana IftikharNo ratings yet
- ARM Instruction Set PDFDocument124 pagesARM Instruction Set PDFhod elnNo ratings yet
- Computer Architectures Parameters and System CallsDocument31 pagesComputer Architectures Parameters and System CallsPaculoNo ratings yet
- Design With Microprocessors: Year III Computer Science 1-st Semester Lecture 2: AVR Registers and InstructionsDocument26 pagesDesign With Microprocessors: Year III Computer Science 1-st Semester Lecture 2: AVR Registers and InstructionsSelmaGogaNo ratings yet
- Constant propagation and foldingDocument16 pagesConstant propagation and foldingF e e l i n g s অ নু ভূ তিNo ratings yet
- ProblemDescriptionDocument13 pagesProblemDescriptionShivani MisraNo ratings yet
- Verilog: - A IEEE Standard Hardware Descriptive LanguageDocument32 pagesVerilog: - A IEEE Standard Hardware Descriptive LanguageS Dinuka MadhushanNo ratings yet
- Continuous & Discreate Control SystemsDocument71 pagesContinuous & Discreate Control Systemssatishdanu5955No ratings yet
- Unit - 5 8 Hours Interfacing Programming in C - 2: Pin DescriptionDocument25 pagesUnit - 5 8 Hours Interfacing Programming in C - 2: Pin DescriptionHarshith Gowda RNo ratings yet
- Verilog Coding Guideline: Author: TrumenDocument51 pagesVerilog Coding Guideline: Author: TrumenNK NKNo ratings yet
- Chapter 3: Introduction To Assembly Language Programming: CEG2400 - Microcomputer SystemsDocument57 pagesChapter 3: Introduction To Assembly Language Programming: CEG2400 - Microcomputer SystemsRANJITHANo ratings yet
- Lab Sheet For Chapter 9Document26 pagesLab Sheet For Chapter 9karnsushantlalNo ratings yet
- Ece4750 T01 Proc Concepts ProblemsDocument10 pagesEce4750 T01 Proc Concepts Problemssolf jacobNo ratings yet
- Exp4 RTL Inv Fanout Nor NandDocument9 pagesExp4 RTL Inv Fanout Nor NandJohn wickNo ratings yet
- VHDL Exam, Spring 2008 Solution SetDocument6 pagesVHDL Exam, Spring 2008 Solution Setjoshuacool4No ratings yet
- An Instructional Processor Design Using VHDL and An FpgaDocument10 pagesAn Instructional Processor Design Using VHDL and An FpgaRezwan KhanNo ratings yet
- Synthesizable VHDL Slides AyonDocument39 pagesSynthesizable VHDL Slides AyonSreeja DasNo ratings yet
- EncoderDocument5 pagesEncoderTai VovanNo ratings yet
- Projects With Microcontrollers And PICCFrom EverandProjects With Microcontrollers And PICCRating: 5 out of 5 stars5/5 (1)
- CISCO PACKET TRACER LABS: Best practice of configuring or troubleshooting NetworkFrom EverandCISCO PACKET TRACER LABS: Best practice of configuring or troubleshooting NetworkNo ratings yet
- WAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksFrom EverandWAN TECHNOLOGY FRAME-RELAY: An Expert's Handbook of Navigating Frame Relay NetworksNo ratings yet
- Halide 12. Image ProcessingDocument12 pagesHalide 12. Image ProcessingKeithNo ratings yet
- Nvidia Smi.1Document17 pagesNvidia Smi.1shakabrahNo ratings yet
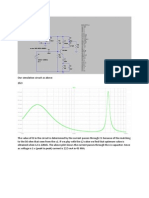
- Our Simulation Circuit As AboveDocument5 pagesOur Simulation Circuit As AboveotutayNo ratings yet
- FPGA MethodologyDocument64 pagesFPGA MethodologyotutayNo ratings yet
- 24-Bit Analog-to-Digital Converter For Bridge Sensors: Features DescriptionDocument37 pages24-Bit Analog-to-Digital Converter For Bridge Sensors: Features DescriptionotutayNo ratings yet
- PSpice TutorialDocument30 pagesPSpice TutorialMurali SriramNo ratings yet
- COA Unit 1Document33 pagesCOA Unit 1Keshav NaganathanNo ratings yet
- Build A High-Performance Object Storage-as-a-Service Platform With MinioDocument13 pagesBuild A High-Performance Object Storage-as-a-Service Platform With MinioZoumana DiomandeNo ratings yet
- Computer Organization and Architecture: Prepared By: Ayanle AbubakarDocument18 pagesComputer Organization and Architecture: Prepared By: Ayanle AbubakarAyaanle Abubakar MohamedNo ratings yet
- Intel® Core™ I5-5200u Processor: EssentialsDocument6 pagesIntel® Core™ I5-5200u Processor: EssentialsRICHO DIANA AVIYANTINo ratings yet
- GE VersaMax Workshop Student GuideDocument83 pagesGE VersaMax Workshop Student GuideLeo BurnsNo ratings yet
- Processors For Mobile ApplicationsDocument6 pagesProcessors For Mobile Applicationsusamadar707No ratings yet
- Jyothishmathi Institute of Technology & Science: Unit V ARM Cortex-M3 ProcessorDocument4 pagesJyothishmathi Institute of Technology & Science: Unit V ARM Cortex-M3 ProcessorhasikaNo ratings yet
- The Central Processing UnitDocument4 pagesThe Central Processing UnitCharmis TubilNo ratings yet
- MPC7448 RISC Microprocessor Hardware Specifications: Freescale SemiconductorDocument60 pagesMPC7448 RISC Microprocessor Hardware Specifications: Freescale SemiconductorMurat GörükmezNo ratings yet
- The LC-3b ISA: 1.1 OverviewDocument23 pagesThe LC-3b ISA: 1.1 OverviewVan ChanNo ratings yet
- CAO 2018 T3 Question PaperDocument2 pagesCAO 2018 T3 Question Paperharsh guptaNo ratings yet
- 8086 Lab manual-DTU PDFDocument46 pages8086 Lab manual-DTU PDFsivakumarNo ratings yet
- SAP HANA Developer Guide (English)Document392 pagesSAP HANA Developer Guide (English)javierfacesNo ratings yet
- MPMC (r15) Unit 1bDocument89 pagesMPMC (r15) Unit 1bRAVICHANDRA KILARUNo ratings yet
- Computer Architecture - CS252Document2 pagesComputer Architecture - CS252Asghar Hussain ShahNo ratings yet
- TERBARU Materi Ajar BARU ImelDocument28 pagesTERBARU Materi Ajar BARU ImelYukee LoeNo ratings yet
- Computing 3.1Document2 pagesComputing 3.1Sashank AryalNo ratings yet
- Basic Principles of Electronic ExchangesDocument12 pagesBasic Principles of Electronic ExchangesAryamn ProstNo ratings yet
- Atmel - AT32UC3A Series - AVR32 RISC 32-Bit Micro Controller (Doc32058)Document826 pagesAtmel - AT32UC3A Series - AVR32 RISC 32-Bit Micro Controller (Doc32058)Jose SantosNo ratings yet
- S71500 TM Npu Manual en-US en-USDocument32 pagesS71500 TM Npu Manual en-US en-USAkhilNo ratings yet
- Sysmac NJ FINS TechnicalGuide en 201205 W518-E1-01Document40 pagesSysmac NJ FINS TechnicalGuide en 201205 W518-E1-01Luigi FaccioNo ratings yet
- DC16 Ch06Document36 pagesDC16 Ch06Alvin SanjayaNo ratings yet
- FPL2 QUESTIONS BANK WITH ANSWERSDocument172 pagesFPL2 QUESTIONS BANK WITH ANSWERSMAHESH SINGHNo ratings yet
- SV MAY 20-26 Deployment and CISS1632081176Document33 pagesSV MAY 20-26 Deployment and CISS1632081176Justine CañoNo ratings yet
- Microcontrollers Explained: Components, Programming & ApplicationsDocument34 pagesMicrocontrollers Explained: Components, Programming & ApplicationsFaridNo ratings yet
- Advances in Computers, Vol.59 (AP, 2003) (ISBN 9780120121595) (O) (308s) - CsAlDocument308 pagesAdvances in Computers, Vol.59 (AP, 2003) (ISBN 9780120121595) (O) (308s) - CsAlRAREȘ-ANDREI NITUNo ratings yet
- DMT FormatDocument13 pagesDMT FormatsyediliyassikandarNo ratings yet