You might also like
- Auth0 A Cloud Guru Case StudyDocument6 pagesAuth0 A Cloud Guru Case Studysrik37No ratings yet
- Mrprintables Alphabet Flashcards Extra Words CardsDocument1 pageMrprintables Alphabet Flashcards Extra Words Cardssrik37No ratings yet
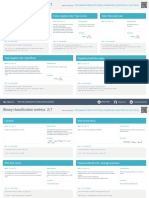
- Binary ClassificationMetrics CheathsheetDocument7 pagesBinary ClassificationMetrics CheathsheetPedro PereiraNo ratings yet
- 2020 University of Bradford OfS Funded Scholarships For MSC in AIDA Guidance Notes 19082020Document5 pages2020 University of Bradford OfS Funded Scholarships For MSC in AIDA Guidance Notes 19082020srik37No ratings yet
- Nicolaides The 11-13 Weeks Scan 2004Document113 pagesNicolaides The 11-13 Weeks Scan 2004ScopulovicNo ratings yet
- Benefits of Single Ci CDDocument9 pagesBenefits of Single Ci CDVinay DesaiNo ratings yet
- CBP Study GuideDocument24 pagesCBP Study Guidenatecv890% (10)
- 15-10-27 MK City CentreDocument32 pages15-10-27 MK City Centresrik37No ratings yet
- Text Analytics Using Oracle Text: Roger FordDocument27 pagesText Analytics Using Oracle Text: Roger Fordsrik37No ratings yet
- MR Srikanth Gedela TDDWLVJD: Driving Status EndorsementsDocument1 pageMR Srikanth Gedela TDDWLVJD: Driving Status Endorsementssrik37No ratings yet
- Storage Special Report 7 OpenStack PDFDocument11 pagesStorage Special Report 7 OpenStack PDFsrik37No ratings yet
- RCDocument5 pagesRCAnonymous lfw4mfCmNo ratings yet
- Joe O Business PlanDocument21 pagesJoe O Business Plansrik37No ratings yet
- Gowri PowranamiDocument5 pagesGowri Powranamisrik37No ratings yet
- Introduction Cloud Computing Canonical UbuntuDocument9 pagesIntroduction Cloud Computing Canonical Ubuntusrik37No ratings yet
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- List of All The Mods I Installed in This VideoDocument2 pagesList of All The Mods I Installed in This VideoSheharyar The PRONo ratings yet
- Business It Alignment Master ThesisDocument4 pagesBusiness It Alignment Master Thesisgbwav8m4100% (2)
- NoSQL Solutions (MCQ & Structural)Document12 pagesNoSQL Solutions (MCQ & Structural)massablaisetamfuNo ratings yet
- Programming Real-Time Systems With C/C++ and POSIX: Michael González HarbourDocument9 pagesProgramming Real-Time Systems With C/C++ and POSIX: Michael González HarbourgoutambiswaNo ratings yet
- MySQL Security - 2019v2-2Document71 pagesMySQL Security - 2019v2-2abdiel AlveoNo ratings yet
- 1.money ConversionDocument64 pages1.money ConversionKeerthana RNo ratings yet
- 8-Bit Microcontrollers With OSD and VST 84C44X 84C64X 84C84XDocument38 pages8-Bit Microcontrollers With OSD and VST 84C44X 84C64X 84C84XBalajiNo ratings yet
- AI Based ProctoringDocument4 pagesAI Based ProctoringmedhaNo ratings yet
- Mathematics Paper 1 TZ1 SL PDFDocument12 pagesMathematics Paper 1 TZ1 SL PDFYacine100% (1)
- Implementationof Fuzzy Tsukamoto Algorithmin Determining Work FeasibilityDocument5 pagesImplementationof Fuzzy Tsukamoto Algorithmin Determining Work Feasibilitydikson piterNo ratings yet
- Core Architecture Slides Student Hand Out April 20191559592462009Document125 pagesCore Architecture Slides Student Hand Out April 20191559592462009Hariprasad ReddyNo ratings yet
- Integrating With HCMDocument588 pagesIntegrating With HCMbalabalabala123No ratings yet
- What Is Quickbooks Database Server Manager Network Diagnostics Failed ErrorDocument5 pagesWhat Is Quickbooks Database Server Manager Network Diagnostics Failed Errorandrewmoore01No ratings yet
- Arjun's Resume-1Document2 pagesArjun's Resume-1bdm codegenitNo ratings yet
- Lab-2-Course Matlab Manual For LCSDocument12 pagesLab-2-Course Matlab Manual For LCSAshno KhanNo ratings yet
- XOM02 Vlocity Order Managment Overview EG v8.0.1Document36 pagesXOM02 Vlocity Order Managment Overview EG v8.0.1Alexandre100% (1)
- Oilon Duoblock Burners For Liquid and Gaseous FuelsDocument94 pagesOilon Duoblock Burners For Liquid and Gaseous FuelsDian PriengadiNo ratings yet
- Site Save of CodeSlinger - Co.uk - GameBoy Emulator Programming in C++ - MemoryDocument3 pagesSite Save of CodeSlinger - Co.uk - GameBoy Emulator Programming in C++ - MemoryRyanNo ratings yet
- MNG3702 Study Guide 2023Document128 pagesMNG3702 Study Guide 2023Neferu MadzTwalNo ratings yet
- Cloud StreamingDocument2 pagesCloud StreamingInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Monthly Calendar Template: Step 1Document14 pagesMonthly Calendar Template: Step 1glydelletan kimNo ratings yet
- Preserving The Traditions of The Masters: Observational ColorDocument5 pagesPreserving The Traditions of The Masters: Observational ColorTrungVũNguyễn100% (1)
- Enterprise Information Systems Project Implementation: A Case Study of ERP in Rolls-RoyceDocument22 pagesEnterprise Information Systems Project Implementation: A Case Study of ERP in Rolls-Roycesandyjbs100% (1)
- Graduate Trainee 2023 - Asia Pulp & Paper (Sinar Mas)Document4 pagesGraduate Trainee 2023 - Asia Pulp & Paper (Sinar Mas)Gege MarhaendraNo ratings yet
- Improving Android Bootup Time: Tim Bird Sony Network Entertainment, IncDocument40 pagesImproving Android Bootup Time: Tim Bird Sony Network Entertainment, IncDelwar Hossain100% (1)
- Tugas Gui Lanjutan Dan SPLDocument8 pagesTugas Gui Lanjutan Dan SPLDewi KurniaNo ratings yet
- CNT 100 - Introduction To Windows Networking Syllabus: Instructor: Email: Phone: Office: Office Hours: Course OverviewDocument5 pagesCNT 100 - Introduction To Windows Networking Syllabus: Instructor: Email: Phone: Office: Office Hours: Course OverviewColleen VenderNo ratings yet
- BCSL056Document25 pagesBCSL056r06677624No ratings yet
- Eng 7 Pre Test Sy 2023-2024Document9 pagesEng 7 Pre Test Sy 2023-2024rachel reparepNo ratings yet
- Republic of The Philippines Social Security System MemberDocument1 pageRepublic of The Philippines Social Security System MemberMaeNo ratings yet