You might also like
- Numerical Modelling of Soil Nails in Loose Fill SlopesDocument14 pagesNumerical Modelling of Soil Nails in Loose Fill SlopesRivaiNo ratings yet
- Computers and Geotechnics: Pengpeng Ni, Sujith Mangalathu, Guoxiong Mei, Yanlin ZhaoDocument10 pagesComputers and Geotechnics: Pengpeng Ni, Sujith Mangalathu, Guoxiong Mei, Yanlin ZhaoManaswini VadlamaniNo ratings yet
- Parametric Finite Element Analyses of Geocell-Supported EmbankmentsDocument12 pagesParametric Finite Element Analyses of Geocell-Supported EmbankmentsCelal ÜnalNo ratings yet
- Content ServerDocument18 pagesContent ServerYUMIRA LESLY CAMAYO ROMERONo ratings yet
- ART20174885Document6 pagesART20174885Ahmed Abd el shakourNo ratings yet
- 2geocell Reinorced Subballast - Cyclic Loading2 - BudhimaDocument15 pages2geocell Reinorced Subballast - Cyclic Loading2 - BudhimaManaswini VadlamaniNo ratings yet
- Prediction of Settlement Trough Induced by Tunneling in Cohesive GroundDocument16 pagesPrediction of Settlement Trough Induced by Tunneling in Cohesive GroundRoberto Chacon AlvarezNo ratings yet
- Effects of Rainfall Infiltration and Hysteresis On PDFDocument13 pagesEffects of Rainfall Infiltration and Hysteresis On PDFRehan HakroNo ratings yet
- Ocean Engineering: G. Chortis, A. Askarinejad, L.J. Prendergast, Q. Li, K. GavinDocument12 pagesOcean Engineering: G. Chortis, A. Askarinejad, L.J. Prendergast, Q. Li, K. GavinSHNo ratings yet
- Prediction of Settlement in Natural Deposited Clay Ground With Risk of Large Residual Settlement Due To Embankment LoadingDocument17 pagesPrediction of Settlement in Natural Deposited Clay Ground With Risk of Large Residual Settlement Due To Embankment LoadingCEG BangladeshNo ratings yet
- Computers and Geotechnics: You Wang, Jingpei Li, Lin Li TDocument10 pagesComputers and Geotechnics: You Wang, Jingpei Li, Lin Li Tzimbazimba75No ratings yet
- In Uence of Groundwater On The Bearing Capacity of Shallow FoundationsDocument11 pagesIn Uence of Groundwater On The Bearing Capacity of Shallow FoundationsDipankar NathNo ratings yet
- Three-Dimensional Numerical Study of Long-Term Settlement Induced inDocument16 pagesThree-Dimensional Numerical Study of Long-Term Settlement Induced inHaha ZazaNo ratings yet
- 1 s2.0 S0141118721004326 MainDocument30 pages1 s2.0 S0141118721004326 MainhadiNo ratings yet
- Investigation of Tunnel-Soil-Pile Interaction in Cohesive SoilsDocument7 pagesInvestigation of Tunnel-Soil-Pile Interaction in Cohesive SoilsAsep ArdiantoNo ratings yet
- Drainage200602 PDFDocument11 pagesDrainage200602 PDFyaraNo ratings yet
- Soil-Nonwoven Geotextile Filtration Behavior Under Contact With Drainage MaterialsDocument11 pagesSoil-Nonwoven Geotextile Filtration Behavior Under Contact With Drainage MaterialsyaraNo ratings yet
- Centridge Modeling of Embankment On Clay FoundationDocument18 pagesCentridge Modeling of Embankment On Clay Foundationmr yugiNo ratings yet
- Design of Single Pile Foundations Using The Mechanics of UnsaturatedDocument9 pagesDesign of Single Pile Foundations Using The Mechanics of Unsaturateddhan singhNo ratings yet
- Killeen 2014Document17 pagesKilleen 2014Eman AhmedNo ratings yet
- Kinematic Bending of Pile Foundations On Layered Liquefiable SoilsDocument9 pagesKinematic Bending of Pile Foundations On Layered Liquefiable SoilsChin Kit YeeNo ratings yet
- Vertical DrainDocument15 pagesVertical DrainSyahbani EkaNo ratings yet
- Driven Piles in Clay-The Effects of Installation and Subsequent ConsolidationDocument33 pagesDriven Piles in Clay-The Effects of Installation and Subsequent ConsolidationMahn NguyenNo ratings yet
- Jgeot 15 P 035 PDFDocument15 pagesJgeot 15 P 035 PDFEvers Quispe CallasacaNo ratings yet
- Articulo N°1Document13 pagesArticulo N°1José Luis Pacheco RocaNo ratings yet
- Pullout of Soil Nail With Circular Discs A - 2017 - Journal of Rock Mechanics ADocument14 pagesPullout of Soil Nail With Circular Discs A - 2017 - Journal of Rock Mechanics AVassilis PentheroudakisNo ratings yet
- Burd Frydman 1997Document14 pagesBurd Frydman 1997michgebNo ratings yet
- Evaluating The Liquefaction Potential of Gravel Soils With Static Experiments and Steady State ApproachesDocument11 pagesEvaluating The Liquefaction Potential of Gravel Soils With Static Experiments and Steady State ApproachesLin WangNo ratings yet
- SoilArching Liang Zeng 2002Document10 pagesSoilArching Liang Zeng 2002ensirin61No ratings yet
- 2023 - NG Et Al - Influence of Aggregate Structure On The Compressibility Silt SandDocument15 pages2023 - NG Et Al - Influence of Aggregate Structure On The Compressibility Silt SandnsanieleNo ratings yet
- Inclined Pull-Out Capacity of Suction Caisson Embedded in SandDocument10 pagesInclined Pull-Out Capacity of Suction Caisson Embedded in SandDang Quang MinhNo ratings yet
- Dynamic Stiffness of Horizonally Vibrating Suction CaissonsDocument11 pagesDynamic Stiffness of Horizonally Vibrating Suction CaissonsDang Quang MinhNo ratings yet
- Effect of Embedment On The Vertical Capacity of Bucket Foundation in Loose Saturated Sand: Physical ModelingDocument10 pagesEffect of Embedment On The Vertical Capacity of Bucket Foundation in Loose Saturated Sand: Physical ModelingATISH KUMAR DASNo ratings yet
- The Experimental Study of Eccentric Loadingfor Piled Raft Foundations Settling On Slope CrestDocument5 pagesThe Experimental Study of Eccentric Loadingfor Piled Raft Foundations Settling On Slope CrestInnovative Research PublicationsNo ratings yet
- Journal of Rock Mechanics and Geotechnical Engineering: Saurabh Rawat, Ashok Kumar GuptaDocument11 pagesJournal of Rock Mechanics and Geotechnical Engineering: Saurabh Rawat, Ashok Kumar GuptaHari RamNo ratings yet
- Engineering Geology: T.A.V. Gaspar, S.W. Jacobsz, G. Heymann, D.G. Toll, A. Gens, A.S. OsmanDocument11 pagesEngineering Geology: T.A.V. Gaspar, S.W. Jacobsz, G. Heymann, D.G. Toll, A. Gens, A.S. OsmanMd. Mehedi Hasan PolashNo ratings yet
- Efecto Arco Horizontal Plaxis 3DDocument6 pagesEfecto Arco Horizontal Plaxis 3Dmagnusmagnus1No ratings yet
- Finite Element Modeling of Inclined Load Capacity of Suction Caisson in Sand With Abaqus-ExplicitDocument7 pagesFinite Element Modeling of Inclined Load Capacity of Suction Caisson in Sand With Abaqus-ExplicitDang Quang MinhNo ratings yet
- The Design of Stone Column Applications To Protect Against Soil LiquefactionDocument11 pagesThe Design of Stone Column Applications To Protect Against Soil LiquefactionMarco Dos Santos NevesNo ratings yet
- Mecanica de SuelosDocument8 pagesMecanica de SuelosNayla Tito SánchezNo ratings yet
- Wang 2016Document10 pagesWang 2016Ivan BenitesNo ratings yet
- Comparison Between Unit Cell and Plane Strain Models of Stone Column Ground ImprovementDocument8 pagesComparison Between Unit Cell and Plane Strain Models of Stone Column Ground Improvementseif17No ratings yet
- Undrained Bearing Capacity of Ring Foundations on Two-Layered ClaysDocument11 pagesUndrained Bearing Capacity of Ring Foundations on Two-Layered ClaysInsaf SaifiNo ratings yet
- 10 18038-Aubtda 376144-479554Document15 pages10 18038-Aubtda 376144-479554nimabsnNo ratings yet
- Analytical Solution For Radial Consolidation Considering SoilDocument15 pagesAnalytical Solution For Radial Consolidation Considering SoilAnonymous VJHwe0XBNo ratings yet
- 2 - Design of Geocell Foundation For Embankment - Sitharam - 2013Document9 pages2 - Design of Geocell Foundation For Embankment - Sitharam - 2013Vetriselvan ArumugamNo ratings yet
- 79-Article Text-432-1-10-20190501Document9 pages79-Article Text-432-1-10-20190501smit_ghoseNo ratings yet
- 9578-Article Text PDF-24555-2-10-20170623Document13 pages9578-Article Text PDF-24555-2-10-20170623michgebNo ratings yet
- Cicek 2015Document17 pagesCicek 20152020CEM009 QUAMARTABISHNo ratings yet
- Modelling of Prefabricated Vertical Drains in Soft Clay and Evaluation of Their Effectiveness in PracticeDocument11 pagesModelling of Prefabricated Vertical Drains in Soft Clay and Evaluation of Their Effectiveness in PracticeHUGINo ratings yet
- Response of Skirted Strip Footing Resting On Layered Granular Soil Using 2 D Plane Strain Finite Element ModelingDocument16 pagesResponse of Skirted Strip Footing Resting On Layered Granular Soil Using 2 D Plane Strain Finite Element Modelinghaluk soyluNo ratings yet
- Selectionof Modulusand DampingDocument5 pagesSelectionof Modulusand DampingNicolas Arancibia MartinezNo ratings yet
- Shaft Configuration and Bearing Capacity of Pile Foundation: T. W. Adejumo, I. L. BoikoDocument9 pagesShaft Configuration and Bearing Capacity of Pile Foundation: T. W. Adejumo, I. L. BoikoDaniel Castro ArroyoNo ratings yet
- Friction Fatigue On Displacement Piles in SandDocument15 pagesFriction Fatigue On Displacement Piles in SandParvatha Vardhan GandrakotaNo ratings yet
- Research PaperDocument6 pagesResearch PaperFaran MalikNo ratings yet
- Computers and Geotechnics: Fayun Liang, Zhu Song, Wei Dong GuoDocument10 pagesComputers and Geotechnics: Fayun Liang, Zhu Song, Wei Dong GuoPaloma CortizoNo ratings yet
- A Study On Piled Raft FoundationDocument7 pagesA Study On Piled Raft FoundationCostas SachpazisNo ratings yet
- The Undrained Vertical Bearing Capacity of Skirted FoundationsDocument14 pagesThe Undrained Vertical Bearing Capacity of Skirted Foundationsht walidNo ratings yet
- Investigation On Geogrid Reinforcement and Pile Efficacy in Geosynthetic-Reinforced Pile-Supported Track-BedDocument12 pagesInvestigation On Geogrid Reinforcement and Pile Efficacy in Geosynthetic-Reinforced Pile-Supported Track-BedMustafa LuayNo ratings yet
- An Introduction To FE Analysis With Excel-VBA: Kyanase@fukuoka-U.ac - JPDocument15 pagesAn Introduction To FE Analysis With Excel-VBA: Kyanase@fukuoka-U.ac - JPChangbum YuNo ratings yet
- Theoretical Approach: Installation of Offshore Driven Piles - Regional ExperienceDocument1 pageTheoretical Approach: Installation of Offshore Driven Piles - Regional ExperiencetehNo ratings yet
- Installation of Offshore Driven Piles - Regional Experience: View Publication Stats View Publication StatsDocument1 pageInstallation of Offshore Driven Piles - Regional Experience: View Publication Stats View Publication StatstehNo ratings yet
- Installation of Offshore Driven Piles - Regional Experience: August 2012Document2 pagesInstallation of Offshore Driven Piles - Regional Experience: August 2012tehNo ratings yet
- Installation of Offshore Driven Piles - Regional Experience: August 2012Document1 pageInstallation of Offshore Driven Piles - Regional Experience: August 2012tehNo ratings yet
- Highway Structures: Design (Substructures and Special Structures), Materials Section 1 SubstructuresDocument26 pagesHighway Structures: Design (Substructures and Special Structures), Materials Section 1 SubstructurestehNo ratings yet
- Bored PileDocument74 pagesBored PileGan Wei HuangNo ratings yet
- Construction On Soft SoilDocument82 pagesConstruction On Soft SoilDyah Chandra Kartika Sesunan100% (1)
- PTP2-900mm Test Report-KL Sentral Riveria BrickfieldsDocument32 pagesPTP2-900mm Test Report-KL Sentral Riveria BrickfieldstehNo ratings yet
- Two-Dimensional Analysis of TheDocument81 pagesTwo-Dimensional Analysis of Theshachen2014No ratings yet
- ISRM Revises Point Load Test MethodDocument10 pagesISRM Revises Point Load Test MethodkatherineNo ratings yet
- Gabion Retaining Wall Analysis and Design (Bs8002:1994) : Project Job NoDocument3 pagesGabion Retaining Wall Analysis and Design (Bs8002:1994) : Project Job NotehNo ratings yet
- Pile-Driving Analysis by One-Dimensional Wave TheoryDocument22 pagesPile-Driving Analysis by One-Dimensional Wave TheorytehNo ratings yet
- Python BookDocument194 pagesPython Bookteh100% (1)
- Lecture No. 4: Dr. Warakorn Mairaing Associate ProfessorDocument72 pagesLecture No. 4: Dr. Warakorn Mairaing Associate ProfessortehNo ratings yet
- Interpretations of Instrumented Bored Piles in Kenny Hill FormationDocument8 pagesInterpretations of Instrumented Bored Piles in Kenny Hill Formationtangkokhong100% (1)
- Underpinning FoundationsDocument40 pagesUnderpinning FoundationsDaniel Joseph100% (2)
- The Failure of Carsington Dam: G&technique 43, No. 1, 151-173Document23 pagesThe Failure of Carsington Dam: G&technique 43, No. 1, 151-173tehNo ratings yet
- Since 1997, Your Complete Online Resource For Information Geotecnical Engineering and Deep FoundationsDocument71 pagesSince 1997, Your Complete Online Resource For Information Geotecnical Engineering and Deep FoundationstehNo ratings yet
- Soil-Cement Mixture Properties and Design Considerations For Reinforced ExcavationDocument8 pagesSoil-Cement Mixture Properties and Design Considerations For Reinforced ExcavationtehNo ratings yet
- British Soil Classification System For Engineering PurposesDocument4 pagesBritish Soil Classification System For Engineering PurposestehNo ratings yet
- Soil Nailing With Flexible Structural Facing - Design and ExpDocument6 pagesSoil Nailing With Flexible Structural Facing - Design and ExptehNo ratings yet
- 287B - PB - 4out - Same - 50835 - ASCE - Vol - 01 - Final - Job - Process Cyan - 08/07/2012 - 05:31:52Document11 pages287B - PB - 4out - Same - 50835 - ASCE - Vol - 01 - Final - Job - Process Cyan - 08/07/2012 - 05:31:52tehNo ratings yet
- Applicability of Molding Procedures in Laboratory Mix Tests For Quality Control and Assurance of The Deep Mixing MethodDocument17 pagesApplicability of Molding Procedures in Laboratory Mix Tests For Quality Control and Assurance of The Deep Mixing MethodtehNo ratings yet
- Quality Assessment and Quality Control of Deep Soil Mixing Construction For Stabilizing Expansive SubsoilsDocument10 pagesQuality Assessment and Quality Control of Deep Soil Mixing Construction For Stabilizing Expansive SubsoilstehNo ratings yet
- Large Deformation Finite-Element Modelling of Progressive Failure Leading To Spread in Sensitive Clay SlopesDocument12 pagesLarge Deformation Finite-Element Modelling of Progressive Failure Leading To Spread in Sensitive Clay SlopestehNo ratings yet
- Modul 2 Sgems PDFDocument8 pagesModul 2 Sgems PDFaloysiusdeargaNo ratings yet
- Guide For SpreadsheetsDocument82 pagesGuide For SpreadsheetsIsabelle Wong100% (1)
- PTP2-900mm Test Report-KL Sentral Riveria BrickfieldsDocument32 pagesPTP2-900mm Test Report-KL Sentral Riveria BrickfieldstehNo ratings yet
- An Introduction To FE Analysis With Excel-VBA: Kyanase@fukuoka-U.ac - JPDocument15 pagesAn Introduction To FE Analysis With Excel-VBA: Kyanase@fukuoka-U.ac - JPChangbum YuNo ratings yet
- Frogkisser! by Garth Nix (Excerpt)Document17 pagesFrogkisser! by Garth Nix (Excerpt)I Read YA0% (1)
- PariharaDocument2 pagesPariharahrvNo ratings yet
- List of Blade MaterialsDocument19 pagesList of Blade MaterialsAnie Ummu Alif & SyifaNo ratings yet
- Engine Technology Course A/F Control Classroom TrainingDocument14 pagesEngine Technology Course A/F Control Classroom Traininglongtrandang5867No ratings yet
- Pub1308 WebDocument193 pagesPub1308 WebyucemanNo ratings yet
- AP Poetry TermsDocument8 pagesAP Poetry TermsTEACHER BARAY LLCE ANGLAISNo ratings yet
- Strategic Management and Municipal Financial ReportingDocument38 pagesStrategic Management and Municipal Financial ReportingMarius BuysNo ratings yet
- Chapter 2Document5 pagesChapter 2Ayush Hooda class 12 ANo ratings yet
- Advanced Engineering Economics: Combining FactorsDocument19 pagesAdvanced Engineering Economics: Combining FactorsA GlaumNo ratings yet
- Report-Teaching English Ministery of EduDocument21 pagesReport-Teaching English Ministery of EduSohrab KhanNo ratings yet
- List of Trigonometric IdentitiesDocument16 pagesList of Trigonometric IdentitiesArnab NandiNo ratings yet
- January 2011Document64 pagesJanuary 2011sake1978No ratings yet
- Omega 1 Akanksha 9069664Document5 pagesOmega 1 Akanksha 9069664Akanksha SarangiNo ratings yet
- OTISLINE QuestionsDocument5 pagesOTISLINE QuestionsArvind Gupta100% (1)
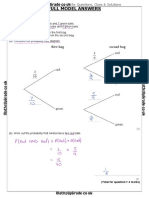
- Probability Tree Diagrams Solutions Mathsupgrade Co UkDocument10 pagesProbability Tree Diagrams Solutions Mathsupgrade Co UknatsNo ratings yet
- Labcir - Marwa - FinalDocument119 pagesLabcir - Marwa - FinalMashavia AhmadNo ratings yet
- Quiz - Limits and ContinuityDocument3 pagesQuiz - Limits and ContinuityAdamNo ratings yet
- C Pid3 009Document9 pagesC Pid3 009Youssef EBNo ratings yet
- Quantitative Data Analysis 2Document10 pagesQuantitative Data Analysis 2Rhona MaandalNo ratings yet
- XFARDocument14 pagesXFARRIZA SAMPAGANo ratings yet
- Student quiz answer sheetsDocument26 pagesStudent quiz answer sheetsSeverus S PotterNo ratings yet
- Delays in Endoscope Reprocessing and The Biofilms WithinDocument12 pagesDelays in Endoscope Reprocessing and The Biofilms WithinHAITHM MURSHEDNo ratings yet
- 2020会社案内(英語版)Document18 pages2020会社案内(英語版)DAC ORGANIZERNo ratings yet
- Food, Family, and FriendshipsDocument256 pagesFood, Family, and FriendshipsBianca PradoNo ratings yet
- Data Sheet Ads1292rDocument69 pagesData Sheet Ads1292rKaha SyawalNo ratings yet
- Measure Science AccuratelyDocument41 pagesMeasure Science AccuratelyAnthony QuanNo ratings yet
- MF ISIN CodeDocument49 pagesMF ISIN CodeshriramNo ratings yet
- WEG Low Voltage Motor Control Center ccm03 50044030 Brochure English PDFDocument12 pagesWEG Low Voltage Motor Control Center ccm03 50044030 Brochure English PDFRitaban222No ratings yet
- Contoh Skripsi Bahasa Inggris Case StudyDocument18 pagesContoh Skripsi Bahasa Inggris Case StudyRizki Fajrita100% (14)
- K - LP - Week 24 - Journeys Unit 3 Lesson 14Document8 pagesK - LP - Week 24 - Journeys Unit 3 Lesson 14englishwithmslilyNo ratings yet