You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5819)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1092)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (845)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (348)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (822)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Development of The Self-Disclosure ScaleDocument20 pagesThe Development of The Self-Disclosure ScaleCarlo Magno88% (25)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Relationship Between Knowledge Inertia, Organizational Learning and Organization InnovationDocument13 pagesRelationship Between Knowledge Inertia, Organizational Learning and Organization InnovationFrancesco CassinaNo ratings yet
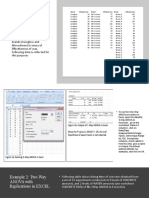
- Example 1: One Way ANOVA in ExcelDocument5 pagesExample 1: One Way ANOVA in ExcelAticha KwaengsophaNo ratings yet
- Brand Love: The Emotional Bridge Between Experience and Engagement, Generation-M PerspectiveDocument16 pagesBrand Love: The Emotional Bridge Between Experience and Engagement, Generation-M Perspectivesmart_kidzNo ratings yet
- Buss Barnes 1986 PDFDocument12 pagesBuss Barnes 1986 PDFAna MirelaNo ratings yet
- Expedited IRB Application Cheat Sheet: Before You BeginDocument11 pagesExpedited IRB Application Cheat Sheet: Before You BeginAticha KwaengsophaNo ratings yet
- 57740006Document74 pages57740006Aticha KwaengsophaNo ratings yet
- Advanced and Multivariate Statistical Methods: Practical Application and InterpretationDocument20 pagesAdvanced and Multivariate Statistical Methods: Practical Application and InterpretationAticha KwaengsophaNo ratings yet
- AMSM Ch4Document24 pagesAMSM Ch4Aticha KwaengsophaNo ratings yet
- AMSM Ch11Document14 pagesAMSM Ch11Aticha KwaengsophaNo ratings yet
- Chapter 3 - Managing Organizational BehaviorDocument46 pagesChapter 3 - Managing Organizational BehaviorAticha KwaengsophaNo ratings yet
- Statistics For Business and Economics Sneak PreviewDocument14 pagesStatistics For Business and Economics Sneak PreviewAticha KwaengsophaNo ratings yet
- APA Formatting Sample PaperDocument12 pagesAPA Formatting Sample PaperAticha KwaengsophaNo ratings yet
- The Ambivalent Sexism Inventory: Differentiating Hostile and Benevolent SexismDocument22 pagesThe Ambivalent Sexism Inventory: Differentiating Hostile and Benevolent SexismBrendan KingNo ratings yet
- 31 C143Document6 pages31 C143Naveed RehmanNo ratings yet
- Goldberg's IPIP Big Five Factor Markers Internal Consistency and Concurrent Validation in ScotlandDocument13 pagesGoldberg's IPIP Big Five Factor Markers Internal Consistency and Concurrent Validation in ScotlandZoran Rapaic100% (1)
- Dsur I Chapter 17 EfaDocument47 pagesDsur I Chapter 17 EfaDannyNo ratings yet
- Litman Jimerson 2004Document11 pagesLitman Jimerson 2004Sudhan NadarNo ratings yet
- Personal Computing: Toward A Conceptual Model of Utilization 1Document19 pagesPersonal Computing: Toward A Conceptual Model of Utilization 1neethu856No ratings yet
- Development of The Perceived Physical Literacy Que - 2023 - Journal of ExerciseDocument10 pagesDevelopment of The Perceived Physical Literacy Que - 2023 - Journal of ExerciseSherriNo ratings yet
- A Study On Factors Affecting Green Consumer BehaviorDocument33 pagesA Study On Factors Affecting Green Consumer BehaviorAniruddha100% (2)
- TheCompassionCompetenceScale StudentNursesDocument10 pagesTheCompassionCompetenceScale StudentNursesvirieguiaNo ratings yet
- Lim Et Al 2014Document11 pagesLim Et Al 2014yassermahfoozNo ratings yet
- The Aggression Questionnaire: Arnold H. Buss and Mark PerryDocument8 pagesThe Aggression Questionnaire: Arnold H. Buss and Mark PerryIsalba GloriaNo ratings yet
- A Principal Component Analysis of Skills and Competencies Required of Quantity Surveyors (Nigerian Perspective)Document13 pagesA Principal Component Analysis of Skills and Competencies Required of Quantity Surveyors (Nigerian Perspective)netNo ratings yet
- SPH Sabbath and HealthDocument14 pagesSPH Sabbath and HealthFerdy LainsamputtyNo ratings yet
- Development of The Stanford Expectations of Treatment Scale (SETS) : A Tool For Measuring Patient Outcome Expectancy in Clinical TrialsDocument10 pagesDevelopment of The Stanford Expectations of Treatment Scale (SETS) : A Tool For Measuring Patient Outcome Expectancy in Clinical TrialssoylahijadeunvampiroNo ratings yet
- Beliefs in Personality Disorders: A Test With The Personality Disorder Belief QuestionnaireDocument11 pagesBeliefs in Personality Disorders: A Test With The Personality Disorder Belief QuestionnaireNađa FilipovićNo ratings yet
- 10 1016@j Nedt 2020 104440Document13 pages10 1016@j Nedt 2020 104440Florian BodnariuNo ratings yet
- The General Health Questionnaire-28 (GHQ-28) As An Outcome Measurement in A Randomized Controlled Trial in A Norwegian Stroke PopulationDocument11 pagesThe General Health Questionnaire-28 (GHQ-28) As An Outcome Measurement in A Randomized Controlled Trial in A Norwegian Stroke PopulationAV GaneshNo ratings yet
- PPTDocument29 pagesPPTDeepak ChaudharyNo ratings yet
- 2015 The Impact of Knowledge Management Practices On Organizational Performance - A Balanced Scorecard ApproachDocument31 pages2015 The Impact of Knowledge Management Practices On Organizational Performance - A Balanced Scorecard ApproachPrana Djati NingrumNo ratings yet
- Vol I Issue IV 30 40 Paper 4 Sandeep Choudhary CONSUMER PERCEPTION REGARDING LIFE INSURANCE POLICIES A FACTOR ANALYTICAL APPROACHDocument11 pagesVol I Issue IV 30 40 Paper 4 Sandeep Choudhary CONSUMER PERCEPTION REGARDING LIFE INSURANCE POLICIES A FACTOR ANALYTICAL APPROACHSandeep KumarNo ratings yet
- Increasing Customer Purchase Intention Through Product Return Policies - The Pivotal Impacts of Retailer Brand Familiarity and Product CategoriesDocument8 pagesIncreasing Customer Purchase Intention Through Product Return Policies - The Pivotal Impacts of Retailer Brand Familiarity and Product Categoriesvks svkNo ratings yet
- Validation of The Metacomprehension ScaleDocument15 pagesValidation of The Metacomprehension Scaleemysameh100% (1)
- Avoiding Food Waste by Romanian Consumers The Importance of Planning and Shopping Routines 2013 Food Quality and PreferenceDocument7 pagesAvoiding Food Waste by Romanian Consumers The Importance of Planning and Shopping Routines 2013 Food Quality and PreferenceAna MariaNo ratings yet
- EI 2023 Electronics and Instrument Engineering Etr 2023 PaperDocument56 pagesEI 2023 Electronics and Instrument Engineering Etr 2023 PaperRajath G RNo ratings yet
- Assessing Organizational Climate: Psychometric Properties of The CLIOR ScaleDocument9 pagesAssessing Organizational Climate: Psychometric Properties of The CLIOR ScaleДаниил БорисенкоNo ratings yet
- Generational Motivation and Preference For RewardDocument12 pagesGenerational Motivation and Preference For RewardOmotayo AkinpelumiNo ratings yet