You might also like
- Explainable AI: Interpreting, Explaining and Visualizing Deep LearningFrom EverandExplainable AI: Interpreting, Explaining and Visualizing Deep LearningWojciech SamekNo ratings yet
- Action Unit Analysis Enhanced Facial Expression Recognition by Deep Neural Network EvolutionDocument14 pagesAction Unit Analysis Enhanced Facial Expression Recognition by Deep Neural Network EvolutionÁLVARO RUIZ GARCÍANo ratings yet
- Nctet Ece 02Document7 pagesNctet Ece 02Khiêm NguyễnNo ratings yet
- Facial Expression Recognition Using Convolutional Neural NetworkDocument14 pagesFacial Expression Recognition Using Convolutional Neural NetworkIJRASETPublicationsNo ratings yet
- CaseDocument13 pagesCasegateeceNo ratings yet
- Applied SciencesDocument15 pagesApplied Sciencesmagimai dassNo ratings yet
- Informatics: Facial Emotion Recognition Using Hybrid FeaturesDocument13 pagesInformatics: Facial Emotion Recognition Using Hybrid FeaturesThuậnNo ratings yet
- Facial Micro-Expressions An OverviewDocument21 pagesFacial Micro-Expressions An OverviewcstoajfuNo ratings yet
- Healthcare Iot-Based Affective State Mining Using A Deep Convolutional Neural NetworkDocument15 pagesHealthcare Iot-Based Affective State Mining Using A Deep Convolutional Neural NetworkKrish SukhaniNo ratings yet
- Facial Expression Recognition SystemDocument52 pagesFacial Expression Recognition SystemvickyNo ratings yet
- A Machine Learning Emotion Detection Platform To Support Affective Well BeingDocument7 pagesA Machine Learning Emotion Detection Platform To Support Affective Well BeingPrathviniNo ratings yet
- Sensors: Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional NetworkDocument16 pagesSensors: Deep-Emotion: Facial Expression Recognition Using Attentional Convolutional Networkassasaa asasaNo ratings yet
- Methods For Facial Expression Recognition With AppDocument17 pagesMethods For Facial Expression Recognition With AppPeymananbari PeymanNo ratings yet
- Brainsci 13 00589 v2Document22 pagesBrainsci 13 00589 v2hani1986yeNo ratings yet
- Salih 2017Document5 pagesSalih 2017Harsha GowdaNo ratings yet
- Emotion Recognition Through Multiple Modalities: Face, Body Gesture, SpeechDocument13 pagesEmotion Recognition Through Multiple Modalities: Face, Body Gesture, SpeechAndra BaddNo ratings yet
- AffectNet Onecolumn-2Document31 pagesAffectNet Onecolumn-2assasaa asasaNo ratings yet
- Brain Sciences: Advances in Multimodal Emotion Recognition Based On Brain-Computer InterfacesDocument29 pagesBrain Sciences: Advances in Multimodal Emotion Recognition Based On Brain-Computer InterfacesZaima Sartaj TaheriNo ratings yet
- Automatic ECG-Based Emotion Recognition in Music ListeningDocument16 pagesAutomatic ECG-Based Emotion Recognition in Music ListeningmuraliNo ratings yet
- An Emotion Recognition System: Bridging The Gap Between Humans-Machines InteractionDocument10 pagesAn Emotion Recognition System: Bridging The Gap Between Humans-Machines InteractionIAES International Journal of Robotics and AutomationNo ratings yet
- Facial Emotion Recognition System Through Machine Learning ApproachDocument7 pagesFacial Emotion Recognition System Through Machine Learning ApproachDivya SuvarnaNo ratings yet
- DEAP: A Database For Emotion Analysis Using Physiological SignalsDocument14 pagesDEAP: A Database For Emotion Analysis Using Physiological SignalsMohammad TaheriNo ratings yet
- Research 1 PDFDocument6 pagesResearch 1 PDFaadafullNo ratings yet
- Automated Facial Expression Recognition Using Deep Learning Techniques - An Overview (#657395) - 1125402Document15 pagesAutomated Facial Expression Recognition Using Deep Learning Techniques - An Overview (#657395) - 1125402Awatef MessaoudiNo ratings yet
- DEAP A Database For Emotion AnalysisDocument15 pagesDEAP A Database For Emotion AnalysisTr. Zin Wah OoNo ratings yet
- High Efficiency Facial Expression Recognition Based Active Semi-Supervised LearningDocument9 pagesHigh Efficiency Facial Expression Recognition Based Active Semi-Supervised Learningminhaz21No ratings yet
- Efficient Facial Expression Recognition Algorithm Based On Hierarchical Deep Neural Network StructureDocument13 pagesEfficient Facial Expression Recognition Algorithm Based On Hierarchical Deep Neural Network StructureAhadit ABNo ratings yet
- Facual Recognition TechnologyDocument17 pagesFacual Recognition TechnologyStellamaris MutukuNo ratings yet
- Analysis of Landmarks in Recognition of Face Expressions: Application ProblemsDocument13 pagesAnalysis of Landmarks in Recognition of Face Expressions: Application ProblemsanushreesuklabaidyaNo ratings yet
- Development of A Real-Time Emotion Recognition System Using Facial Expressions and EEG Based On Machine Learning and Deep Neural Network MethodsDocument20 pagesDevelopment of A Real-Time Emotion Recognition System Using Facial Expressions and EEG Based On Machine Learning and Deep Neural Network MethodssasosaskoNo ratings yet
- To What Extent Can and Should Artificial Intelligence Agents Have Emotional IntelligenceDocument15 pagesTo What Extent Can and Should Artificial Intelligence Agents Have Emotional Intelligencenael khalidNo ratings yet
- Facialexpressions PDFDocument20 pagesFacialexpressions PDFzentropiaNo ratings yet
- Sensors 18 00416 PDFDocument25 pagesSensors 18 00416 PDFAisyahOmarNo ratings yet
- Sensors 18 00416 PDFDocument25 pagesSensors 18 00416 PDFAisyahOmarNo ratings yet
- A Study On Face Expression Observation SystemsDocument7 pagesA Study On Face Expression Observation SystemsEditor IJTSRDNo ratings yet
- On Improving Visual-Facial Emotion Recognition With Audio-Lingual and Keyboard Stroke Pattern InformationDocument7 pagesOn Improving Visual-Facial Emotion Recognition With Audio-Lingual and Keyboard Stroke Pattern InformationsoniyaNo ratings yet
- $Xwrpdwlf'Hsuhvvlrq/Hyho'Hwhfwlrq7Kurxjk 9lvxdo, QSXW: Abstract Depression Is The Most Comprehensive MoodDocument4 pages$Xwrpdwlf'Hsuhvvlrq/Hyho'Hwhfwlrq7Kurxjk 9lvxdo, QSXW: Abstract Depression Is The Most Comprehensive Moodasma khanNo ratings yet
- Hybrid Facial Expression Recognition (FER2013) Model For Real-Time Emotion Classification and PredictionDocument9 pagesHybrid Facial Expression Recognition (FER2013) Model For Real-Time Emotion Classification and PredictionBOHR International Journal of Internet of things, Artificial Intelligence and Machine LearningNo ratings yet
- Glowinski, D., Dael, N., Camurri, A., Volpe, G., Mortillaro, M., & Scherer, K. R. (2011). Towards a minimal representation of affective gestures. IEEE Transactions on Affective Computing, 2(2), 106–118..pdfDocument8 pagesGlowinski, D., Dael, N., Camurri, A., Volpe, G., Mortillaro, M., & Scherer, K. R. (2011). Towards a minimal representation of affective gestures. IEEE Transactions on Affective Computing, 2(2), 106–118..pdfMaria MiñoNo ratings yet
- Tugas 2 Aplikasi Perkantoran (Axel Theo Winata Ursia)Document18 pagesTugas 2 Aplikasi Perkantoran (Axel Theo Winata Ursia)Axel UrsiaNo ratings yet
- Facial Expression Recognition Using Facial Landmarks: A Novel ApproachDocument5 pagesFacial Expression Recognition Using Facial Landmarks: A Novel Approachassasaa asasaNo ratings yet
- 10 1016@j Copsyc 2020 04 005Document6 pages10 1016@j Copsyc 2020 04 005terminallllNo ratings yet
- Facial Emotion Recognition Using Convolutional Neural NetworksDocument5 pagesFacial Emotion Recognition Using Convolutional Neural NetworksIJRASETPublicationsNo ratings yet
- The Facial Expression Detection From Human Facial Image by Using Neural NetworkDocument5 pagesThe Facial Expression Detection From Human Facial Image by Using Neural NetworkInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- JMLR12Document20 pagesJMLR12Berdu RizqiNo ratings yet
- Informatics in Medicine Unlocked: Aya Hassouneh, A.M. Mutawa, M. MurugappanDocument9 pagesInformatics in Medicine Unlocked: Aya Hassouneh, A.M. Mutawa, M. MurugappanKolawole JosephNo ratings yet
- A Review On Facial Expression Recognition TechniquesDocument8 pagesA Review On Facial Expression Recognition TechniquesAnonymous lPvvgiQjRNo ratings yet
- Guest Editorial Towards Machines Able To Deal With LaughterDocument3 pagesGuest Editorial Towards Machines Able To Deal With LaughterJuan José Delgado QuesadaNo ratings yet
- Facial Expression Recognition Using CNN For HealthcareDocument9 pagesFacial Expression Recognition Using CNN For HealthcareChris Morgan ShintaroNo ratings yet
- Emotion Classification in Arousal Valence Model Using MAHNOB-HCI DatabaseDocument6 pagesEmotion Classification in Arousal Valence Model Using MAHNOB-HCI DatabaseParantapDansanaNo ratings yet
- Preprocessing Challenges For Real World Affect RecognitionDocument10 pagesPreprocessing Challenges For Real World Affect RecognitioncseijNo ratings yet
- Cross Domain Self-Reported Vs Apparent Personality Perception Using Deep LearningDocument13 pagesCross Domain Self-Reported Vs Apparent Personality Perception Using Deep LearningXknilNo ratings yet
- 2015 - Paper - Emotion Recognition - A Selected ReviewDocument15 pages2015 - Paper - Emotion Recognition - A Selected ReviewTakamura666No ratings yet
- A Review On Emotion and Sentiment Analysis Using Learning TechniquesDocument13 pagesA Review On Emotion and Sentiment Analysis Using Learning TechniquesIJRASETPublicationsNo ratings yet
- Wallace C K A K KDocument46 pagesWallace C K A K KKostas KarpouzisNo ratings yet
- Effectiveness of Eigenspaces For Facial Expressions RecognitionDocument5 pagesEffectiveness of Eigenspaces For Facial Expressions RecognitionAbu Bakar DogarNo ratings yet
- Experiment No. 06: A.1 AimDocument9 pagesExperiment No. 06: A.1 AimNATASHA DOSHINo ratings yet
- Final ReportDocument22 pagesFinal ReportHira Khan 61170150% (1)
- Pre ProcessingDocument54 pagesPre Processingzelvrian 2No ratings yet
- GROUP CYGMUS - Emotion Sensing Facial RecognitionDocument5 pagesGROUP CYGMUS - Emotion Sensing Facial Recognitionkrish krishaNo ratings yet
- Assessment 2: End of Semester 2Document15 pagesAssessment 2: End of Semester 2GraceSevillanoNo ratings yet
- Development of A Hand Pose Recognition System On An Embedded Computer Using Artificial IntelligenceDocument4 pagesDevelopment of A Hand Pose Recognition System On An Embedded Computer Using Artificial IntelligenceGraceSevillanoNo ratings yet
- Building Transformer-Based Natural Language Processing ApplicationsDocument3 pagesBuilding Transformer-Based Natural Language Processing ApplicationsGraceSevillanoNo ratings yet
- Remotesensing 11 00760Document25 pagesRemotesensing 11 00760GraceSevillanoNo ratings yet
- Automatic Detection of Snow Avalanches in Continuous SeismicDocument15 pagesAutomatic Detection of Snow Avalanches in Continuous SeismicGraceSevillanoNo ratings yet
- Matlab Sound LocatizationDocument86 pagesMatlab Sound LocatizationGraceSevillanoNo ratings yet
- Robert Harvard CVDocument1 pageRobert Harvard CVGraceSevillanoNo ratings yet
- Matlab GuideDocument2 pagesMatlab GuideGraceSevillanoNo ratings yet
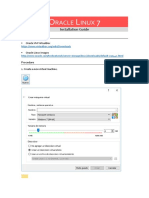
- Oracle Linux 7 - Installation Guide - Without GUIDocument12 pagesOracle Linux 7 - Installation Guide - Without GUIGraceSevillanoNo ratings yet
- Selecting Appropriate Instructional Materials For Edukasyong Pantahanan at Pangkabuhayan/ Technology and Livelihood EducationDocument35 pagesSelecting Appropriate Instructional Materials For Edukasyong Pantahanan at Pangkabuhayan/ Technology and Livelihood EducationJhenn Mhen Yhon100% (1)
- SR# Call Type A-Party B-Party Date & Time Duration Cell ID ImeiDocument12 pagesSR# Call Type A-Party B-Party Date & Time Duration Cell ID ImeiSaifullah BalochNo ratings yet
- GoodElearning TOGAF Poster 46 - Adapting The ADMDocument1 pageGoodElearning TOGAF Poster 46 - Adapting The ADMFabian HidalgoNo ratings yet
- DC Motor: F Bli NewtonDocument35 pagesDC Motor: F Bli NewtonMuhammad TausiqueNo ratings yet
- Business Statistics: Fourth Canadian EditionDocument41 pagesBusiness Statistics: Fourth Canadian EditionTaron AhsanNo ratings yet
- Manual - Rapid Literacy AssessmentDocument16 pagesManual - Rapid Literacy AssessmentBaldeo PreciousNo ratings yet
- Assignment 5 WarehousingDocument4 pagesAssignment 5 WarehousingabbasNo ratings yet
- Planetary Yogas in Astrology: O.P.Verma, IndiaDocument7 pagesPlanetary Yogas in Astrology: O.P.Verma, IndiaSaptarishisAstrology50% (2)
- Design Calculation FOR Rigid Pavement/RoadDocument5 pagesDesign Calculation FOR Rigid Pavement/RoadghansaNo ratings yet
- BC 672772 RBRS Service TraningDocument385 pagesBC 672772 RBRS Service TraningTeknik Makina100% (2)
- Bohler Dcms T-MCDocument1 pageBohler Dcms T-MCFlaviu-Andrei AstalisNo ratings yet
- Validación Española ADHD-RSDocument7 pagesValidación Española ADHD-RSCristina Andreu NicuesaNo ratings yet
- Watershed Conservation of Benguet VisDocument2 pagesWatershed Conservation of Benguet VisInnah Agito-RamosNo ratings yet
- 9300AE 10-30kseis LDN 2005 PDFDocument2 pages9300AE 10-30kseis LDN 2005 PDFDoina ClichiciNo ratings yet
- Design of AC Chopper Voltage Regulator Based On PIC16F716 MicrocontrollerDocument4 pagesDesign of AC Chopper Voltage Regulator Based On PIC16F716 MicrocontrollerabfstbmsodNo ratings yet
- Sta404 07Document71 pagesSta404 07Ibnu Iyar0% (1)
- Agenda - Meeting SLC (LT) - 27.06.2014 PDFDocument27 pagesAgenda - Meeting SLC (LT) - 27.06.2014 PDFharshal1223No ratings yet
- The Theory of Production and Cost: Chapter FourDocument32 pagesThe Theory of Production and Cost: Chapter FourOromay Elias100% (1)
- IVISOR Mentor IVISOR Mentor QVGADocument2 pagesIVISOR Mentor IVISOR Mentor QVGAwoulkanNo ratings yet
- Exp - P7 - UPCTDocument11 pagesExp - P7 - UPCTSiddesh PatilNo ratings yet
- Sample File: The Ultimate Adventurers Guide IDocument6 pagesSample File: The Ultimate Adventurers Guide IDingusbubmisNo ratings yet
- ANSI AAMI ST63 2002 - Sterilization of Healthcare Products - Dry HeatDocument54 pagesANSI AAMI ST63 2002 - Sterilization of Healthcare Products - Dry HeatGraciane TagliettiNo ratings yet
- Mis Report On Ola CabsDocument18 pagesMis Report On Ola CabsDaksh MaruNo ratings yet
- Aspen Plus User ModelsDocument339 pagesAspen Plus User Modelskiny81100% (1)
- Module 2 DIPDocument33 pagesModule 2 DIPdigital loveNo ratings yet
- Help SIMARIS Project 3.1 enDocument61 pagesHelp SIMARIS Project 3.1 enVictor VignolaNo ratings yet
- Risk Assessment For Harmonic Measurement Study ProcedureDocument13 pagesRisk Assessment For Harmonic Measurement Study ProcedureAnandu AshokanNo ratings yet
- AT ChapIDocument48 pagesAT ChapIvigneshwaranbeNo ratings yet
- 3-Waves of RoboticsDocument2 pages3-Waves of RoboticsEbrahim Abd El HadyNo ratings yet
- Design of CouplingDocument75 pagesDesign of CouplingVatsal BhalaniNo ratings yet
- SketchUp Success for Woodworkers: Four Simple Rules to Create 3D Drawings Quickly and AccuratelyFrom EverandSketchUp Success for Woodworkers: Four Simple Rules to Create 3D Drawings Quickly and AccuratelyRating: 1.5 out of 5 stars1.5/5 (2)
- CATIA V5-6R2015 Basics - Part I : Getting Started and Sketcher WorkbenchFrom EverandCATIA V5-6R2015 Basics - Part I : Getting Started and Sketcher WorkbenchRating: 4 out of 5 stars4/5 (10)
- Certified Solidworks Professional Advanced Weldments Exam PreparationFrom EverandCertified Solidworks Professional Advanced Weldments Exam PreparationRating: 5 out of 5 stars5/5 (1)
- FreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsFrom EverandFreeCAD | Step by Step: Learn how to easily create 3D objects, assemblies, and technical drawingsRating: 5 out of 5 stars5/5 (1)
- Beginning AutoCAD® 2020 Exercise WorkbookFrom EverandBeginning AutoCAD® 2020 Exercise WorkbookRating: 2.5 out of 5 stars2.5/5 (3)
- Design Research Through Practice: From the Lab, Field, and ShowroomFrom EverandDesign Research Through Practice: From the Lab, Field, and ShowroomRating: 3 out of 5 stars3/5 (7)