You might also like
- MysqlDocument81 pagesMysqlAayush Sahu100% (1)
- Data Handing Using Pandas-IDocument46 pagesData Handing Using Pandas-IPriyanka Porwal JainNo ratings yet
- Qualitative Research and It's Importance in Daily LifeDocument25 pagesQualitative Research and It's Importance in Daily LifeEva Janine MarcesNo ratings yet
- Python LabDocument8 pagesPython Labduc anhNo ratings yet
- On Data Handling Using Pandas-IDocument64 pagesOn Data Handling Using Pandas-IRayansh Chauhan100% (2)
- DBMS Complete NotesDocument122 pagesDBMS Complete NotesRavi KiranNo ratings yet
- Problems With Safety Observation Reporting - A Construction Industry Case StudyDocument34 pagesProblems With Safety Observation Reporting - A Construction Industry Case StudyRadger Teddy ManuelNo ratings yet
- Python Data Science 101Document41 pagesPython Data Science 101consania100% (1)
- Snapshot Management For NAS Devices Integration GuideDocument104 pagesSnapshot Management For NAS Devices Integration GuidejmpalaciosbNo ratings yet
- Data Warehousing in The Age of Artificial IntelligenceDocument94 pagesData Warehousing in The Age of Artificial Intelligencejwtan2010No ratings yet
- Python Pandas Demo PDFDocument23 pagesPython Pandas Demo PDFRakshit Kukreja100% (2)
- Chapter-2 Python PandasDocument33 pagesChapter-2 Python PandasSwarnim Jain100% (2)
- On Data Handling Using Pandas-IDocument63 pagesOn Data Handling Using Pandas-Ianagha100% (2)
- 12 IP Unit 1 Python Pandas I (Part 3 Dataframes) NotesDocument24 pages12 IP Unit 1 Python Pandas I (Part 3 Dataframes) NotesKrishnendu ChakrabortyNo ratings yet
- 1 IP 12 NOTES PythonPandas 2022 PDFDocument66 pages1 IP 12 NOTES PythonPandas 2022 PDFKrrish Kumar100% (3)
- Marketing Research NotesDocument102 pagesMarketing Research Notessachin goswamiNo ratings yet
- Pandas in PythonDocument59 pagesPandas in PythonAamna RazaNo ratings yet
- Pandas 1705297450Document21 pagesPandas 1705297450kkkvj9d8zwNo ratings yet
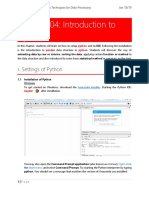
- 04 Introduction To Python-1Document29 pages04 Introduction To Python-1FucKerWengieNo ratings yet
- Class XII Data Handlinng Using PandasIDocument46 pagesClass XII Data Handlinng Using PandasIPushkar ChaudharyNo ratings yet
- Pandas Module (Part-I)Document36 pagesPandas Module (Part-I)Aditya ChauhanNo ratings yet
- Exp1 - Manipulating Datasets Using PandasDocument15 pagesExp1 - Manipulating Datasets Using PandasmnbatrawiNo ratings yet
- Data Handling Using Pandas-I-ORGDocument44 pagesData Handling Using Pandas-I-ORGAyush KumarNo ratings yet
- Dva Lab ManualDocument32 pagesDva Lab Manualhiya ChopraNo ratings yet
- 20 Pandas Functions For 80% of Your Data ScienceDocument22 pages20 Pandas Functions For 80% of Your Data ScienceHARRYNo ratings yet
- PandasDocument16 pagesPandasHoneyNo ratings yet
- 5CS037 WS02 PandasForDataAnalysisDocument30 pages5CS037 WS02 PandasForDataAnalysisPankaj MahatoNo ratings yet
- Pandas What Can Pandas Do For You ?: Statsmodels SM Seaborn SnsDocument9 pagesPandas What Can Pandas Do For You ?: Statsmodels SM Seaborn SnsNohaM.No ratings yet
- Python LibrariesDocument27 pagesPython LibrariesNaitik JainNo ratings yet
- PythonDocument15 pagesPythonBizhub Konica MinoltaNo ratings yet
- Python Pandas ch-2Document56 pagesPython Pandas ch-2Rohan sushilNo ratings yet
- Pandas Dataframe Export The CSV FileDocument9 pagesPandas Dataframe Export The CSV Fileammouna bengNo ratings yet
- Differentiate Between Data Type and Data StructuresDocument11 pagesDifferentiate Between Data Type and Data StructureskrishnakumarNo ratings yet
- 1 Pandas BasicsDocument13 pages1 Pandas BasicsBikuNo ratings yet
- Pandas For Machine Learning: AcadviewDocument18 pagesPandas For Machine Learning: AcadviewYash BansalNo ratings yet
- Pandas TutorialDocument21 pagesPandas TutorialKEVIN KUMARNo ratings yet
- Pandas NotesDocument4 pagesPandas NotesDev D GhoshNo ratings yet
- Lab3 - Python - Pandas DataFrame - GeeksforGeeksDocument20 pagesLab3 - Python - Pandas DataFrame - GeeksforGeekssa00059No ratings yet
- 12 IP Notes On SeriesDocument5 pages12 IP Notes On Serieslgarg2505No ratings yet
- Python Pandas New SylabusDocument53 pagesPython Pandas New SylabusRohan sushilNo ratings yet
- Block 1-Data Handling Using Pandas DataFrameDocument17 pagesBlock 1-Data Handling Using Pandas DataFrameBhaskar PVNNo ratings yet
- 5th LESSON (ANKUR - PROSCHOOL) - PANDASDocument50 pages5th LESSON (ANKUR - PROSCHOOL) - PANDASTanuj BhattacharyyaNo ratings yet
- Pattern Action Reference: Ibm Infosphere QualitystageDocument74 pagesPattern Action Reference: Ibm Infosphere QualitystagezipzapdhoomNo ratings yet
- Revision Point - DataframeDocument11 pagesRevision Point - Dataframezahir khanNo ratings yet
- MOD-3 DapDocument41 pagesMOD-3 DapVarshitha KnNo ratings yet
- BDA FileDocument26 pagesBDA Filesahil raturiNo ratings yet
- IP PraticalDocument56 pagesIP Praticalvaibhavm2359No ratings yet
- Arrays: Store A Single Value at A Time Store Roll No. of 100 Students?Document17 pagesArrays: Store A Single Value at A Time Store Roll No. of 100 Students?Mohd UmairNo ratings yet
- Class Notes Class: XII Date: 17-04-2021 Subject: Informatics Practices Topic: Chapter-1Document5 pagesClass Notes Class: XII Date: 17-04-2021 Subject: Informatics Practices Topic: Chapter-1niranjana binuNo ratings yet
- Pandas 3Document33 pagesPandas 3cr.lucianoperezNo ratings yet
- R Basics: Daniel StegmuellerDocument14 pagesR Basics: Daniel Stegmuellerblackdaisy13No ratings yet
- SQL Queries and PL/SQLDocument92 pagesSQL Queries and PL/SQLsaloya1764No ratings yet
- Pandas DataframeDocument10 pagesPandas DataframealiNo ratings yet
- Pandas DataframeDocument48 pagesPandas DataframeJames PrakashNo ratings yet
- Unit 4 PandasDocument8 pagesUnit 4 PandasPriya S BNo ratings yet
- Pandas LibraryDocument5 pagesPandas LibrarynoneNo ratings yet
- Python-for-Data-Analysis (PandasDocument31 pagesPython-for-Data-Analysis (PandasNaman JainNo ratings yet
- MohitDocument19 pagesMohitAyush GuptaNo ratings yet
- Part A Assignment 10Document3 pagesPart A Assignment 10B49 Pravin TeliNo ratings yet
- 3Y3Z2Xzqn7 U Y%K : 2. How To Create A Data Frame Using A Dictionary of Pre-Existing Columns or Numpy 2D Arrays?Document8 pages3Y3Z2Xzqn7 U Y%K : 2. How To Create A Data Frame Using A Dictionary of Pre-Existing Columns or Numpy 2D Arrays?Sudan PudasainiNo ratings yet
- Ai - Phase 3Document9 pagesAi - Phase 3Manikandan NNo ratings yet
- Loops: Genome 559: Introduction To Statistical and Computational Genomics Prof. James H. ThomasDocument27 pagesLoops: Genome 559: Introduction To Statistical and Computational Genomics Prof. James H. ThomasRahul JagdaleNo ratings yet
- Features of PythonDocument14 pagesFeatures of Pythonsubash murugaiyaNo ratings yet
- Seleccione Pandas Dataframes Columnas y Filas Usando Loc y IlocDocument7 pagesSeleccione Pandas Dataframes Columnas y Filas Usando Loc y Ilochernanes13No ratings yet
- Lit: Zero-Shot Transfer With Locked-Image Text Tuning: Google Research, Brain Team, Z UrichDocument26 pagesLit: Zero-Shot Transfer With Locked-Image Text Tuning: Google Research, Brain Team, Z UrichSoumava PaulNo ratings yet
- E WapiDocument26 pagesE WapiMike TyverNo ratings yet
- The Aims of Art Education An Analysis of Visual Art inDocument16 pagesThe Aims of Art Education An Analysis of Visual Art inSiantarman Siantar100% (1)
- MESSAGE - TYPE - X Dump AM888: SymptomDocument2 pagesMESSAGE - TYPE - X Dump AM888: Symptomzaki Abadul BasitNo ratings yet
- Module 5Document15 pagesModule 5Aleli Ann SecretarioNo ratings yet
- Essbase ASO ImplementationDocument3 pagesEssbase ASO ImplementationAmit SharmaNo ratings yet
- IB SCA Assessment OverviewDocument11 pagesIB SCA Assessment OverviewShayla LeeNo ratings yet
- Binary Search TreesDocument28 pagesBinary Search TreesPriya SharmaNo ratings yet
- Hamming Code ExamplesDocument12 pagesHamming Code Examplesnuck_LNo ratings yet
- Note On Data AnalyticsDocument21 pagesNote On Data AnalyticsLOOPY GAMINGNo ratings yet
- 03 - Exploring Your Data With SQLDocument62 pages03 - Exploring Your Data With SQLnhungtran6392No ratings yet
- Eduprojecttopics Com Product Stock Management System Project ReportDocument12 pagesEduprojecttopics Com Product Stock Management System Project ReportDawitNo ratings yet
- Dana SyahputraDocument8 pagesDana SyahputraNabil ShawabNo ratings yet
- Data Science Master Class 2023Document8 pagesData Science Master Class 2023giriprasad gunalanNo ratings yet
- ICICI Prudential Life InsuranceDocument8 pagesICICI Prudential Life Insuranceimamashraf1No ratings yet
- Lufthansa Celonis WS2020 Final ReportDocument26 pagesLufthansa Celonis WS2020 Final Reportshaikseema9154No ratings yet
- Chapter 5: Designing Databases: Using A Database Design ProcessDocument13 pagesChapter 5: Designing Databases: Using A Database Design Processsirajul islamNo ratings yet
- Data Modeling and Database Design 2nd Edition Umanath Solutions Manual DownloadDocument16 pagesData Modeling and Database Design 2nd Edition Umanath Solutions Manual DownloadYvone Soto100% (22)
- LL. M. (One Year Course) All - 2019-20Document36 pagesLL. M. (One Year Course) All - 2019-20Adarsha MaityNo ratings yet
- Mageta Project2Document21 pagesMageta Project2Zakaria MtunyàNo ratings yet
- Channel Coding & Interleaving - Chap 9Document39 pagesChannel Coding & Interleaving - Chap 9Ghulam RabbaniNo ratings yet
- Week1-Linked ListDocument12 pagesWeek1-Linked ListlindytindylindtNo ratings yet
- Coolio TrloaDocument37 pagesCoolio TrloaAbeer ReaderNo ratings yet
- SQL Server Interview Questions : - BI IntelligenceDocument8 pagesSQL Server Interview Questions : - BI Intelligenceshivprasad_koiralaNo ratings yet