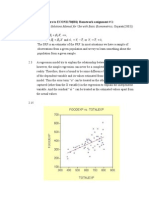
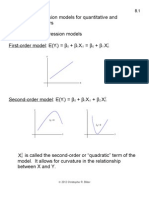
You might also like
- Basic Econometrics Chapter 3 SolutionsDocument13 pagesBasic Econometrics Chapter 3 Solutionstariqmtch71% (7)
- Microeconomics Solutions 02Document27 pagesMicroeconomics Solutions 02monkeyyed100% (2)
- pricei = β + β sqfti + β agei + β baths + e: Question 1 (7 marks)Document11 pagespricei = β + β sqfti + β agei + β baths + e: Question 1 (7 marks)MinzaNo ratings yet
- Principles of Econometrics 4e Chapter 2 SolutionDocument33 pagesPrinciples of Econometrics 4e Chapter 2 SolutionHoyin Kwok84% (19)
- An Introduction To Generalized Linear Models (Third Edition, 2008) by Annette Dobson & Adrian Barnett Outline of Solutions For Selected ExercisesDocument23 pagesAn Introduction To Generalized Linear Models (Third Edition, 2008) by Annette Dobson & Adrian Barnett Outline of Solutions For Selected ExercisesR R Romero MontoyaNo ratings yet
- Solutions Manual to accompany Introduction to Linear Regression AnalysisFrom EverandSolutions Manual to accompany Introduction to Linear Regression AnalysisRating: 1 out of 5 stars1/5 (1)
- Mroz ReplicationDocument9 pagesMroz ReplicationMateo RiveraNo ratings yet
- Suggested Answers To ECON2170 (001) Homework Assignment # 1:: U X Y X Y Y Y U U Y YDocument7 pagesSuggested Answers To ECON2170 (001) Homework Assignment # 1:: U X Y X Y Y Y U U Y YPilSeung HeoNo ratings yet
- Extensions of The Two-Variable Linear Regression Model: TrueDocument13 pagesExtensions of The Two-Variable Linear Regression Model: TrueshrutiNo ratings yet
- SW 2e Ex ch05Document5 pagesSW 2e Ex ch05Nicole Dos AnjosNo ratings yet
- Polynomial Curve FittingDocument44 pagesPolynomial Curve FittingHector Ledesma IIINo ratings yet
- Ch17 Curve FittingDocument44 pagesCh17 Curve FittingSandip GaikwadNo ratings yet
- Chapter 12 11Document15 pagesChapter 12 11Ngọc YếnNo ratings yet
- 6013B0519Y T2 Homework Solutions 20240504Document6 pages6013B0519Y T2 Homework Solutions 20240504Khanh My Ngo TranNo ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6yitagesu eshetuNo ratings yet
- Problem Set 03 - SolutionsDocument16 pagesProblem Set 03 - Solutionsecemakin21No ratings yet
- Solutions Chapter6Document19 pagesSolutions Chapter6Zodwa MngometuluNo ratings yet
- Simultaneous Linear Equations: Gauss-Seidel Method: Lesson-4-08Document10 pagesSimultaneous Linear Equations: Gauss-Seidel Method: Lesson-4-08Thiam Chun OngNo ratings yet
- Ch17 Curve FittingDocument44 pagesCh17 Curve Fittingvarunsingh214761No ratings yet
- Part 8 Linear RegressionDocument6 pagesPart 8 Linear RegressionMan SaintNo ratings yet
- Problems in Uncertainty With Solutions Physics 1Document13 pagesProblems in Uncertainty With Solutions Physics 1asNo ratings yet
- Basic Econometrics 5th Edition Gujarati Solutions ManualDocument19 pagesBasic Econometrics 5th Edition Gujarati Solutions Manualsartaneurismjmq8j6100% (21)
- ProbStat2019 01 Intro Ps SolDocument3 pagesProbStat2019 01 Intro Ps SolJosé Manuel Slater CarrascoNo ratings yet
- Chapter 8Document48 pagesChapter 8Raghav AgrawalNo ratings yet
- Regression and CorrelationDocument15 pagesRegression and CorrelationsdffsjdfhgNo ratings yet
- 3 PDF Covariance VariogramDocument22 pages3 PDF Covariance VariogramTeguh Akbar HarahapNo ratings yet
- X X B X B X B y X X B X B N B Y: QMDS 202 Data Analysis and ModelingDocument6 pagesX X B X B X B y X X B X B N B Y: QMDS 202 Data Analysis and ModelingFaithNo ratings yet
- Basic Econometrics HealthDocument183 pagesBasic Econometrics HealthAmin HaleebNo ratings yet
- Answered Sheets CombinedDocument52 pagesAnswered Sheets CombinedrayanmaazsiddigNo ratings yet
- Age Wage: WAGE Predicted To Increase If Age Is Increased by 5 Years?Document3 pagesAge Wage: WAGE Predicted To Increase If Age Is Increased by 5 Years?Jadon BuzzardNo ratings yet
- Chapter2Document20 pagesChapter2scribdsurya4uNo ratings yet
- Solutions To The Exercises: SolutionDocument105 pagesSolutions To The Exercises: Solutionaanchal singhNo ratings yet
- Solutions To The Exercises: SolutionDocument105 pagesSolutions To The Exercises: Solutionrizwan ghafoorNo ratings yet
- Stat 372 Midterm W14 SolutionDocument4 pagesStat 372 Midterm W14 SolutionAdil AliNo ratings yet
- ch13 AnsDocument10 pagesch13 AnsTân Dương100% (1)
- Ch6 (2) Curve FittingDocument15 pagesCh6 (2) Curve FittingMd. Tanvir AhmedNo ratings yet
- Chapter # 6: Multiple Regression Analysis: The Problem of EstimationDocument43 pagesChapter # 6: Multiple Regression Analysis: The Problem of EstimationRas DawitNo ratings yet
- EconomicsDocument54 pagesEconomicsObaydur RahmanNo ratings yet
- Econometrics ExamDocument8 pagesEconometrics Examprnh88No ratings yet
- Chapter5 - Solution ManualDocument4 pagesChapter5 - Solution ManualMinh Châu Tạ ThịNo ratings yet
- Assignment 2 (2015F)Document8 pagesAssignment 2 (2015F)iamnuaiNo ratings yet
- Answers To Homework 1: Exercise 1.1Document5 pagesAnswers To Homework 1: Exercise 1.1Osman Furkan AbbasogluNo ratings yet
- Dummy Variable Regression Models 9.1:, Gujarati and PorterDocument18 pagesDummy Variable Regression Models 9.1:, Gujarati and PorterTân DươngNo ratings yet
- Multivariate Censored Regression: Karl G J Oreskog 20 January 2004Document11 pagesMultivariate Censored Regression: Karl G J Oreskog 20 January 2004Zain AsaahiNo ratings yet
- Business Statistics Canadian 3rd Edition Sharpe Solutions ManualDocument33 pagesBusiness Statistics Canadian 3rd Edition Sharpe Solutions Manualhymarbecurllzkit100% (22)
- Chiang Wainwright Fundamental Methods CH 2 3 SolutionsDocument7 pagesChiang Wainwright Fundamental Methods CH 2 3 Solutionsbonadie60% (5)
- Solution Chapter 6 Tan BookDocument24 pagesSolution Chapter 6 Tan Bookanupam20099100% (2)
- IE 451 Fall 2023-2024 Homework 4 SolutionsDocument19 pagesIE 451 Fall 2023-2024 Homework 4 SolutionsAbdullah BingaziNo ratings yet
- Chapter 02Document14 pagesChapter 02Joe Di NapoliNo ratings yet
- X, X 2 1 Exp 2 1, X NDocument13 pagesX, X 2 1 Exp 2 1, X NSpica DimNo ratings yet
- ECON3208 Past Paper 2008Document9 pagesECON3208 Past Paper 2008itoki229No ratings yet
- Some Advanced Topics Using Propagation of Errors and Least Squares FittingDocument8 pagesSome Advanced Topics Using Propagation of Errors and Least Squares FittingAlessandro TrigilioNo ratings yet
- Bivariate Regression AnalysisDocument15 pagesBivariate Regression AnalysisCarmichael MarlinNo ratings yet
- StudyMaterial FormulaeEtc11Document22 pagesStudyMaterial FormulaeEtc11Ajay Pawar100% (1)
- Simple Linear Regression (Chapter 11) : Review of Some Inference and Notation: A Common Population Mean ModelDocument24 pagesSimple Linear Regression (Chapter 11) : Review of Some Inference and Notation: A Common Population Mean ModelHaizhou ChenNo ratings yet
- Finite Difference Method 10EL20Document34 pagesFinite Difference Method 10EL20muhammad_sarwar_2775% (8)
- Numerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionDocument23 pagesNumerical Solution of Ordinary Differential Equations Part 5 - Least Square RegressionMelih TecerNo ratings yet
- Business Research Methods: Introductory Lecture NotesDocument445 pagesBusiness Research Methods: Introductory Lecture NotesMiguel PereiraNo ratings yet
- EC212: Introduction To Econometrics Multiple Regression: Inference (Wooldridge, Ch. 4)Document89 pagesEC212: Introduction To Econometrics Multiple Regression: Inference (Wooldridge, Ch. 4)SHUMING ZHUNo ratings yet
- Data Science Bootcamp - UG - V1 - 0324Document30 pagesData Science Bootcamp - UG - V1 - 0324bidyutNo ratings yet
- Nonlinear Relationships: Y X X X X EYXDocument23 pagesNonlinear Relationships: Y X X X X EYXEmmanuella EmefeNo ratings yet
- Estadística Clase 7Document24 pagesEstadística Clase 7Andres GaortNo ratings yet
- Criminal Justice Studies A CriticalDocument22 pagesCriminal Justice Studies A CriticalCOLDNo ratings yet
- CLM: Review: - OLS EstimationDocument44 pagesCLM: Review: - OLS EstimationS StanevNo ratings yet
- Effect of Earnings Management On The Firm Value of The Listed Nigerian Oil and Gas CompaniesDocument23 pagesEffect of Earnings Management On The Firm Value of The Listed Nigerian Oil and Gas CompaniesAudit and Accounting ReviewNo ratings yet
- SyllabusDocument114 pagesSyllabusInnocent MonkNo ratings yet
- Koyck - Polynomial DL (PDL) : - A Form of Short-Term Model - Explanatory Variables - Three ComponentsDocument5 pagesKoyck - Polynomial DL (PDL) : - A Form of Short-Term Model - Explanatory Variables - Three ComponentsmazamniaziNo ratings yet
- The Slave Trade and The Origins of Mistrust in Africa: CitationDocument33 pagesThe Slave Trade and The Origins of Mistrust in Africa: CitationserenaNo ratings yet
- FDSA Unit-2Document41 pagesFDSA Unit-2vikramkaruppannan6807No ratings yet
- Https Onlinecourses - Science.psuDocument8 pagesHttps Onlinecourses - Science.psuKadiri OlanrewajuNo ratings yet
- Ward AhlquistDocument327 pagesWard AhlquistMarketSport RancaguaNo ratings yet
- Subsistence Farming and Food Security in Cameroon A Macroeconomic ApproachDocument6 pagesSubsistence Farming and Food Security in Cameroon A Macroeconomic ApproachKane GillesNo ratings yet
- 2018-Panel Data by Baun PDFDocument88 pages2018-Panel Data by Baun PDFcm_feipe100% (1)
- Cornwell and Trumbull (1994) Estimating The Economic Model of Crime With Panel DataDocument8 pagesCornwell and Trumbull (1994) Estimating The Economic Model of Crime With Panel DataGrecia Milushka Chavez UribeNo ratings yet
- Ward-Gleditsch (2008) Spatial Regression ModelsDocument87 pagesWard-Gleditsch (2008) Spatial Regression ModelsGerardo GarciaNo ratings yet
- (Advances in Econometrics) Badi H. Baltagi-Nonstationary Panels, Panel Cointegration, and Dynamic Panels-JAI Press (NY) (2000)Document337 pages(Advances in Econometrics) Badi H. Baltagi-Nonstationary Panels, Panel Cointegration, and Dynamic Panels-JAI Press (NY) (2000)Hernando HernándezNo ratings yet
- Distributed-Lag Models: Dynamic Effects of Temporary and Permanent ChangesDocument20 pagesDistributed-Lag Models: Dynamic Effects of Temporary and Permanent ChangesJuan- DaNo ratings yet
- Determinants of Economic Growth: Empirical Evidence From Russian RegionsDocument32 pagesDeterminants of Economic Growth: Empirical Evidence From Russian RegionsChristopher ImanuelNo ratings yet
- Freight Prices, Fuel Prices, and SpeedDocument15 pagesFreight Prices, Fuel Prices, and Speedsiyabonga dlaminiNo ratings yet
- B.Sc. Economics Honours - Detailed SyllabusDocument49 pagesB.Sc. Economics Honours - Detailed SyllabusNeelarka RoyNo ratings yet
- Mekelle University College of Business and Economics Departement of EconomicsDocument49 pagesMekelle University College of Business and Economics Departement of EconomicsAbdulwakil AbareshadNo ratings yet
- Does CEO Duality Really Affect Corporate Performance?: Khaled ElsayedDocument12 pagesDoes CEO Duality Really Affect Corporate Performance?: Khaled ElsayedRahul PramaniNo ratings yet
- IAPRI Technical Training-Intro To Applied Econometrics 2018 06 25+-+Nicole+MasonDocument29 pagesIAPRI Technical Training-Intro To Applied Econometrics 2018 06 25+-+Nicole+MasonBebeelacNo ratings yet
- Quantitative AnalysisDocument255 pagesQuantitative AnalysisIdriss Armel Kougoum50% (2)
- Q1.1 Model 1: totmhinc = βDocument5 pagesQ1.1 Model 1: totmhinc = βStanely NdlovuNo ratings yet
- CVDocument13 pagesCVapi-286386211No ratings yet