You might also like
- Grep Command in LinuxDocument7 pagesGrep Command in LinuxShivam PandeyNo ratings yet
- Grep CommandDocument14 pagesGrep CommandDarkoNo ratings yet
- Grep Command in Unix and LinuxDocument17 pagesGrep Command in Unix and LinuxPankaj SinghNo ratings yet
- 15 Practical Grep Command Examples in Linux / Unix: Home Free Ebook Start Here Contact AboutDocument30 pages15 Practical Grep Command Examples in Linux / Unix: Home Free Ebook Start Here Contact AboutGenijalac11No ratings yet
- Linux Regular ExpressionDocument3 pagesLinux Regular ExpressionGansari GheorgheNo ratings yet
- Search For The Given String in A Single FileDocument7 pagesSearch For The Given String in A Single FileirshadNo ratings yet
- Search For The Given String in A Single FileDocument7 pagesSearch For The Given String in A Single Filebaladivya15No ratings yet
- Grep Awk SedDocument9 pagesGrep Awk SedvishnuselvaNo ratings yet
- Regular Expressions in Grep Command With 10 Examples - Part IDocument5 pagesRegular Expressions in Grep Command With 10 Examples - Part Iqaws1234No ratings yet
- GREP Command Search For The Given String in A Single FileDocument20 pagesGREP Command Search For The Given String in A Single FilebalaNo ratings yet
- Unix Text AnalysisDocument9 pagesUnix Text AnalysisjimbotysonNo ratings yet
- Grep Command ExamplesDocument3 pagesGrep Command ExamplesqadasfdafNo ratings yet
- Sed - AwkDocument7 pagesSed - Awksvnbadrinath8335No ratings yet
- E - B R E: Exercises - Basic Regular ExpressionsDocument6 pagesE - B R E: Exercises - Basic Regular ExpressionsJoakim NgatungaNo ratings yet
- U4 - Shell Pattern MatchingDocument5 pagesU4 - Shell Pattern MatchingShantanu AgnihotriNo ratings yet
- 20.10 Filters-Text Processing CommandsDocument14 pages20.10 Filters-Text Processing CommandsPavankumar KaredlaNo ratings yet
- 15 Practical Grep Examples in Linux UnixDocument37 pages15 Practical Grep Examples in Linux Unixmarcops88No ratings yet
- Grep and Regular Expressions: Line and Word AnchorsDocument2 pagesGrep and Regular Expressions: Line and Word Anchorsmarco rossiNo ratings yet
- Grep, Awk and Sed - Three VERY Useful Command-Line UtilitiesDocument9 pagesGrep, Awk and Sed - Three VERY Useful Command-Line UtilitiesRadhika EtigeddaNo ratings yet
- 6 Handy Regular Expressions Every Front-End Developer Should KnowDocument8 pages6 Handy Regular Expressions Every Front-End Developer Should KnowloloNo ratings yet
- Assignment 7Document4 pagesAssignment 7yashNo ratings yet
- Filer CommandDocument38 pagesFiler CommandYatindraNo ratings yet
- C TutorialDocument10 pagesC TutorialhpmaxNo ratings yet
- Unix Pipes Filters ExplainedDocument3 pagesUnix Pipes Filters ExplainedAnne DuttaNo ratings yet
- Using Grep, TR and Sed With Regular ExpressionsDocument7 pagesUsing Grep, TR and Sed With Regular ExpressionsErwinMacaraigNo ratings yet
- Chapter 06 Regular Expression: ConclusionDocument16 pagesChapter 06 Regular Expression: ConclusionCristian CosteaNo ratings yet
- 15 Practical Grep Command Examples in Linux - UNIXDocument15 pages15 Practical Grep Command Examples in Linux - UNIXJaswanth TejaNo ratings yet
- Linux Grep CommandDocument7 pagesLinux Grep CommandZinphyothantNo ratings yet
- Grep and Sed CommandsDocument17 pagesGrep and Sed Commandssat_ksNo ratings yet
- 18bcs6516, Vipin, OS Worksheet FinalDocument2 pages18bcs6516, Vipin, OS Worksheet FinalBLACKER EMPIRENo ratings yet
- Linux CLInotesDocument15 pagesLinux CLInotesZinphyothantNo ratings yet
- Linux AssignmentDocument3 pagesLinux AssignmentMuhammad_Bilal_5804No ratings yet
- Regex PDFDocument15 pagesRegex PDFPraveen ChoudharyNo ratings yet
- Bash Scripting CheatsheetDocument5 pagesBash Scripting CheatsheetaaronNo ratings yet
- Pciexpresstechnology3 161107170938Document2 pagesPciexpresstechnology3 161107170938Ajay GunjiNo ratings yet
- Chapter 2Document5 pagesChapter 22106 Ayush GadhiyaNo ratings yet
- Regular ExpressionDocument11 pagesRegular ExpressionFawzi GharibNo ratings yet
- Chapter 14. Perl - The Master Manipulator IntroducitonDocument13 pagesChapter 14. Perl - The Master Manipulator IntroducitonjayanthmjNo ratings yet
- Filter Using Regular ExpressionsDocument11 pagesFilter Using Regular ExpressionsEkantHiremathNo ratings yet
- Lex and YaccDocument8 pagesLex and YaccBalaji LoyisettiNo ratings yet
- Basics of Shell ScriptingDocument9 pagesBasics of Shell ScriptingDushyant SinghNo ratings yet
- CRUNCH (Manual)Document14 pagesCRUNCH (Manual)04-ADRITO GHOSHNo ratings yet
- Files:: Ls Ls - L Ls - A Esc K More FilenameDocument9 pagesFiles:: Ls Ls - L Ls - A Esc K More FilenameTulasi KonduruNo ratings yet
- Practical 9 Grep CommandDocument3 pagesPractical 9 Grep CommandVishal BirajdarNo ratings yet
- Teacher:: Dr. Rafiqul Zaman Khan, Professor HomepageDocument18 pagesTeacher:: Dr. Rafiqul Zaman Khan, Professor HomepageMohammad SulaimanNo ratings yet
- Fall 2011 Bachelor of Computer Application (BCA) - Semester 1 BC0034 - Computer Concepts & C Programming (Book ID: B0678) Assignment Set - 1Document28 pagesFall 2011 Bachelor of Computer Application (BCA) - Semester 1 BC0034 - Computer Concepts & C Programming (Book ID: B0678) Assignment Set - 1Sintu MathurNo ratings yet
- Turbo C/C++ For Windows 7/8/8.1 and 10 32/64 Bit : CodeplexDocument4 pagesTurbo C/C++ For Windows 7/8/8.1 and 10 32/64 Bit : Codeplexrahul100% (1)
- Shell Scripting LinuxDocument15 pagesShell Scripting LinuxMehdiNo ratings yet
- Javascript Regular Expressions and Exception Handling: Prof - N. Nalini Ap (SR) Scope Vit VelloreDocument30 pagesJavascript Regular Expressions and Exception Handling: Prof - N. Nalini Ap (SR) Scope Vit VelloreHansraj RouniyarNo ratings yet
- Linux and Shell Scripting: Shubhankar Thakur (Ethashu)Document23 pagesLinux and Shell Scripting: Shubhankar Thakur (Ethashu)AashishNo ratings yet
- The Grep Command: SR - No. Option & DescriptionDocument2 pagesThe Grep Command: SR - No. Option & DescriptionrahulNo ratings yet
- Regular Expressions Tutorial: VisitDocument31 pagesRegular Expressions Tutorial: VisitkolkarevinayNo ratings yet
- Linux and Unix Grep CommandDocument13 pagesLinux and Unix Grep CommandRockyNo ratings yet
- Ch7 - Search and Text ManipulationDocument33 pagesCh7 - Search and Text ManipulationSarah AmiriNo ratings yet
- Crafting An Interpreter Part 1 - Parsing and Grammars - Martin - Holzherr - CodePrDocument12 pagesCrafting An Interpreter Part 1 - Parsing and Grammars - Martin - Holzherr - CodePrAntony IngramNo ratings yet
- Program Name BSC It V Assignment - 2 (Faculty Name) - Prof Pranav ShrivastavaDocument7 pagesProgram Name BSC It V Assignment - 2 (Faculty Name) - Prof Pranav ShrivastavaSanjarbekNo ratings yet
- SW LAB 10 FilterDocument45 pagesSW LAB 10 Filtervaidikkumar2508No ratings yet
- Latex/Source Code Listings: 1 Using The Listings PackageDocument6 pagesLatex/Source Code Listings: 1 Using The Listings PackageGetnet Demil Jr.No ratings yet
- List of Special Characters: Note For MS Windows UsersDocument1 pageList of Special Characters: Note For MS Windows UsersAnh NguyenNo ratings yet
- Ch10 NoteDocument91 pagesCh10 NoteEUNAH LimNo ratings yet
- Lecture Outlines: Evolution, Biodiversity, and Population EcologyDocument80 pagesLecture Outlines: Evolution, Biodiversity, and Population EcologyEUNAH LimNo ratings yet
- Lecture Outlines: Species Interactions and Community EcologyDocument96 pagesLecture Outlines: Species Interactions and Community EcologyEUNAH LimNo ratings yet
- Ch1 NoteDocument60 pagesCh1 NoteEUNAH LimNo ratings yet
- Ch5 NoteDocument77 pagesCh5 NoteEUNAH LimNo ratings yet
- Lecture Outlines: Species Interactions and Community EcologyDocument96 pagesLecture Outlines: Species Interactions and Community EcologyEUNAH LimNo ratings yet
- Ch8 NoteDocument77 pagesCh8 NoteEUNAH LimNo ratings yet
- Ch9 NoteDocument94 pagesCh9 NoteEUNAH LimNo ratings yet
- Lecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyDocument90 pagesLecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyEUNAH LimNo ratings yet
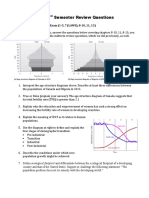
- Apes 1 Semester Review Questions: Chapters Covered On Final Exam (1-5, 7 (LAWS), 8-10, 11, 13)Document3 pagesApes 1 Semester Review Questions: Chapters Covered On Final Exam (1-5, 7 (LAWS), 8-10, 11, 13)EUNAH LimNo ratings yet
- Lecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyDocument90 pagesLecture Outlines: Earth's Physical Systems: Matter, Energy, and GeologyEUNAH LimNo ratings yet
- Ch3.1 GeologyDocument48 pagesCh3.1 GeologyEUNAH LimNo ratings yet
- Lecture Outlines: Evolution, Biodiversity, and Population EcologyDocument80 pagesLecture Outlines: Evolution, Biodiversity, and Population EcologyEUNAH LimNo ratings yet
- Ch1 NoteDocument60 pagesCh1 NoteEUNAH LimNo ratings yet
- This Section Is in Addition To Chapter 3Document30 pagesThis Section Is in Addition To Chapter 3EUNAH LimNo ratings yet
- Apes Review 1Document3 pagesApes Review 1EUNAH LimNo ratings yet
- CH 21Document20 pagesCH 21EUNAH LimNo ratings yet
- Climate Change and Ozone LossDocument10 pagesClimate Change and Ozone LossEUNAH LimNo ratings yet
- CH 15Document71 pagesCH 15EUNAH LimNo ratings yet
- AP Environmental Science: Environmental Problems, Causes, and SustainabilityDocument24 pagesAP Environmental Science: Environmental Problems, Causes, and SustainabilityEUNAH LimNo ratings yet
- CH 2Document40 pagesCH 2EUNAH LimNo ratings yet
- Solid and Hazardous WasteDocument22 pagesSolid and Hazardous WasteEUNAH LimNo ratings yet
- Living in The Environment, 18E: Urbanization and SustainabilityDocument54 pagesLiving in The Environment, 18E: Urbanization and SustainabilityEUNAH LimNo ratings yet
- Test Review Energy Efficiency and Renewable EnergyDocument39 pagesTest Review Energy Efficiency and Renewable EnergyEUNAH LimNo ratings yet
- Living in The Environment, 18E: Urbanization and SustainabilityDocument54 pagesLiving in The Environment, 18E: Urbanization and SustainabilityEUNAH LimNo ratings yet
- Nonrenewable Energy ResourcesDocument54 pagesNonrenewable Energy ResourcesEUNAH LimNo ratings yet
- CH 19Document35 pagesCH 19EUNAH LimNo ratings yet
- CH 18Document36 pagesCH 18EUNAH LimNo ratings yet
- CH 19Document35 pagesCH 19EUNAH LimNo ratings yet
- Water Resources and Water PollutionDocument122 pagesWater Resources and Water PollutionEUNAH LimNo ratings yet
- Modern Compiler Design T1 - OverviewDocument35 pagesModern Compiler Design T1 - Overviewmeatscribd4dlNo ratings yet
- Detailed SyllabusDocument61 pagesDetailed SyllabusNinja WarriorNo ratings yet
- Manual - IP - Firewall - L7 - MikroTik WikiDocument3 pagesManual - IP - Firewall - L7 - MikroTik WikiachainyaNo ratings yet
- Confirmit v16 - Scripting - Rev1Document242 pagesConfirmit v16 - Scripting - Rev1Crazzy KiddNo ratings yet
- Apache's Mod RewriteDocument14 pagesApache's Mod RewriteJasmina MitrovicNo ratings yet
- Modeler Jython Scripting Automation BookDocument264 pagesModeler Jython Scripting Automation BookSomnath KhamaruNo ratings yet
- Chapter 2 - Lexical AnalyserDocument38 pagesChapter 2 - Lexical AnalyserYitbarek MurcheNo ratings yet
- 6 Cse - Cs8651 Ip Unit 2Document91 pages6 Cse - Cs8651 Ip Unit 2Sanjay S100% (1)
- scriptEDA PinhongDocument8 pagesscriptEDA Pinhonghariji100% (1)
- IQ Bot Custom Logic Documentation - Advanced DraftDocument19 pagesIQ Bot Custom Logic Documentation - Advanced Draftshub001No ratings yet
- GNU Emacs 21 Reference CardDocument2 pagesGNU Emacs 21 Reference CardJeff PrattNo ratings yet
- Understanding JSONSchemaDocument74 pagesUnderstanding JSONSchemaAlexandre Junior Monteiro lopesNo ratings yet
- ADA2 Notes Ch18Document45 pagesADA2 Notes Ch18Prashanth MohanNo ratings yet
- CD NotesDocument69 pagesCD NotesgbaleswariNo ratings yet
- La Mitrana Curs 4Document21 pagesLa Mitrana Curs 4Popa StefanNo ratings yet
- Ebase Xi FundamentalsDocument404 pagesEbase Xi Fundamentalsa3scribdNo ratings yet
- Perlre - Perl Regular Expressions Used in WMDocument36 pagesPerlre - Perl Regular Expressions Used in WMstefidufNo ratings yet
- APS 6.0 Defend Unit 3 View Attack Details - 20180823 PDFDocument82 pagesAPS 6.0 Defend Unit 3 View Attack Details - 20180823 PDFmasterlinh2008No ratings yet
- Unit I Finite Automata 1. What Is Deductive Proof?Document9 pagesUnit I Finite Automata 1. What Is Deductive Proof?Jegathambal GaneshanNo ratings yet
- Pyneng Readthedocs Io en LatestDocument702 pagesPyneng Readthedocs Io en LatestNgọc Duy VõNo ratings yet
- TCL Regular ExpressionsDocument5 pagesTCL Regular ExpressionsVeeranjaneyulu DhikondaNo ratings yet
- Mule 3Document32 pagesMule 3Rhushikesh ChitaleNo ratings yet
- Simple Event Correlator For Real-Time Security Log MonitoringDocument12 pagesSimple Event Correlator For Real-Time Security Log MonitoringdasxaxNo ratings yet
- chapter6PHPTUT NicephotogDocument2 pageschapter6PHPTUT NicephotogSamuel Alexander MarchantNo ratings yet
- Unix Shell Scripting and Text Processing ToolsDocument2 pagesUnix Shell Scripting and Text Processing ToolsGirish DadlaniNo ratings yet
- Introduction StructureDocument40 pagesIntroduction StructureG KalaiarasiNo ratings yet
- Essential Perl One-LinersDocument92 pagesEssential Perl One-LinersMichael DinglerNo ratings yet
- Perl Bioinf 0411 PDFDocument69 pagesPerl Bioinf 0411 PDFNitin KhadseNo ratings yet
- Manpage of VSFTPD - ConfDocument1 pageManpage of VSFTPD - ConfNico SullyNo ratings yet
- Python Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)From EverandPython Programming For Beginners: Learn The Basics Of Python Programming (Python Crash Course, Programming for Dummies)Rating: 5 out of 5 stars5/5 (1)
- Clean Code: A Handbook of Agile Software CraftsmanshipFrom EverandClean Code: A Handbook of Agile Software CraftsmanshipRating: 5 out of 5 stars5/5 (13)
- Learn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.From EverandLearn Python Programming for Beginners: Best Step-by-Step Guide for Coding with Python, Great for Kids and Adults. Includes Practical Exercises on Data Analysis, Machine Learning and More.Rating: 5 out of 5 stars5/5 (34)
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepFrom EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepRating: 4.5 out of 5 stars4.5/5 (19)
- Excel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceFrom EverandExcel Essentials: A Step-by-Step Guide with Pictures for Absolute Beginners to Master the Basics and Start Using Excel with ConfidenceNo ratings yet
- Once Upon an Algorithm: How Stories Explain ComputingFrom EverandOnce Upon an Algorithm: How Stories Explain ComputingRating: 4 out of 5 stars4/5 (43)
- Software Development: BCS Level 4 Certificate in IT study guideFrom EverandSoftware Development: BCS Level 4 Certificate in IT study guideRating: 3.5 out of 5 stars3.5/5 (2)
- How to Make a Video Game All By Yourself: 10 steps, just you and a computerFrom EverandHow to Make a Video Game All By Yourself: 10 steps, just you and a computerRating: 5 out of 5 stars5/5 (1)
- The Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!From EverandThe Advanced Roblox Coding Book: An Unofficial Guide, Updated Edition: Learn How to Script Games, Code Objects and Settings, and Create Your Own World!Rating: 4.5 out of 5 stars4.5/5 (2)
- GAMEDEV: 10 Steps to Making Your First Game SuccessfulFrom EverandGAMEDEV: 10 Steps to Making Your First Game SuccessfulRating: 4.5 out of 5 stars4.5/5 (12)
- HTML, CSS, and JavaScript Mobile Development For DummiesFrom EverandHTML, CSS, and JavaScript Mobile Development For DummiesRating: 4 out of 5 stars4/5 (10)
- Mastering JavaScript: The Complete Guide to JavaScript MasteryFrom EverandMastering JavaScript: The Complete Guide to JavaScript MasteryRating: 5 out of 5 stars5/5 (1)
- The Ultimate Python Programming Guide For Beginner To IntermediateFrom EverandThe Ultimate Python Programming Guide For Beginner To IntermediateRating: 4.5 out of 5 stars4.5/5 (3)
- Coding for Kids Ages 9-15: Simple HTML, CSS and JavaScript lessons to get you started with Programming from ScratchFrom EverandCoding for Kids Ages 9-15: Simple HTML, CSS and JavaScript lessons to get you started with Programming from ScratchRating: 4.5 out of 5 stars4.5/5 (4)
- Understanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerFrom EverandUnderstanding Software: Max Kanat-Alexander on simplicity, coding, and how to suck less as a programmerRating: 4.5 out of 5 stars4.5/5 (44)
- Narrative Design for Indies: Getting StartedFrom EverandNarrative Design for Indies: Getting StartedRating: 4.5 out of 5 stars4.5/5 (5)
- Blockchain: The complete guide to understanding Blockchain Technology for beginners in record timeFrom EverandBlockchain: The complete guide to understanding Blockchain Technology for beginners in record timeRating: 4.5 out of 5 stars4.5/5 (34)
- Django Unleashed: Building Web Applications with Python's FrameworkFrom EverandDjango Unleashed: Building Web Applications with Python's FrameworkNo ratings yet
- Python Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsFrom EverandPython Programming : How to Code Python Fast In Just 24 Hours With 7 Simple StepsRating: 3.5 out of 5 stars3.5/5 (54)