You might also like
- 2018 Alberto Rossi Fall Seminar Paper 1 Stock Market ReturnsDocument44 pages2018 Alberto Rossi Fall Seminar Paper 1 Stock Market Returns1by20is020No ratings yet
- Crowding and Factor ReturnDocument51 pagesCrowding and Factor ReturnShri Krishna BhatiNo ratings yet
- Modelling Market Implied Ratings Using LASSO Variable Selection TechniquesDocument47 pagesModelling Market Implied Ratings Using LASSO Variable Selection TechniquesHerleif HaavikNo ratings yet
- Portfolio and Investment Analysis with SAS: Financial Modeling Techniques for OptimizationFrom EverandPortfolio and Investment Analysis with SAS: Financial Modeling Techniques for OptimizationRating: 3 out of 5 stars3/5 (1)
- Journal24_IFTA_pandiniDocument28 pagesJournal24_IFTA_pandiniboguforumNo ratings yet
- CH 1Document11 pagesCH 1321312 312123No ratings yet
- Stock Market Literature ReviewDocument8 pagesStock Market Literature Reviewsmvancvkg100% (1)
- Selection of A Portfolio of Pairs Based On Cointegration: A Statistical Arbitrage StrategyDocument32 pagesSelection of A Portfolio of Pairs Based On Cointegration: A Statistical Arbitrage StrategyJulio CostaNo ratings yet
- Machine Learning and Fund Characteristics Help To Select Mutual Funds With Positive AlphaDocument22 pagesMachine Learning and Fund Characteristics Help To Select Mutual Funds With Positive Alphagerald372901No ratings yet
- Group Assignment CompletedDocument68 pagesGroup Assignment CompletedHengyi LimNo ratings yet
- A Dynamic Model of Hedging and Speculation in The Commodity Futures MarketsDocument34 pagesA Dynamic Model of Hedging and Speculation in The Commodity Futures Marketsgogayin869No ratings yet
- Forecasting Volatility of Stock Indices With ARCH ModelDocument18 pagesForecasting Volatility of Stock Indices With ARCH Modelravi_nyseNo ratings yet
- Finance and Economics Discussion Series Divisions of Research & Statistics and Monetary Affairs Federal Reserve Board, Washington, D.CDocument28 pagesFinance and Economics Discussion Series Divisions of Research & Statistics and Monetary Affairs Federal Reserve Board, Washington, D.CrakhalbanglaNo ratings yet
- De Freitas Rocha Cam Bar A 2020Document10 pagesDe Freitas Rocha Cam Bar A 2020Wanderson MonteiroNo ratings yet
- NO trendSSRN-id3523001Document41 pagesNO trendSSRN-id3523001Loulou DePanamNo ratings yet
- Technical Report Writing For Ca2 ExaminationDocument6 pagesTechnical Report Writing For Ca2 ExaminationAishee DuttaNo ratings yet
- 2.2 Article 2 - Accounting Comparability and Relative Performance Evaluation by Capital MarketsDocument40 pages2.2 Article 2 - Accounting Comparability and Relative Performance Evaluation by Capital MarketsMonica Ratu LeoNo ratings yet
- Statistical Arbitrage Powered by Explainable Artificial IntelligenceDocument17 pagesStatistical Arbitrage Powered by Explainable Artificial Intelligencefabio olivaNo ratings yet
- MHF 2019 062 Boris FaysDocument53 pagesMHF 2019 062 Boris Faysnexxus hcNo ratings yet
- JOURNAL OF FINANCIAL ECONOMETRICS-2005-Ferreira-126-68Document43 pagesJOURNAL OF FINANCIAL ECONOMETRICS-2005-Ferreira-126-68Andreas KarasNo ratings yet
- Rjef3 2020p134-148Document15 pagesRjef3 2020p134-148lijanamano6No ratings yet
- Intraday Market Predictability - A Machine Learning ApproachDocument57 pagesIntraday Market Predictability - A Machine Learning ApproachsuneetaNo ratings yet
- Stock Price Prediction Using Machine Learning AlgorithmsDocument9 pagesStock Price Prediction Using Machine Learning AlgorithmsIJRASETPublicationsNo ratings yet
- Trading Strategies Market Colour Ravi Kashyap 2018Document26 pagesTrading Strategies Market Colour Ravi Kashyap 2018barapatrerahul544No ratings yet
- Accounting Accruals and Information Asymmetry in Europe: Antonio Cerqueira, Claudia PereiraDocument24 pagesAccounting Accruals and Information Asymmetry in Europe: Antonio Cerqueira, Claudia PereiraSimonNisjaPutraZaiNo ratings yet
- SAE MLP PaperDocument61 pagesSAE MLP PaperBartosz BieganowskiNo ratings yet
- Group - Vii, Nse Project-2Document11 pagesGroup - Vii, Nse Project-2jaikumar21012004No ratings yet
- Dybvig Ross 85 Differential Information and Performance Measurement Using A Security Market LineDocument18 pagesDybvig Ross 85 Differential Information and Performance Measurement Using A Security Market LinePeterParker1983No ratings yet
- Applied Soft Computing Journal: Yu-Pei Huang, Meng-Feng YenDocument14 pagesApplied Soft Computing Journal: Yu-Pei Huang, Meng-Feng YenNirmala HanifahNo ratings yet
- Timing The Market With A Combination of Moving Averages: Combination of Moving AveragesDocument43 pagesTiming The Market With A Combination of Moving Averages: Combination of Moving AveragesTed MaragNo ratings yet
- Deep Reinforcement Learning in Agent Based Financial Market SimulationDocument17 pagesDeep Reinforcement Learning in Agent Based Financial Market SimulationQuant TradingNo ratings yet
- Economics Letters: Haejung Na, Soonho KimDocument7 pagesEconomics Letters: Haejung Na, Soonho KimHeni AgustianiNo ratings yet
- Efficient MArket Hypothesis and ForecastingDocument13 pagesEfficient MArket Hypothesis and ForecastingDalia Hussniey AqeelNo ratings yet
- Take Profit and Stop Loss Trading Strategies Comparison in Combination With An MACD Trading SystemDocument23 pagesTake Profit and Stop Loss Trading Strategies Comparison in Combination With An MACD Trading SystemthyagosmesmeNo ratings yet
- Algorithmic_trading_on_financial_time_series_usingDocument20 pagesAlgorithmic_trading_on_financial_time_series_usingRohit shindeNo ratings yet
- MP1 ReportDocument9 pagesMP1 ReportRachit BhagatNo ratings yet
- Regime-Switching Factor Investing With Hidden Markov ModelsDocument15 pagesRegime-Switching Factor Investing With Hidden Markov ModelsHao OuYangNo ratings yet
- Application of Artificial Intelligence in Stock Market Forecasting: A Critique, Review, and Research AgendaDocument34 pagesApplication of Artificial Intelligence in Stock Market Forecasting: A Critique, Review, and Research Agendasuhier AbidNo ratings yet
- Stock Market Volatility Forecasting: Do We Need High-Frequency Data?Document19 pagesStock Market Volatility Forecasting: Do We Need High-Frequency Data?Peter MolnárNo ratings yet
- Pronósticos MinoristasDocument36 pagesPronósticos MinoristasJennifer Lucia Mozo AvendanoNo ratings yet
- Dialnet TheResponsibilityOfThePartnersInTheirOwnFundsForTh 8348464Document20 pagesDialnet TheResponsibilityOfThePartnersInTheirOwnFundsForTh 8348464Laura MNo ratings yet
- Machine Learning and Credit Ratings Prediction in The Age of Fourth IndustrialDocument13 pagesMachine Learning and Credit Ratings Prediction in The Age of Fourth IndustrialJorge Luis SorianoNo ratings yet
- Pakistan Spinning Mills Financial RatiosDocument15 pagesPakistan Spinning Mills Financial RatiosDr Muhammad Mushtaq MangatNo ratings yet
- Study of Machine Learning Algorithms For Ee57d090Document13 pagesStudy of Machine Learning Algorithms For Ee57d090lijanamano6No ratings yet
- ML para Credit Scoring Bnco de España 2021Document44 pagesML para Credit Scoring Bnco de España 2021carlos225718No ratings yet
- Market Timing With Moving Averages: SSRN Electronic Journal November 2012Document40 pagesMarket Timing With Moving Averages: SSRN Electronic Journal November 20124nagNo ratings yet
- Model Insight MSCI Integrated Factor Crowding ModelDocument24 pagesModel Insight MSCI Integrated Factor Crowding ModellawparameciumzhewkNo ratings yet
- Confp01 07Document21 pagesConfp01 07crushspreadNo ratings yet
- Comparative Analysis of Stock Price Prediction Models: Generalized Linear Model (GLM), Ridge Regression, Lasso Regression, Elasticnet Regression, and Random Forest - A Case Study On NetflixDocument12 pagesComparative Analysis of Stock Price Prediction Models: Generalized Linear Model (GLM), Ridge Regression, Lasso Regression, Elasticnet Regression, and Random Forest - A Case Study On NetflixInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Machine Learning Corporate Bonds - MSC - Thesis - Nurlan - AvazliDocument42 pagesMachine Learning Corporate Bonds - MSC - Thesis - Nurlan - AvazliVichara PoolsNo ratings yet
- International Journal of Forecasting: Robert Fildes, Shaohui Ma, Stephan KolassaDocument36 pagesInternational Journal of Forecasting: Robert Fildes, Shaohui Ma, Stephan KolassaSümeyye ÖztürkNo ratings yet
- Journal of Economic Dynamics & Control: Luca Riccetti, Alberto Russo, Mauro GallegatiDocument15 pagesJournal of Economic Dynamics & Control: Luca Riccetti, Alberto Russo, Mauro GallegatiJuan José María MartínezNo ratings yet
- The Fundamentals of Fundamental Factor Models Jun2010Document15 pagesThe Fundamentals of Fundamental Factor Models Jun2010Alexander GitnikNo ratings yet
- Company Bankruptcy Prediction With SMOTEDocument8 pagesCompany Bankruptcy Prediction With SMOTEIJRASETPublicationsNo ratings yet
- Ji Trading 2020Document37 pagesJi Trading 2020BigPalabraNo ratings yet
- Journal of Monetary Economics: Miguel A. Iraola, Manuel S. SantosDocument15 pagesJournal of Monetary Economics: Miguel A. Iraola, Manuel S. Santosikhsan syahabNo ratings yet
- Business Finance AssignmentDocument15 pagesBusiness Finance AssignmentIbrahimNo ratings yet
- Travel Behaviour and Society: Gozde Ozonder, Eric J. MillerDocument25 pagesTravel Behaviour and Society: Gozde Ozonder, Eric J. MillermyrgeteNo ratings yet
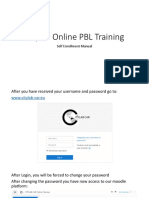
- Citylab Online PBL Training: Self Enrollment ManualDocument7 pagesCitylab Online PBL Training: Self Enrollment ManualmyrgeteNo ratings yet
- Energy Economics: Davide Ferrari, Francesco Ravazzolo, Joaquin VespignaniDocument12 pagesEnergy Economics: Davide Ferrari, Francesco Ravazzolo, Joaquin VespignanimyrgeteNo ratings yet
- Computer Communications: Markus Mäsker, Lars Nagel, André Brinkmann, Foad Lotfifar, Matthew JohnsonDocument13 pagesComputer Communications: Markus Mäsker, Lars Nagel, André Brinkmann, Foad Lotfifar, Matthew JohnsonmyrgeteNo ratings yet
- Forest Policy and Economics: Raffaele Spinelli, Natascia MagagnottiDocument5 pagesForest Policy and Economics: Raffaele Spinelli, Natascia MagagnottimyrgeteNo ratings yet
- I-1 (4) Grammar SummaryDocument1 pageI-1 (4) Grammar SummarymyrgeteNo ratings yet
- Final PDFDocument19 pagesFinal PDFMahmudul HasanNo ratings yet
- Stock MarketDocument24 pagesStock MarketRig Ved100% (2)
- A Review of The Post-Earnings-Announcement DriftDocument13 pagesA Review of The Post-Earnings-Announcement DriftH lynneNo ratings yet
- Jens Beckert, Richard Bronk - Uncertain Futures - Imaginaries, Narratives, and Calculation in The Economy-Oxford University Press (2018)Document346 pagesJens Beckert, Richard Bronk - Uncertain Futures - Imaginaries, Narratives, and Calculation in The Economy-Oxford University Press (2018)Tony KurianNo ratings yet
- Day2 1Document111 pagesDay2 1Antariksh ShahwalNo ratings yet
- Behavioral FinanceDocument2 pagesBehavioral Financeirfan ullah khanNo ratings yet
- Mutual Funds: Systematic Investment Plan: S.Srimaan Ramachandra Raja Sohail HiraniDocument8 pagesMutual Funds: Systematic Investment Plan: S.Srimaan Ramachandra Raja Sohail HiraniStudent ProjectsNo ratings yet
- Corporate Financing Decisions and Efficient Capital MarketsDocument53 pagesCorporate Financing Decisions and Efficient Capital MarketsalexanderNo ratings yet
- Market Efficiency and Empirical Evidence: EMH TestsDocument86 pagesMarket Efficiency and Empirical Evidence: EMH TestsVaidyanathan RavichandranNo ratings yet
- Equity QuestionsDocument9 pagesEquity QuestionsDuyên HànNo ratings yet
- Industrial Revolution 4 0 Economic Foundations and Practical ImplicationsDocument261 pagesIndustrial Revolution 4 0 Economic Foundations and Practical ImplicationsБогдан КнишNo ratings yet
- Financial Astrology BooksDocument16 pagesFinancial Astrology BooksRajaNo ratings yet
- Efficient Market HypothesisDocument22 pagesEfficient Market HypothesisYohana Ray100% (1)
- CMT L1 Question Bank (Set 2)Document45 pagesCMT L1 Question Bank (Set 2)Nistha Singh100% (2)
- S 15 - Efficient Capital Markets and Behavioral ChallengesDocument27 pagesS 15 - Efficient Capital Markets and Behavioral ChallengesAninda DuttaNo ratings yet
- Influence of Basic Human Behaviors (Influenced by Brain Architecture and Function), and Past Traumatic Events On Investor Behavior and Financial BiasDocument21 pagesInfluence of Basic Human Behaviors (Influenced by Brain Architecture and Function), and Past Traumatic Events On Investor Behavior and Financial BiasCalvin YeohNo ratings yet
- The Efficient Market Hypothesis: A Critical Review of The LiteratureDocument17 pagesThe Efficient Market Hypothesis: A Critical Review of The LiteratureTuyết AhNo ratings yet
- Alternative Investments - A Primer For Investment ProfessionalsDocument183 pagesAlternative Investments - A Primer For Investment Professionalsmangeshvaidya100% (3)
- BMA 12e PPT Ch13 16 PDFDocument68 pagesBMA 12e PPT Ch13 16 PDFLuu ParrondoNo ratings yet
- Behavioral Finance An Impact of Investors Unpredictable Behavior On Stock MarketDocument5 pagesBehavioral Finance An Impact of Investors Unpredictable Behavior On Stock MarketBinayKPNo ratings yet
- Iim Ahmedabad Investment Decisions and Behavioural Finance 5 30 YrsDocument4 pagesIim Ahmedabad Investment Decisions and Behavioural Finance 5 30 Yrsbhavan123No ratings yet
- Correct Answers Are Shown inDocument14 pagesCorrect Answers Are Shown inAkshay Mathur0% (1)
- FTCP Seminar 5 Answers (6) XSXSXSXDocument5 pagesFTCP Seminar 5 Answers (6) XSXSXSXLewis FergusonNo ratings yet
- Behavioral Finance at The Next LevelDocument12 pagesBehavioral Finance at The Next LevelRamachandrareddy GNo ratings yet
- The Stock MarketDocument4 pagesThe Stock MarketBhumika BhardwajNo ratings yet
- MacareanaDocument1 pageMacareanaNivesh LallbahadoorNo ratings yet
- Untitled Section: 8 of 10 PointsDocument28 pagesUntitled Section: 8 of 10 PointsRuby JaneNo ratings yet
- Acco 400 Final NotesDocument53 pagesAcco 400 Final NotesMichael Di MonacoNo ratings yet
- Pyq Merge f9Document90 pagesPyq Merge f9Anonymous gdA3wqWcPNo ratings yet
- ch12 BaruDocument28 pagesch12 BaruIrvan Syafiq NurhabibieNo ratings yet
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldFrom EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldRating: 4.5 out of 5 stars4.5/5 (107)
- Generative AI: The Insights You Need from Harvard Business ReviewFrom EverandGenerative AI: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (2)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldFrom EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldRating: 4.5 out of 5 stars4.5/5 (55)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveFrom EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNo ratings yet
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewFrom EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewRating: 4.5 out of 5 stars4.5/5 (104)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkFrom EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkRating: 4 out of 5 stars4/5 (7)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessFrom EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNo ratings yet
- Artificial Intelligence: A Guide for Thinking HumansFrom EverandArtificial Intelligence: A Guide for Thinking HumansRating: 4.5 out of 5 stars4.5/5 (30)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesFrom EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesRating: 4.5 out of 5 stars4.5/5 (13)
- Midjourney Mastery - The Ultimate Handbook of PromptsFrom EverandMidjourney Mastery - The Ultimate Handbook of PromptsRating: 4.5 out of 5 stars4.5/5 (2)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindFrom EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNo ratings yet
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)From EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)No ratings yet
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.From EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Rating: 4 out of 5 stars4/5 (15)
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziFrom Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNo ratings yet
- AI Money Machine: Unlock the Secrets to Making Money Online with AIFrom EverandAI Money Machine: Unlock the Secrets to Making Money Online with AINo ratings yet
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceFrom EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceRating: 4.5 out of 5 stars4.5/5 (38)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsFrom EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNo ratings yet
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceFrom EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceRating: 4 out of 5 stars4/5 (2)
- 1200+ AI Prompts for Everyone.: Artificial Intelligence Prompt Library.From Everand1200+ AI Prompts for Everyone.: Artificial Intelligence Prompt Library.No ratings yet
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryFrom EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNo ratings yet
- 2084: Artificial Intelligence and the Future of HumanityFrom Everand2084: Artificial Intelligence and the Future of HumanityRating: 4 out of 5 stars4/5 (81)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)From EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Rating: 4 out of 5 stars4/5 (1)
- 100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesFrom Everand100+ Amazing AI Image Prompts: Expertly Crafted Midjourney AI Art Generation ExamplesNo ratings yet