You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5806)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1091)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (842)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (589)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (897)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (401)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Third Periodical Test in Prac Research 1Document2 pagesThird Periodical Test in Prac Research 1Ram Kuizon80% (5)
- Pipelines and Soil Mechanics 31 March 2020Document9 pagesPipelines and Soil Mechanics 31 March 2020George BabyNo ratings yet
- MSA - StatgraphicsDocument3 pagesMSA - Statgraphicstehky63No ratings yet
- Rula SheetDocument2 pagesRula Sheetjmmos207064No ratings yet
- Group 5 Final Research Papers 12 VoltaireDocument46 pagesGroup 5 Final Research Papers 12 VoltaireJaypee AsoyNo ratings yet
- Chapter 3 - DJDocument3 pagesChapter 3 - DJEunice GabrielNo ratings yet
- Lecture 2 Classification and Types of ResearchDocument22 pagesLecture 2 Classification and Types of ResearchBasari Odal100% (4)
- Permutations Worksheet AHILDocument2 pagesPermutations Worksheet AHILNeyha FarrukhNo ratings yet
- Truss and Cable ElementsDocument9 pagesTruss and Cable ElementsArnel KirkNo ratings yet
- Purpose of A Research Proposal-Mahi1Document5 pagesPurpose of A Research Proposal-Mahi1seret GideyNo ratings yet
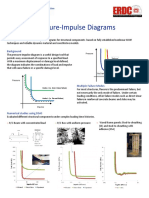
- Pressure Impulse DiagramsDocument1 pagePressure Impulse DiagramsPrasad GowriNo ratings yet
- Production of Acrylonitrile by Ammoxidation of PropyleneDocument33 pagesProduction of Acrylonitrile by Ammoxidation of PropyleneJ José B VelasquezNo ratings yet
- Quality Management For Drug DevelopmentDocument14 pagesQuality Management For Drug DevelopmentSai Santhosh ManepallyNo ratings yet
- DBT-LBC Program Fidelity Scale JR-19Document16 pagesDBT-LBC Program Fidelity Scale JR-19Ronnie Rengiffo100% (1)
- Al400 - s11066311 Assignment 3Document14 pagesAl400 - s11066311 Assignment 3Rinal PrasadNo ratings yet
- Penizula Citizen PerceptionDocument187 pagesPenizula Citizen PerceptionliyaNo ratings yet
- An Analysis of The Effect of Procurement ProcedureDocument12 pagesAn Analysis of The Effect of Procurement ProcedureImane SassaouiNo ratings yet
- Development of A Measure of Workplace DevianceDocument13 pagesDevelopment of A Measure of Workplace DevianceMarko PrpićNo ratings yet
- Key Performance Indicators (Kpis)Document71 pagesKey Performance Indicators (Kpis)Bayu MurtiNo ratings yet
- Family Case Study-AbstractDocument3 pagesFamily Case Study-AbstractKatherine 'Chingboo' Leonico LaudNo ratings yet
- Script TanglawanDocument6 pagesScript TanglawanMark Dennis AsuncionNo ratings yet
- Student Handbook For Pharmacy Practice Research John Bentley Full Chapter PDF ScribdDocument67 pagesStudent Handbook For Pharmacy Practice Research John Bentley Full Chapter PDF Scribdwesley.ruehle633100% (4)
- Quiz 2 Chap 2 AnswerDocument3 pagesQuiz 2 Chap 2 AnswerPhương NgaNo ratings yet
- Urban Archaeology Session 2 Online Archives Useful ResourcesDocument2 pagesUrban Archaeology Session 2 Online Archives Useful ResourcesNicole BealeNo ratings yet
- The Role of Teacher Leadership in Professional Learning Community PLC in International Baccalaureate IB Schools A Social Network ApproachDocument18 pagesThe Role of Teacher Leadership in Professional Learning Community PLC in International Baccalaureate IB Schools A Social Network ApproachHuiNo ratings yet
- 5 2Document2 pages5 2Prem RajNo ratings yet
- 4 Measure - Measurement System AnalysisDocument63 pages4 Measure - Measurement System AnalysisSudhagarNo ratings yet
- Research ProposalDocument36 pagesResearch ProposalValerie Faye Badajos100% (2)
- Stata Lecture2Document134 pagesStata Lecture2lukyindonesiaNo ratings yet
- Syn. FormatDocument3 pagesSyn. FormatadityatnnlsNo ratings yet