You might also like
- Dbms Cheat SheetDocument5 pagesDbms Cheat Sheetnoob100% (2)
- CLOUD COMPUTING OVERVIEWDocument23 pagesCLOUD COMPUTING OVERVIEWKartheeswari SaravananNo ratings yet
- DataBase SystemsDocument35 pagesDataBase Systemssubhasish_das007No ratings yet
- Group 3Document72 pagesGroup 3alex setegn100% (1)
- How To Test Banking Domain Applications: A Complete BFSI Testing GuideDocument52 pagesHow To Test Banking Domain Applications: A Complete BFSI Testing GuideMamatha K NNo ratings yet
- AI 2marks QuestionsDocument121 pagesAI 2marks Questionsgopitheprince100% (1)
- Predicting Personal Loan Approval Using Machine Learning HandbookDocument31 pagesPredicting Personal Loan Approval Using Machine Learning HandbookEzhilarasiNo ratings yet
- SOFTWARE ENGINEERING PROJECT DESCRIPTIONSDocument3 pagesSOFTWARE ENGINEERING PROJECT DESCRIPTIONSmigadNo ratings yet
- Client Server Architecture A Complete Guide - 2020 EditionFrom EverandClient Server Architecture A Complete Guide - 2020 EditionNo ratings yet
- SQL Server Interview QuestionsDocument14 pagesSQL Server Interview QuestionschandrasekarNo ratings yet
- 0 - Unit 7 DataBase DevelopmentDocument6 pages0 - Unit 7 DataBase DevelopmentMahalakshmiNo ratings yet
- Credit Card Management System RequirementsDocument9 pagesCredit Card Management System Requirementsauro arrow100% (1)
- Synopsis Online Health Insurance ManagementDocument20 pagesSynopsis Online Health Insurance ManagementRaj Bangalore50% (2)
- E-Banking Admin FRS v1.0Document39 pagesE-Banking Admin FRS v1.0Kiran Kumar67% (3)
- MS SQL Server Business IntelligenceDocument6 pagesMS SQL Server Business IntelligenceJulie RobertsNo ratings yet
- Banking System Database Design Group ProjectDocument16 pagesBanking System Database Design Group ProjectSrinivas Aditya100% (1)
- 7Document193 pages7Anonymous T0BjtfBNo ratings yet
- Citizen Card Management SystemDocument68 pagesCitizen Card Management SystemyogeswariNo ratings yet
- Student Management System SynopsisDocument6 pagesStudent Management System SynopsisRISHI JAISWALNo ratings yet
- Java For BCA (Hindi Notes)Document64 pagesJava For BCA (Hindi Notes)chirag up and downNo ratings yet
- Credit Card Management SystemDocument2 pagesCredit Card Management Systemprathikfrndz50% (2)
- Data Mining-Constraint Based Cluster AnalysisDocument4 pagesData Mining-Constraint Based Cluster AnalysisRaj Endran100% (1)
- ONLINE Pizza STOREDocument38 pagesONLINE Pizza STORETEjas VendeNo ratings yet
- Visa SRSDocument6 pagesVisa SRSKushal Kaur SardarNo ratings yet
- ATM ManagementDocument36 pagesATM ManagementRoman MathurNo ratings yet
- ATM Card OTP VerificationDocument7 pagesATM Card OTP VerificationMansoorSulaiman100% (1)
- Java Hall Management SystemDocument15 pagesJava Hall Management SystemShafaeit HossainNo ratings yet
- Online Movie Ticket Booking SystemDocument10 pagesOnline Movie Ticket Booking SystemSiddesh UbaleNo ratings yet
- Automatic Migration of Data To Nosql Datavases Useng Service Oriented ArchitectureDocument52 pagesAutomatic Migration of Data To Nosql Datavases Useng Service Oriented ArchitectureLuiz FerreiraNo ratings yet
- Creating Database: Managing Databases in MysqlDocument56 pagesCreating Database: Managing Databases in MysqlpavankalluriNo ratings yet
- Prudent Fraud Detection Using Machine LearningDocument2 pagesPrudent Fraud Detection Using Machine LearningTunnu SunnyNo ratings yet
- Prediction of Modernized Loan Approval System Based On Machine Learning ApproachDocument22 pagesPrediction of Modernized Loan Approval System Based On Machine Learning ApproachMandara ManjunathNo ratings yet
- E Property Project DocumentationDocument198 pagesE Property Project DocumentationMusakkhir Sayyed88% (8)
- Dbms ProjectDocument4 pagesDbms ProjectUsama NayyerNo ratings yet
- 2-1-Features of Cloud and Grid PlatformsDocument3 pages2-1-Features of Cloud and Grid PlatformsJathin DarsiNo ratings yet
- Software Requirement Specification For Online Shopping SystemDocument21 pagesSoftware Requirement Specification For Online Shopping Systemnoob gamingNo ratings yet
- Manage Company Visitors with PHP & MySQLDocument4 pagesManage Company Visitors with PHP & MySQLRDGAC CSDepartmentNo ratings yet
- Insurance Management System ProjectDocument5 pagesInsurance Management System ProjectKeerthi Vasan LNo ratings yet
- Multibanking Online Transaction Processing Using Data Transfer Security ModelDocument25 pagesMultibanking Online Transaction Processing Using Data Transfer Security ModelVinoth ChitraNo ratings yet
- What Is The Level of Granularity of A Fact TableDocument15 pagesWhat Is The Level of Granularity of A Fact TableSaurabh GuptaNo ratings yet
- Apartment Visitors SystemDocument21 pagesApartment Visitors SystemAkshayNo ratings yet
- SniffingDocument2 pagesSniffingSmita Patil-JagdaleNo ratings yet
- ATM ArchitectureDocument8 pagesATM ArchitectureShantha Jayakumar100% (1)
- Atm SystemDocument21 pagesAtm SystemJai Shroff50% (4)
- Database Design ConceptDocument4 pagesDatabase Design ConceptChiranSJ100% (1)
- Module No.2.0: Office Application Unit No.2.3: Database Application Element 2.3.1: Selecting DatabaseDocument16 pagesModule No.2.0: Office Application Unit No.2.3: Database Application Element 2.3.1: Selecting Databasehigombeye gwalemaNo ratings yet
- Project Presentation Report On Student Management SystemDocument21 pagesProject Presentation Report On Student Management Systemaman deeptiwariNo ratings yet
- TEXT BOOK:"Client/Server Survival Guide" Wiley INDIA Publication, 3 Edition, 2011. Prepared By: B.LoganathanDocument41 pagesTEXT BOOK:"Client/Server Survival Guide" Wiley INDIA Publication, 3 Edition, 2011. Prepared By: B.LoganathanrenumathavNo ratings yet
- Bcs - 051 Software Engineering (IGNOU) (Important Questions) (Previos Year Qestions)Document4 pagesBcs - 051 Software Engineering (IGNOU) (Important Questions) (Previos Year Qestions)viiiNo ratings yet
- MCS043Document21 pagesMCS043charychandanNo ratings yet
- BCA JAVA Student Management System Project - PDF Report With Source CodeDocument121 pagesBCA JAVA Student Management System Project - PDF Report With Source CodeTURS gamingNo ratings yet
- Online Course Register SystemDocument16 pagesOnline Course Register Systemsuriya extazeeNo ratings yet
- SE Case StudyDocument33 pagesSE Case StudyChirag SharmaNo ratings yet
- Detect Online Transaction Fraud using Python & BackloggingDocument3 pagesDetect Online Transaction Fraud using Python & BackloggingRajesh Kumar100% (3)
- Directory Management SystemDocument88 pagesDirectory Management SystemAjith MathewNo ratings yet
- Inventory Management System (Abstract)Document2 pagesInventory Management System (Abstract)Danesh HernandezNo ratings yet
- Visionplus Interview Questions: Sangiah - Blogspot.InDocument4 pagesVisionplus Interview Questions: Sangiah - Blogspot.Inswathi bommineniNo ratings yet
- iSeries-AS/400 MICR Printing Made EasyDocument11 pagesiSeries-AS/400 MICR Printing Made Easylsr400No ratings yet
- Detecting and Characterizing Extremist Reviewer Groups in Online Product ReviewsDocument11 pagesDetecting and Characterizing Extremist Reviewer Groups in Online Product ReviewsHEMALATHA SHANMUGAMNo ratings yet
- CommandsDocument9 pagesCommands11009105053No ratings yet
- Database Normalization and ConceptsDocument9 pagesDatabase Normalization and Conceptsbasualok@rediffmail.comNo ratings yet
- SQL SERVER 2005/2008 Performance Tuning For The Developer: Michelle GutzaitDocument112 pagesSQL SERVER 2005/2008 Performance Tuning For The Developer: Michelle Gutzaitsauravkgupta5077No ratings yet
- My DampDocument9 pagesMy DampDenis MishenkinNo ratings yet
- Real Time Analytics With SAP Hana - Sample ChapterDocument26 pagesReal Time Analytics With SAP Hana - Sample ChapterPackt PublishingNo ratings yet
- Introduction To MongoDB Course MongoDB UniversityDocument1 pageIntroduction To MongoDB Course MongoDB UniversityFlorin Razvan PrihotinNo ratings yet
- Topic 1 Part 2Document22 pagesTopic 1 Part 2Arif IskandarNo ratings yet
- Test Bank For Analytics Data Science and Artificial Intelligence 11th Ediiton ShardaDocument12 pagesTest Bank For Analytics Data Science and Artificial Intelligence 11th Ediiton ShardaCassandraDuncanmcytd100% (35)
- Using Oracle Autonomous Data Warehouse Dedicated Exadata InfrastructureDocument123 pagesUsing Oracle Autonomous Data Warehouse Dedicated Exadata InfrastructuremadhusribNo ratings yet
- Assignment - Data & File Structure Using CDocument7 pagesAssignment - Data & File Structure Using CMohit Aggarwal0% (1)
- Manage data warehouses and marts with conformed dimensionsDocument230 pagesManage data warehouses and marts with conformed dimensionsabraham_sse1594100% (1)
- Mongo MCQDocument13 pagesMongo MCQMayur PanchalNo ratings yet
- Mastering Mongodb 7.0: Fourth EditionDocument447 pagesMastering Mongodb 7.0: Fourth Editionfpm89470No ratings yet
- ETL Test CasesDocument14 pagesETL Test Casesnaveen.choragudi1122No ratings yet
- Glassdoor - Resume - CV - Pradeep Kumar Sheliveri - StandoutDocument2 pagesGlassdoor - Resume - CV - Pradeep Kumar Sheliveri - StandoutAnoo SadaNo ratings yet
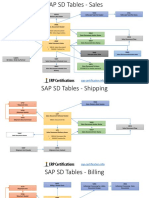
- SD TablesDocument3 pagesSD TablesRajeshNo ratings yet
- Emails WalletsDocument8 pagesEmails WalletsAbuela Abuelo100% (2)
- 10 DistributeddbmsDocument56 pages10 DistributeddbmsKrishna KumarNo ratings yet
- Concepts of Database Management Eighth EditionDocument41 pagesConcepts of Database Management Eighth EditionIsaac PavesichNo ratings yet
- APO Master DataDocument120 pagesAPO Master DataNeeraj Kumar100% (1)
- Moocs SQLDocument10 pagesMoocs SQLAlonso AzaldeguiNo ratings yet
- SSIS Workbook PDFDocument182 pagesSSIS Workbook PDFprasadNo ratings yet
- Perforce Helix CheatsheetDocument2 pagesPerforce Helix CheatsheetJohn SmithNo ratings yet
- Oracle Composite Indexes and Foreign Key ConstraintsDocument8 pagesOracle Composite Indexes and Foreign Key ConstraintskatikireddygNo ratings yet
- Data MapperDocument104 pagesData MapperSofieNo ratings yet
- Data MiningDocument84 pagesData Miningtulasinad123No ratings yet
- Intro To SEO Slide DeckDocument14 pagesIntro To SEO Slide Deckwavewa9150No ratings yet
- OLTP Vs OlapDocument2 pagesOLTP Vs OlapAnirudh SharmaNo ratings yet
- Data Analyst Roadmap Skills ResourcesDocument7 pagesData Analyst Roadmap Skills Resourcessai mauryaNo ratings yet
- Managing Temp Space in DatabaseDocument9 pagesManaging Temp Space in Databasesmacky3001No ratings yet