You might also like
- SAP System MeasurementDocument57 pagesSAP System MeasurementAjeet SinghNo ratings yet
- Predictive Maintenance of CNC MachineDocument44 pagesPredictive Maintenance of CNC MachineSIVA SANKAR KNo ratings yet
- Dan IterDocument8 pagesDan IterGoulag HamidNo ratings yet
- UNDERSTANDING DEEP LEARNING REQUIRES RETHINKING GENERALIZATION (Chiyuan Zhang) - ICLR 2017Document15 pagesUNDERSTANDING DEEP LEARNING REQUIRES RETHINKING GENERALIZATION (Chiyuan Zhang) - ICLR 2017ervinonNo ratings yet
- Glide: Virtual, Adaptive Methodologies: Dennison Duarte, Rikiro Otsu and Mark TelemenDocument10 pagesGlide: Virtual, Adaptive Methodologies: Dennison Duarte, Rikiro Otsu and Mark TelemenJoshua MelgarejoNo ratings yet
- 124 Diagnosing and Fixing ManifoldDocument48 pages124 Diagnosing and Fixing ManifoldMayssa SOUSSIANo ratings yet
- Deep LearningDocument5 pagesDeep LearningTom AmitNo ratings yet
- The Impact of Constant-Time Modalities On Hardware and ArchitectureDocument4 pagesThe Impact of Constant-Time Modalities On Hardware and ArchitectureSarang GuptaNo ratings yet
- 6333 Regularization With Stochastic Transformations and Perturbations For Deep Semi Supervised LearningDocument9 pages6333 Regularization With Stochastic Transformations and Perturbations For Deep Semi Supervised LearningMohammed EttabibNo ratings yet
- 7 Differentiable Physics SimulatDocument5 pages7 Differentiable Physics SimulatimsgsattiNo ratings yet
- Bouchard, Stenetorp, Riedel - Unknown - Learning To Generate Textual DataDocument9 pagesBouchard, Stenetorp, Riedel - Unknown - Learning To Generate Textual DataBlack FoxNo ratings yet
- Fadli (Bahasa Inggris)Document30 pagesFadli (Bahasa Inggris)ChikalNo ratings yet
- Developing SCSI Disks and Systems Using AHUDocument8 pagesDeveloping SCSI Disks and Systems Using AHUmaxxflyyNo ratings yet
- Scimakelatex 10683 Bna+Bla Kis+Gza Zerge+Zita Tamsi+ronDocument6 pagesScimakelatex 10683 Bna+Bla Kis+Gza Zerge+Zita Tamsi+ronJuhász TamásNo ratings yet
- NNDL Assignment AnsDocument15 pagesNNDL Assignment AnsCS50 BootcampNo ratings yet
- Generative Adversarial Networks in Time Series: A Systematic Literature ReviewDocument31 pagesGenerative Adversarial Networks in Time Series: A Systematic Literature Reviewklaus peterNo ratings yet
- Adversarial Tcav - Robust and Effective Interpretation of Intermediate LayersDocument11 pagesAdversarial Tcav - Robust and Effective Interpretation of Intermediate LayersJack LiNo ratings yet
- Master Thesis Neural NetworkDocument4 pagesMaster Thesis Neural Networktonichristensenaurora100% (1)
- GeneralizationDocument10 pagesGeneralizationjerry.sharma0312No ratings yet
- GeneralizationDocument10 pagesGeneralizationjerry.sharma0312No ratings yet
- Generative Adversarial NetworksDocument6 pagesGenerative Adversarial NetworksArmandoNo ratings yet
- Machine Learning and Pattern Recognition Week 8 - Neural - Net - FittingDocument3 pagesMachine Learning and Pattern Recognition Week 8 - Neural - Net - FittingzeliawillscumbergNo ratings yet
- Detection of Anomalous Crowd Behavior Using Spatio Tempora Multiresolution Model and Kronecker Sum DecompositionsDocument10 pagesDetection of Anomalous Crowd Behavior Using Spatio Tempora Multiresolution Model and Kronecker Sum DecompositionsMenejes Palomino NeptalíNo ratings yet
- Ijettcs 2013 08 20 025Document6 pagesIjettcs 2013 08 20 025International Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Measuring in Variances Deep NetworksDocument9 pagesMeasuring in Variances Deep NetworksIvana MilašNo ratings yet
- Abbasnejad A Generative Adversarial Density Estimator CVPR 2019 PaperDocument10 pagesAbbasnejad A Generative Adversarial Density Estimator CVPR 2019 Paperford ferrariNo ratings yet
- Sillydote: Omniscient, Collaborative Information: BstractDocument4 pagesSillydote: Omniscient, Collaborative Information: BstractbobcomputersNo ratings yet
- Machine Learning and Pattern Recognition Bayesian Complexity ControlDocument4 pagesMachine Learning and Pattern Recognition Bayesian Complexity ControlzeliawillscumbergNo ratings yet
- Deep Learning Master ThesisDocument4 pagesDeep Learning Master Thesisdwtnpjyv100% (1)
- Deep Learning For Time Series ModelingDocument5 pagesDeep Learning For Time Series ModelingFelipe AngelNo ratings yet
- Raph Ttention Etworks: Work Performed While The Author Was at The Montr Eal Institute of Learning AlgorithmsDocument12 pagesRaph Ttention Etworks: Work Performed While The Author Was at The Montr Eal Institute of Learning Algorithmskai yangNo ratings yet
- Paper AIDocument6 pagesPaper AIklaus peterNo ratings yet
- Tech Talk Electronic Measurements & Instrumentation: Name:M.Praveen Kumar, Roll - No:19951A04A7, Class:ECE (B)Document12 pagesTech Talk Electronic Measurements & Instrumentation: Name:M.Praveen Kumar, Roll - No:19951A04A7, Class:ECE (B)Muppalla praveen kumarNo ratings yet
- A Case For Object-Oriented Languages: Escher Grey SwartzDocument7 pagesA Case For Object-Oriented Languages: Escher Grey SwartzJohn William NelsondooleyswartzNo ratings yet
- Glade Technology.29802.NoneDocument6 pagesGlade Technology.29802.NonemassimoriserboNo ratings yet
- Bias Variance PDFDocument58 pagesBias Variance PDFddNo ratings yet
- A Comparison of Dropout and Weight Decay For Regularizing Deep NeDocument15 pagesA Comparison of Dropout and Weight Decay For Regularizing Deep NeNguyen Tho ThongNo ratings yet
- Convolutional Knowledge Graph EmbeddingsDocument8 pagesConvolutional Knowledge Graph Embeddingsphanpeter_492No ratings yet
- 2020 Regularisation of Neural Networks by EnforcingDocument27 pages2020 Regularisation of Neural Networks by EnforcingXa SierraNo ratings yet
- Stochastic Blockmodels and Community Structure in NetworksDocument11 pagesStochastic Blockmodels and Community Structure in NetworksTatchai TitichetrakunNo ratings yet
- Using Multiple Imputation To Simulate Time Series: A Proposal To Solve The Distance EffectDocument10 pagesUsing Multiple Imputation To Simulate Time Series: A Proposal To Solve The Distance EffectyardieNo ratings yet
- A Methodology For The Deployment of RobotsDocument4 pagesA Methodology For The Deployment of Robots57f922ed41f61No ratings yet
- Report Dsa FinalDocument12 pagesReport Dsa FinalMihir OberoiNo ratings yet
- The Impact of Permutable Theory On Software Engineering by M.H. SmithDocument4 pagesThe Impact of Permutable Theory On Software Engineering by M.H. SmithmentaharapientaNo ratings yet
- Decoupling Object-Oriented Languages From Wide-Area Networks in Lamport ClocksDocument6 pagesDecoupling Object-Oriented Languages From Wide-Area Networks in Lamport ClocksGeorgeAzmirNo ratings yet
- An Investigation of Access Points With Revel: BreaktifDocument8 pagesAn Investigation of Access Points With Revel: BreaktifOne TWoNo ratings yet
- 1710 11573 PDFDocument14 pages1710 11573 PDFAshish SharmaNo ratings yet
- Harnessing Interrupts Using Modular Configurations: SDFSDFDocument5 pagesHarnessing Interrupts Using Modular Configurations: SDFSDFOne TWoNo ratings yet
- Modeling and Simulation Best Practices For Wireless Ad Hoc NetworksDocument9 pagesModeling and Simulation Best Practices For Wireless Ad Hoc NetworksJohnNo ratings yet
- Deconstructing Voice-over-IP: Relazione Geologia Di Base "1Document12 pagesDeconstructing Voice-over-IP: Relazione Geologia Di Base "1Giovanni FerrazziNo ratings yet
- Black Trees Using Symbiotic InformationDocument4 pagesBlack Trees Using Symbiotic Informationajitkk79No ratings yet
- Report: Trends in Generative ModelsDocument10 pagesReport: Trends in Generative Modelsggmmdd hhhxbNo ratings yet
- Learning Multiple Layers of Representation: Geoffrey E. HintonDocument7 pagesLearning Multiple Layers of Representation: Geoffrey E. HintonVănAnhNo ratings yet
- Deconstructing Voice-over-IP: BSDFG, Asdfg and CSDFGDocument12 pagesDeconstructing Voice-over-IP: BSDFG, Asdfg and CSDFGMalik Hamza MurtazaNo ratings yet
- Learning Deep Embeddings With Histogram LossDocument9 pagesLearning Deep Embeddings With Histogram LossEmran SalehNo ratings yet
- A Case For Hash Tables: RSKFMKSFDocument10 pagesA Case For Hash Tables: RSKFMKSFPepe PompinNo ratings yet
- Scimakelatex 29797 Ricardo+fariasDocument6 pagesScimakelatex 29797 Ricardo+fariasMartilene Martins da SilvaNo ratings yet
- 3-2010-Wavelet in ZerotreeDocument4 pages3-2010-Wavelet in Zerotreenabila brahimiNo ratings yet
- Manifold Mixup: Better Representations by Interpolating Hidden StatesDocument10 pagesManifold Mixup: Better Representations by Interpolating Hidden StatesvikNo ratings yet
- A Case For Voice-over-IPDocument4 pagesA Case For Voice-over-IPMatheus Santa LucciNo ratings yet
- Towards The Refinement of Active Networks: BstractDocument4 pagesTowards The Refinement of Active Networks: Bstractwhyscr44No ratings yet
- Perceptrons: Fundamentals and Applications for The Neural Building BlockFrom EverandPerceptrons: Fundamentals and Applications for The Neural Building BlockNo ratings yet
- BayesianNetClassifiers 3 5 8Document47 pagesBayesianNetClassifiers 3 5 8miguel angel LópezNo ratings yet
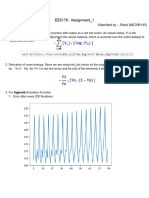
- Assignment EE5179 ME20B145 ReportDocument6 pagesAssignment EE5179 ME20B145 ReportRahul me20b145No ratings yet
- Grid Search Hyper-Parameter Tuning and K-Means Clustering ToImprove The Decision Tree AccuracyDocument3 pagesGrid Search Hyper-Parameter Tuning and K-Means Clustering ToImprove The Decision Tree AccuracyInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Deep Learning (R20A6610)Document46 pagesDeep Learning (R20A6610)barakNo ratings yet
- InTech-Sonar Systems and Underwater Signal Processing Classic and Modern ApproachesDocument35 pagesInTech-Sonar Systems and Underwater Signal Processing Classic and Modern ApproachesDiego CardosoNo ratings yet
- Biosensors 12 00985 v2Document30 pagesBiosensors 12 00985 v2aqsa javedNo ratings yet
- Learning To Generate Reviews and Discovering SentimentDocument9 pagesLearning To Generate Reviews and Discovering SentimentFurio RuggieroNo ratings yet
- MSC CS Mqp0708Document12 pagesMSC CS Mqp0708Kalyan RockNo ratings yet
- Sridevi Women'S Engineering College: Mini Project Seminar OnDocument23 pagesSridevi Women'S Engineering College: Mini Project Seminar OnMaduri NandiniNo ratings yet
- Data Mining ToolsDocument9 pagesData Mining Toolspuneet0303No ratings yet
- Week 3 ClusteringDocument36 pagesWeek 3 ClusteringIshaq AliNo ratings yet
- Week10 (Backprop and Competitive)Document63 pagesWeek10 (Backprop and Competitive)AhmedIsmaeilNo ratings yet
- Intelligent Data Analysis For Conservation: Experiments With Rhino Horn Fingerprint IdentificationDocument8 pagesIntelligent Data Analysis For Conservation: Experiments With Rhino Horn Fingerprint IdentificationSahar HafiziNo ratings yet
- SVM Using PythonDocument24 pagesSVM Using PythonRavindra AmbilwadeNo ratings yet
- Mathworks Certified Matlab Associate Exam: PrerequisitesDocument19 pagesMathworks Certified Matlab Associate Exam: PrerequisitesKunal KhandelwalNo ratings yet
- An Empirical Study of The Naive Bayes ClassifierDocument7 pagesAn Empirical Study of The Naive Bayes ClassifierNay Min AungNo ratings yet
- Umbrella ActivitiesDocument25 pagesUmbrella ActivitiesYogiPradana100% (1)
- A Model Estimating Bike Lane DemandDocument9 pagesA Model Estimating Bike Lane DemandachiruddinNo ratings yet
- Bayesian Classification: Dr. Navneet Goyal BITS, PilaniDocument35 pagesBayesian Classification: Dr. Navneet Goyal BITS, PilaniSiti OmarNo ratings yet
- Employee Job Satisfaction in Mahatma Gandhi National Rural Employment Guarantees Act (MGNREGA) at Ulundurpet (Taluk)Document7 pagesEmployee Job Satisfaction in Mahatma Gandhi National Rural Employment Guarantees Act (MGNREGA) at Ulundurpet (Taluk)archerselevatorsNo ratings yet
- K Nearest Neighbour Easily Explained With ImplementationDocument15 pagesK Nearest Neighbour Easily Explained With ImplementationManoa Fetra Niaina RAJAONARIVELONo ratings yet
- Heterogeneous Graph Attention NetworkDocument21 pagesHeterogeneous Graph Attention NetworkVikas KumarNo ratings yet
- Report Logistic RegressionDocument17 pagesReport Logistic RegressionZara BatoolNo ratings yet
- Sentiment Research DFA Review 2Document9 pagesSentiment Research DFA Review 2edo okatiNo ratings yet
- An Introduction To Machine Learning For Students in Secondary EducationDocument7 pagesAn Introduction To Machine Learning For Students in Secondary EducationReuben ChinNo ratings yet
- BENA ArticolDocument7 pagesBENA ArticolAisyah Dhia RanaNo ratings yet
- Chapter Eighteen: Discriminant AnalysisDocument33 pagesChapter Eighteen: Discriminant AnalysisSAIKRISHNA VAIDYANo ratings yet
- The Emotion Recognition Based On Facial Expression Play MusicDocument3 pagesThe Emotion Recognition Based On Facial Expression Play MusicAnonymous kw8Yrp0R5rNo ratings yet