You might also like
- A Comparative Analysis of Credit Card Fraud Detection Using Machine Learning TechniquesDocument2 pagesA Comparative Analysis of Credit Card Fraud Detection Using Machine Learning TechniquesKhairunnisa SafiNo ratings yet
- Stock Price Prediction Using Transfer Learning TechniquesDocument6 pagesStock Price Prediction Using Transfer Learning TechniquesIJRASETPublications100% (1)
- KPMGDocument2 pagesKPMGMhmoud Wafy100% (1)
- Forecasting of Stock Prices Using Multi Layer PerceptronDocument6 pagesForecasting of Stock Prices Using Multi Layer Perceptronijbui iir100% (1)
- CPE412 Pattern Recognition (Week 8)Document25 pagesCPE412 Pattern Recognition (Week 8)Basil Albattah100% (1)
- Taller Practica ChurnDocument6 pagesTaller Practica ChurnLuis Medina50% (2)
- Fake Profile Detection in Social Media Using NLP: About The ProjectDocument33 pagesFake Profile Detection in Social Media Using NLP: About The Projectrajesh mech100% (1)
- Machine Learning in Python Main Developments and TDocument44 pagesMachine Learning in Python Main Developments and Tmuhammad syaukani100% (1)
- Stock Market ForecastingDocument7 pagesStock Market ForecastingIJRASETPublications100% (1)
- Day 5 Supervised Technique-Decision Tree For Classification PDFDocument58 pagesDay 5 Supervised Technique-Decision Tree For Classification PDFamrita cse100% (1)
- Data Science PresentationDocument113 pagesData Science PresentationDHEEVIKA SURESH100% (2)
- Business Analytics-UNIt 1 ReDocument18 pagesBusiness Analytics-UNIt 1 Remayank.rockstarmayank.singh100% (1)
- Software Development Framework For Cardiac Disease Prediction Using Machine Learning ApplicationsDocument10 pagesSoftware Development Framework For Cardiac Disease Prediction Using Machine Learning ApplicationsKishore Kanna Ravi Kumar100% (1)
- Logistic Regression Model Study AssignmentDocument5 pagesLogistic Regression Model Study AssignmentNathan Mustafa100% (1)
- ML Project Shivani PandeyDocument49 pagesML Project Shivani PandeyShubhangi Pandey100% (1)
- Python Vs R in Data and Machine Learning PDFDocument6 pagesPython Vs R in Data and Machine Learning PDFjagadish100% (1)
- KPMG DataDocument3,723 pagesKPMG DataEdu Platform50% (2)
- Take Practical Decisions Using Data AnalyticsDocument16 pagesTake Practical Decisions Using Data AnalyticsSandhya Kuppala100% (1)
- Car Price Prediction Using Various AlgorithmsDocument19 pagesCar Price Prediction Using Various AlgorithmsNAVIN CHACKO100% (1)
- EFFIE 2002 Case StudiesDocument16 pagesEFFIE 2002 Case Studies9986212378100% (1)
- Student Booklet For Sep 2015 v6Document50 pagesStudent Booklet For Sep 2015 v6radebp100% (1)
- Business AnalyticsDocument8 pagesBusiness AnalyticsBala Ranganath100% (1)
- Linear Models in R: Interpreting Results & Common PitfallsDocument8 pagesLinear Models in R: Interpreting Results & Common PitfallsReaderRat100% (1)
- Introduction to Machine Learning in the Cloud with Python: Concepts and PracticesFrom EverandIntroduction to Machine Learning in the Cloud with Python: Concepts and PracticesNo ratings yet
- Lead Scoring Group Case Study PresentationDocument19 pagesLead Scoring Group Case Study PresentationSantosh Arakeri100% (1)
- Heart Disease Prediction Using Machine LearningDocument7 pagesHeart Disease Prediction Using Machine LearningIJRASETPublications100% (1)
- Car Price Prediction Using Machine LearningDocument15 pagesCar Price Prediction Using Machine LearningShania Jone100% (1)
- Heart Disease Prediction ModelDocument6 pagesHeart Disease Prediction ModelIJRASETPublications100% (1)
- Silver Oal College Of Engineering And Technology Basics of Feature EngineeringDocument33 pagesSilver Oal College Of Engineering And Technology Basics of Feature EngineeringKalash Shah100% (1)
- Week 1 Analytics in PracticeDocument12 pagesWeek 1 Analytics in Practicepalacpac jefferson100% (1)
- Credit Card Fraud DetectionDocument10 pagesCredit Card Fraud DetectionHarsha Gupta100% (1)
- January 1, 1983 1990 5 July 1994 1930 1960Document13 pagesJanuary 1, 1983 1990 5 July 1994 1930 1960MoonRider /MoonFanG.100% (1)
- Tableau MMMF PDFDocument11 pagesTableau MMMF PDFkiran100% (1)
- Lead Scoring Case Study PresentationDocument11 pagesLead Scoring Case Study PresentationDevanshi100% (1)
- Dev Answer KeyDocument17 pagesDev Answer Keyjayapriya kce100% (1)
- PytutorialDocument134 pagesPytutorialbernardinusheri100% (1)
- Breast Cancer ClassificationDocument16 pagesBreast Cancer ClassificationTester100% (1)
- ML Microsoft Course Overview: Machine Learning in ContextDocument53 pagesML Microsoft Course Overview: Machine Learning in Contextnandex777100% (1)
- Powerbivstableau 160912230240Document34 pagesPowerbivstableau 1609122302409phm8dpk8t100% (1)
- Decision TreeDocument14 pagesDecision TreeEsha Nawaz100% (1)
- Crime Prediction in Nigeria's Higer InstitutionsDocument13 pagesCrime Prediction in Nigeria's Higer InstitutionsBenjamin BalaNo ratings yet
- Python For You and Me: Release 0.3.alpha1Document143 pagesPython For You and Me: Release 0.3.alpha1Zafar Ansari100% (1)
- Data Analysis Nirvana: Excel 2013 Business Intelligence FeaturesDocument27 pagesData Analysis Nirvana: Excel 2013 Business Intelligence FeaturesOmar Jamanca Shuan100% (1)
- A Comparative Study of Machine Learning Algorithms For Gas Leak DetectionDocument9 pagesA Comparative Study of Machine Learning Algorithms For Gas Leak DetectionAkhil YadavNo ratings yet
- Wharton 2008Document133 pagesWharton 2008Nattaya Jaruvekin100% (1)
- Linear Regression (Check List)Document2 pagesLinear Regression (Check List)uday kiran100% (1)
- M&A Deal of ABC Inc. and XYZ Inc.: Insert Your Title HereDocument25 pagesM&A Deal of ABC Inc. and XYZ Inc.: Insert Your Title HereKaran Suri100% (1)
- Quest StatDocument2 pagesQuest Statsrpothul100% (1)
- Case Study 2Document12 pagesCase Study 2WiSeVirGo100% (1)
- QuantEconlectures Python3 PDFDocument1,125 pagesQuantEconlectures Python3 PDFKaik Wulck Bassanelli100% (1)
- Data Science Interview PreparationDocument113 pagesData Science Interview PreparationReva V100% (1)
- Chapter 1. IntroductionDocument39 pagesChapter 1. IntroductionNasrima D. Macaraya100% (1)
- Customer Wise: 5 Clusters of Supersales Store CustomersDocument34 pagesCustomer Wise: 5 Clusters of Supersales Store CustomersRishi TandonNo ratings yet
- ML3 - EvaluationDocument65 pagesML3 - Evaluationparam_email100% (1)
- Employee Attrition MiniblogsDocument15 pagesEmployee Attrition MiniblogsCodein100% (1)
- Machine Learning with Python: Design and Develop Machine Learning and Deep Learning Technique using real world code examplesFrom EverandMachine Learning with Python: Design and Develop Machine Learning and Deep Learning Technique using real world code examplesNo ratings yet
- Week 1 Introduction To MLDocument42 pagesWeek 1 Introduction To MLJaurel Kouam100% (1)
- Question 24Document11 pagesQuestion 24Ahmad WarrichNo ratings yet
- Question 40Document8 pagesQuestion 40Ahmad WarrichNo ratings yet
- Question 25Document2 pagesQuestion 25Ahmad WarrichNo ratings yet
- Question 23Document2 pagesQuestion 23Ahmad WarrichNo ratings yet
- Question 22Document4 pagesQuestion 22Ahmad WarrichNo ratings yet
- Credit Fraude PDFDocument6 pagesCredit Fraude PDFSergio NeiraNo ratings yet
- An Evaluation FrameworkDocument21 pagesAn Evaluation FrameworkAhmad WarrichNo ratings yet
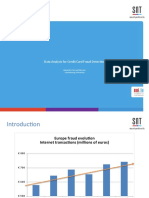
- Data Analysis For Credit Card Fraud DetectionDocument23 pagesData Analysis For Credit Card Fraud DetectionAhmad WarrichNo ratings yet
- Credit Card DetectionDocument9 pagesCredit Card DetectionAhmad WarrichNo ratings yet
- Detect Data LeakageDocument59 pagesDetect Data LeakageVardhan ThugNo ratings yet
- StarConferences Abstract ImaneLasri CreditCardFraudDetectionDocument2 pagesStarConferences Abstract ImaneLasri CreditCardFraudDetectionAhmad WarrichNo ratings yet
- Data Analysis For Credit Card Fraud DetectionDocument23 pagesData Analysis For Credit Card Fraud DetectionAhmad WarrichNo ratings yet
- Buck Converter Battery Charger Using The Z8F042A MCU: Reference DesignDocument27 pagesBuck Converter Battery Charger Using The Z8F042A MCU: Reference DesignRohit SainiNo ratings yet
- Controller PreviousDocument91 pagesController PreviouspatrickbreurNo ratings yet
- TECTA Operator Manual - VWR10218-898Document62 pagesTECTA Operator Manual - VWR10218-898mboudi thomasNo ratings yet
- RJ45 RJ45 u-USB u-USB: Universal Micro USB Cable (Samsung, LG, Nokia, ..)Document1 pageRJ45 RJ45 u-USB u-USB: Universal Micro USB Cable (Samsung, LG, Nokia, ..)Nicolae FeraruNo ratings yet
- Driver Deployment Utility v2.0.0.32468 Release NotesDocument4 pagesDriver Deployment Utility v2.0.0.32468 Release NotesDaniel NituNo ratings yet
- Lee Seyeon - 8th Grade U2 - DJ - ArchitectureDocument46 pagesLee Seyeon - 8th Grade U2 - DJ - Architectureapi-481593484No ratings yet
- Problem Definition: FPGA Implementation of D Flip Flop: Program CodeDocument4 pagesProblem Definition: FPGA Implementation of D Flip Flop: Program CodeDebayan BairagiNo ratings yet
- Project 1 v2Document10 pagesProject 1 v2api-538408600No ratings yet
- Sets PythonDocument20 pagesSets Pythonrbharati078No ratings yet
- Virtual conference on robotics, automationDocument3 pagesVirtual conference on robotics, automationAditya AnirudhNo ratings yet
- Methodology GrammarlyDocument2 pagesMethodology GrammarlyAidie MendozaNo ratings yet
- BUSI 2013 Unit 1-10 NotesDocument10 pagesBUSI 2013 Unit 1-10 NotesSyed TalhaNo ratings yet
- A Collection of Delphi/Lazarus Tips & Tricks: December 23, 2019Document34 pagesA Collection of Delphi/Lazarus Tips & Tricks: December 23, 2019cvetadonatiniNo ratings yet
- Fuji AF300 G11 Manual PDFDocument160 pagesFuji AF300 G11 Manual PDFMarceloVictorinoNo ratings yet
- Elementary Linear Algebra: Anton & Rorres, 9 EditionDocument67 pagesElementary Linear Algebra: Anton & Rorres, 9 EditionShilingi FidelNo ratings yet
- Practice Test 12.04Document5 pagesPractice Test 12.04Kiều LinhNo ratings yet
- Cryptography and Network Security: Seventh Edition by William StallingsDocument39 pagesCryptography and Network Security: Seventh Edition by William StallingsSawsan TawfiqNo ratings yet
- CS 101 Lecture 1 PDFDocument31 pagesCS 101 Lecture 1 PDFMohammad ArafatNo ratings yet
- Linux Lab 03 Mounting & ViDocument1 pageLinux Lab 03 Mounting & Vismile4ever54No ratings yet
- Learning Activity Sheet Java (LAS) - 3Document14 pagesLearning Activity Sheet Java (LAS) - 3lemuel sardualNo ratings yet
- Lumira SizingDocument27 pagesLumira Sizingvenkat143786No ratings yet
- DP-900 DumpsDocument84 pagesDP-900 DumpsParas Garg100% (4)
- Catalogo Precedent 3 A 10 TonsDocument240 pagesCatalogo Precedent 3 A 10 TonsJuan Carlos TarazonaNo ratings yet
- Week 1Document5 pagesWeek 1Syakila AurayyanNo ratings yet
- A Review of Lithium and Non-Lithium Based Solid State BatteriesDocument24 pagesA Review of Lithium and Non-Lithium Based Solid State BatteriesDécio FreitasNo ratings yet
- Teradata Stored ProceduresDocument2 pagesTeradata Stored ProcedureskdtftfjggjyhgNo ratings yet
- E315 Parts List Rev GDocument3 pagesE315 Parts List Rev GChateando Con FernandoNo ratings yet
- Safiya TechnicalDocument17 pagesSafiya TechnicalNarasimhulu MaddireddyNo ratings yet
- Building BlockDocument53 pagesBuilding BlockTejaswitha Ravula100% (1)
- Software Project Management Assignment 1Document5 pagesSoftware Project Management Assignment 1Kanwar ZainNo ratings yet