You might also like
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (120)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (895)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (73)
- System Verilog AssertionDocument18 pagesSystem Verilog AssertionMohit TopiwalaNo ratings yet
- Machine Learning and Deep Learning Methods For CybersecurityDocument17 pagesMachine Learning and Deep Learning Methods For CybersecurityalfonsoNo ratings yet
- Deep Learning in The Automotive Industry: Applications and ToolsDocument10 pagesDeep Learning in The Automotive Industry: Applications and ToolsJhonattan JavierNo ratings yet
- Nannan Zhang, Yang Liu, Liqun Zou, Hang Zhao, Wentong Dong, Hongying Zhou, Hongyan Guo, Miaofen HuangDocument4 pagesNannan Zhang, Yang Liu, Liqun Zou, Hang Zhao, Wentong Dong, Hongying Zhou, Hongyan Guo, Miaofen HuangJhonattan JavierNo ratings yet
- Defect Detection in Porcelain Industry Based On Deep Learning TechniquesDocument8 pagesDefect Detection in Porcelain Industry Based On Deep Learning TechniquesJhonattan JavierNo ratings yet
- Improving Deep Learning Performance Using Random Forest HTM Cortical Learning AlgorithmDocument6 pagesImproving Deep Learning Performance Using Random Forest HTM Cortical Learning AlgorithmJhonattan JavierNo ratings yet
- Realidad Aumentada Industria 4.0Document5 pagesRealidad Aumentada Industria 4.0Jhonattan JavierNo ratings yet
- DSP ExercisesDocument91 pagesDSP ExercisesRoumen GuhaNo ratings yet
- Fault Location in Distribution Systems With Distributed Generation Using Support Vector Machines and Smart MetersDocument6 pagesFault Location in Distribution Systems With Distributed Generation Using Support Vector Machines and Smart MetersJhonattan JavierNo ratings yet
- Optimization Techniques: Continuous - Discrete - Functional OptimizationDocument20 pagesOptimization Techniques: Continuous - Discrete - Functional OptimizationAAAAAANo ratings yet
- FEA Part1Document26 pagesFEA Part1Rajanarsimha SangamNo ratings yet
- Jurnal Overhead Ipsec 1Document17 pagesJurnal Overhead Ipsec 1Siti NurhawaNo ratings yet
- Midterm 1a SolutionsDocument9 pagesMidterm 1a Solutionskyle.krist13No ratings yet
- How To Train BertDocument18 pagesHow To Train BertRaviraj100% (1)
- Csi 5155 ML Project ReportDocument24 pagesCsi 5155 ML Project Report77Gorde Priyanka100% (1)
- Soft Computing.Document23 pagesSoft Computing.RadHika GaNdotraNo ratings yet
- AI SyllabusDocument4 pagesAI SyllabusVijayKumar LokanadamNo ratings yet
- OR - 6 - Queuing Theory - EMBA-2020-22Document40 pagesOR - 6 - Queuing Theory - EMBA-2020-22Saba MullaNo ratings yet
- Linear Methods For ClassificationDocument29 pagesLinear Methods For ClassificationelcebirNo ratings yet
- Worksheet 2.2Document7 pagesWorksheet 2.2Abhishek ChoudharyNo ratings yet
- Structure Chap-7 Review ExDocument7 pagesStructure Chap-7 Review Exabenezer g/kirstosNo ratings yet
- Selected Solutions, Griffiths QM, Chapter 1Document4 pagesSelected Solutions, Griffiths QM, Chapter 1Kenny StephensNo ratings yet
- Theory OF Wavelets: What Is A Wavelet?Document23 pagesTheory OF Wavelets: What Is A Wavelet?milindgoswamiNo ratings yet
- A Fuzzy Logic Temperature Controller For Preterm NeonateDocument16 pagesA Fuzzy Logic Temperature Controller For Preterm Neonatebudi_umm100% (1)
- Fermi Dirac Distribution Function PDFDocument2 pagesFermi Dirac Distribution Function PDFScott50% (2)
- Amm 2010 N5Document97 pagesAmm 2010 N51110004No ratings yet
- Stack Form 7.2Document11 pagesStack Form 7.2Sathish KumarNo ratings yet
- End-Term Exam - Quantitative Techniques IIDocument3 pagesEnd-Term Exam - Quantitative Techniques IIAshish TiwariNo ratings yet
- A Few Notes On Finite Element MethodDocument3 pagesA Few Notes On Finite Element MethodSnehasish BhattacharjeeNo ratings yet
- 202 2014 1 BDocument11 pages202 2014 1 BFreePDFs100% (6)
- Data Structures Question Bank MGU semIVDocument5 pagesData Structures Question Bank MGU semIVLakshmi VsNo ratings yet
- Lagrange Multipliers and Optimization ProblemsDocument3 pagesLagrange Multipliers and Optimization Problemsjuanagallardo01No ratings yet
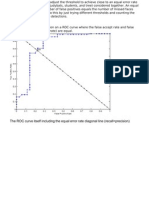
- The ROC Curve Itself Including The Equal Error Rate Diagonal Line (Recall Precision)Document3 pagesThe ROC Curve Itself Including The Equal Error Rate Diagonal Line (Recall Precision)OndelettaNo ratings yet
- Computational Techniques in Civil EngineeringDocument30 pagesComputational Techniques in Civil EngineeringGaurav Devkota100% (3)
- Question Bank - DC 6501Document10 pagesQuestion Bank - DC 6501karthikamageshNo ratings yet
- 10 Trees (SF)Document72 pages10 Trees (SF)trung phanNo ratings yet
- Machine Learning Based Car Price Prediction SystemDocument32 pagesMachine Learning Based Car Price Prediction Systemmovie CLUBNo ratings yet
- Tutorial III Root Locus DesignDocument25 pagesTutorial III Root Locus Designapi-3856083100% (3)