You might also like
- Apache Hadoop Book Report: HDFS Architecture and WorkingDocument45 pagesApache Hadoop Book Report: HDFS Architecture and WorkingHarish RNo ratings yet
- The Google File SystemDocument29 pagesThe Google File SystemhEho44744No ratings yet
- Lecture 2 - IO ManagementDocument196 pagesLecture 2 - IO ManagementHuy NguyenNo ratings yet
- Database Applications (15-415) DBMS Internals Part I LectureDocument41 pagesDatabase Applications (15-415) DBMS Internals Part I LectureRamakrishna YellapragadaNo ratings yet
- Storage Solutions For Bioinformatics: Li YanDocument30 pagesStorage Solutions For Bioinformatics: Li YanLamberto RosarioNo ratings yet
- Distributed File SystemDocument43 pagesDistributed File SystemDefendersNo ratings yet
- Cache Memory ADocument62 pagesCache Memory ARamiz KrasniqiNo ratings yet
- Gfs 2Document27 pagesGfs 2Towsif SalauddinNo ratings yet
- 15 Storage ManagerDocument5 pages15 Storage ManagerAnuj ZalaNo ratings yet
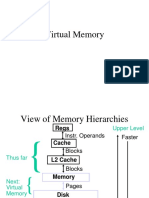
- Virtual Memory: View of Memory Hierarchies and Address TranslationDocument23 pagesVirtual Memory: View of Memory Hierarchies and Address Translationshailendra tripathiNo ratings yet
- UntitledDocument21 pagesUntitledSupriti VatsNo ratings yet
- Memory CacheDocument18 pagesMemory CacheFunsuk VangduNo ratings yet
- File Systems: Implementation: Bilkent University Department of Computer Engineering CS342 Operating SystemsDocument107 pagesFile Systems: Implementation: Bilkent University Department of Computer Engineering CS342 Operating SystemsSoundaryaNo ratings yet
- File Systems: Fundamentals: FilesDocument14 pagesFile Systems: Fundamentals: FilesIvanPamiđNo ratings yet
- Memory HierarchyDocument47 pagesMemory Hierarchypranali suryawanshi100% (1)
- Storage Management - Lecture 8 - Introduction To Databases (1007156ANR)Document49 pagesStorage Management - Lecture 8 - Introduction To Databases (1007156ANR)Beat SignerNo ratings yet
- Map-Reduce model addresses challenges of large-scale data mining on commodity clustersDocument18 pagesMap-Reduce model addresses challenges of large-scale data mining on commodity clusters23522020 Danendra Athallariq Harya PNo ratings yet
- Layers of A DBMS: Query Optimization Query Processor QueryDocument15 pagesLayers of A DBMS: Query Optimization Query Processor QueryAthar Abd AlmonemNo ratings yet
- Key goal of distributed file systemsDocument26 pagesKey goal of distributed file systemsBibat NdaNo ratings yet
- Distributed File SystemsDocument50 pagesDistributed File Systemsrid9No ratings yet
- Mass-Storage StructureDocument25 pagesMass-Storage StructureAnsh SinghNo ratings yet
- Distributed File Systems: DefinitionsDocument17 pagesDistributed File Systems: DefinitionsNonny ElewekeNo ratings yet
- Hadoop: Fasilkom/Pusilkom UI (Credit: Samuel Louvan)Document44 pagesHadoop: Fasilkom/Pusilkom UI (Credit: Samuel Louvan)Johan Rizky AdityaNo ratings yet
- HDFS SlidesDocument26 pagesHDFS SlidesAditya SharmaNo ratings yet
- Chapter 3 P1Document57 pagesChapter 3 P1Phạm Tiến AnhNo ratings yet
- DIsk BFRDocument26 pagesDIsk BFRArnaldo CanelasNo ratings yet
- Database Chapter Outline and File StructuresDocument13 pagesDatabase Chapter Outline and File StructuresShahana Enjoying LyfNo ratings yet
- Understanding Cache MemoryDocument20 pagesUnderstanding Cache MemoryAbdur RehmanNo ratings yet
- 03-1 File SystemsDocument9 pages03-1 File SystemsTrần Tuấn PhongNo ratings yet
- CH06 COA9eDocument48 pagesCH06 COA9eHuniya ErumNo ratings yet
- Rapid Application Development and Short-Time To The Market Low Latency Scalability High Availability Consistent View of The DataDocument21 pagesRapid Application Development and Short-Time To The Market Low Latency Scalability High Availability Consistent View of The Datashabir AhmadNo ratings yet
- ZFS: The Last Word in File SystemsDocument29 pagesZFS: The Last Word in File SystemsdertypNo ratings yet
- DFSNov 1Document36 pagesDFSNov 1Taha KarimNo ratings yet
- BDS Session 5Document57 pagesBDS Session 5R KrishNo ratings yet
- DSECL ZG 522: Big Data Systems: Session 6: Hadoop Architecture and FilesystemDocument56 pagesDSECL ZG 522: Big Data Systems: Session 6: Hadoop Architecture and FilesystemSwati BhagavatulaNo ratings yet
- Database 2 NotesDocument42 pagesDatabase 2 NotesabdhatemshNo ratings yet
- Enterprise Application Performance: Distributed CachingDocument29 pagesEnterprise Application Performance: Distributed CachingedymaradonaNo ratings yet
- Distributed File SystemsDocument46 pagesDistributed File SystemsFrank OyugiNo ratings yet
- Iseries Memory TuningDocument81 pagesIseries Memory Tuningsparvez100% (1)
- CS 5600 File SystemsDocument108 pagesCS 5600 File SystemsshoaibbhattiNo ratings yet
- Cache MemoryDocument21 pagesCache MemorySahib ShahabNo ratings yet
- Unit 2 PDFDocument22 pagesUnit 2 PDFvinodkharNo ratings yet
- Thegooglefilesystem Lecturebyromainjacotin 141001154546 Phpapp02Document52 pagesThegooglefilesystem Lecturebyromainjacotin 141001154546 Phpapp02Subhrajit BhowmikNo ratings yet
- Secondary Storage Devices (1) :: Magnetic DisksDocument56 pagesSecondary Storage Devices (1) :: Magnetic DisksSamahir AlkleefaNo ratings yet
- CS 3853 Computer Architecture - Memory HierarchyDocument37 pagesCS 3853 Computer Architecture - Memory HierarchyJothi RamasamyNo ratings yet
- Filesystems 2Document100 pagesFilesystems 2Saitcan baskolNo ratings yet
- A Review On GOOGLE File SystemDocument4 pagesA Review On GOOGLE File SystemPankaj GuptaNo ratings yet
- Managing Database Storage with Disks and RAIDDocument47 pagesManaging Database Storage with Disks and RAIDGopi BalaNo ratings yet
- Gestión de Almacenamiento: Facultad de Ciencias de La IngenieríaDocument43 pagesGestión de Almacenamiento: Facultad de Ciencias de La IngenieríaLuisToapantaNo ratings yet
- Unit 2Document22 pagesUnit 2Abhay DabhadeNo ratings yet
- Unit 5 1 Cache Performance V 2Document29 pagesUnit 5 1 Cache Performance V 2LekshmiNo ratings yet
- BigData Lecture4 HDFSDocument33 pagesBigData Lecture4 HDFSMubarak BegumNo ratings yet
- Module One - Part I - Memory IntroDocument20 pagesModule One - Part I - Memory Intronirosha vijayNo ratings yet
- Mining Massive Datasets Using MapReduce FrameworkDocument11 pagesMining Massive Datasets Using MapReduce FrameworkoscarmyoNo ratings yet
- The Hadoop Distributed File SystemDocument44 pagesThe Hadoop Distributed File SystemSaravanaRaajaaNo ratings yet
- Optimize Storage Access with File OrganizationDocument50 pagesOptimize Storage Access with File OrganizationmutayebNo ratings yet
- Viden Io Data Analytics Lecture10 Introduction To HdfsDocument28 pagesViden Io Data Analytics Lecture10 Introduction To HdfsRam ChanduNo ratings yet
- Operating Systems Io SystemsDocument25 pagesOperating Systems Io Systemskimchen edenelleNo ratings yet
- Ch10-Mass Storage StructureDocument22 pagesCh10-Mass Storage Structure11B04 Guruprasad. VNo ratings yet
- 01 BigDataDesignDocument38 pages01 BigDataDesignRoberto MartinezNo ratings yet
- Git TutorialDocument35 pagesGit TutorialRoberto Martinez100% (1)
- Introduction Hadoop Ecosystem Hdfs I SlidesDocument12 pagesIntroduction Hadoop Ecosystem Hdfs I SlidesRoberto MartinezNo ratings yet
- Setting-up HDFS ClusterDocument3 pagesSetting-up HDFS ClusterRoberto MartinezNo ratings yet
- ETL Tester Resume TNDocument9 pagesETL Tester Resume TNBharathNo ratings yet
- Hotel Management System: A Project Report Submitted in Partial Fulfillment of The RequirementsDocument41 pagesHotel Management System: A Project Report Submitted in Partial Fulfillment of The RequirementsDibyasha DasNo ratings yet
- SQL Data Definition: Database Systems Lecture 5 Natasha AlechinaDocument26 pagesSQL Data Definition: Database Systems Lecture 5 Natasha AlechinaRana GaballahNo ratings yet
- Full Stack Ruby On RailsDocument4 pagesFull Stack Ruby On RailsbrookNo ratings yet
- SQL SERVER - Automatic Seeding of Availability Database SQLAGDB' in Availability Group AG' Failed With A Transient ErrorDocument2 pagesSQL SERVER - Automatic Seeding of Availability Database SQLAGDB' in Availability Group AG' Failed With A Transient Errormessage2tejaNo ratings yet
- Chapter 2 Semi-Structured Data and XMLDocument27 pagesChapter 2 Semi-Structured Data and XMLabrehamNo ratings yet
- Three sources for alerts from storage servers in an X5 Database MachineDocument40 pagesThree sources for alerts from storage servers in an X5 Database MachineluatgdNo ratings yet
- Platform Developer I Webinar (Certification Week)Document60 pagesPlatform Developer I Webinar (Certification Week)lear foreverNo ratings yet
- 9 SQL ORDER BY ClauseDocument2 pages9 SQL ORDER BY Clauseপ্রমিত সরকারNo ratings yet
- How To Create An Oracle XML ReportDocument9 pagesHow To Create An Oracle XML ReportthierrykamsNo ratings yet
- ISOIEC 11179-1 Specification and Standardization of Data ElementsDocument42 pagesISOIEC 11179-1 Specification and Standardization of Data Elementsanwar setyawanNo ratings yet
- SQL DML and DDL Commands ExplainedDocument11 pagesSQL DML and DDL Commands ExplainedkazsakuraNo ratings yet
- Snowflake Snowpro Exam CheatsheetDocument7 pagesSnowflake Snowpro Exam CheatsheetSridhar Plv83% (12)
- SQL Chapter 3 IntroductionDocument64 pagesSQL Chapter 3 IntroductionHafiz Al Asad ManikNo ratings yet
- A-13 Must Have Shell Scripts To Automate Routine Tasks 1710736606Document32 pagesA-13 Must Have Shell Scripts To Automate Routine Tasks 1710736606bolisettyvaasNo ratings yet
- DMDW 2nd ModuleDocument29 pagesDMDW 2nd ModuleKavya GowdaNo ratings yet
- 18Cs53: Database Management Systems: Introduction To Transaction Processing Concepts and TheoryDocument37 pages18Cs53: Database Management Systems: Introduction To Transaction Processing Concepts and TheoryChandan SubramanyaNo ratings yet
- Exercise 9 - Room Database - JavaDocument15 pagesExercise 9 - Room Database - JavaLê Thị Đan LiênNo ratings yet
- Rapid Clone Method for Duplicating Oracle ApplicationsDocument5 pagesRapid Clone Method for Duplicating Oracle ApplicationsVijay ParuchuriNo ratings yet
- Computer XIIDocument303 pagesComputer XIIbhattaraikushal05No ratings yet
- Csa V12.75 PDFDocument18 pagesCsa V12.75 PDFranjithgottimukkala100% (1)
- Unit V - Web and Text MiningDocument35 pagesUnit V - Web and Text Miningswetha sastryNo ratings yet
- How To Build A Simple REST API in PHPDocument11 pagesHow To Build A Simple REST API in PHPGabrielNo ratings yet
- CheatSheet Symfony2 - ConsoleDocument2 pagesCheatSheet Symfony2 - ConsoleMarcelo Strappini100% (1)
- 12c Data Guard Switchover Best Practices Using SQLPLUSDocument8 pages12c Data Guard Switchover Best Practices Using SQLPLUSDaila Diana MoralesNo ratings yet
- IBM BI Tookit Datastage V1 0Document141 pagesIBM BI Tookit Datastage V1 0ukumar_657611No ratings yet
- Wincc ScriptsDocument16 pagesWincc ScriptsntrimurthuluNo ratings yet
- C3.Ai A New Technology StackDocument22 pagesC3.Ai A New Technology StackPrakhar DoorwarNo ratings yet
- 18CST41 - DBMS Cat 1 Answer KeyDocument12 pages18CST41 - DBMS Cat 1 Answer Key20CSR064 Natchattira T SNo ratings yet
- Using Time Model Views: Practice 2Document8 pagesUsing Time Model Views: Practice 2Abderahman MohamedNo ratings yet