You might also like
- Improve English Confidence QuestionnaireDocument4 pagesImprove English Confidence QuestionnaireIrina PădureNo ratings yet
- 1 s2.0 S0957417423023151 MainDocument17 pages1 s2.0 S0957417423023151 MainBaba AliNo ratings yet
- MS - Worthy of It All - Key of A & GDocument6 pagesMS - Worthy of It All - Key of A & GDianne HorarioNo ratings yet
- Plural Nouns WorksheetsDocument6 pagesPlural Nouns Worksheetsgeek scholarNo ratings yet
- Group 09Document3 pagesGroup 09Bùi Nguyên HoàngNo ratings yet
- 2017 - Unsupervised Neural Machine Translation PDFDocument11 pages2017 - Unsupervised Neural Machine Translation PDFyounge994No ratings yet
- Paper 2Document11 pagesPaper 2PIPALIYA NISARGNo ratings yet
- Character-Aware Neural Language ModelsDocument9 pagesCharacter-Aware Neural Language ModelsTewodros AmbasajerNo ratings yet
- Direct Speech-To-Speech Translation With A Sequence-To-Sequence ModelDocument5 pagesDirect Speech-To-Speech Translation With A Sequence-To-Sequence ModelLjubisa RaimovicNo ratings yet
- Character-Based Pivot Translation For Under-Resourced Languages and DomainsDocument11 pagesCharacter-Based Pivot Translation For Under-Resourced Languages and DomainsRaedmemphisNo ratings yet
- Seminar NotesDocument7 pagesSeminar NotesPooja VinodNo ratings yet
- Dynamic Mixtures of Contextual Experts For Language ModelingDocument11 pagesDynamic Mixtures of Contextual Experts For Language ModelingAnonymous IK307WzNo ratings yet
- SSICT-2023 Paper 5Document4 pagesSSICT-2023 Paper 5Bùi Nguyên HoàngNo ratings yet
- Toward Multilingual Neural Machine Translation With Universal Encoder and DecoderDocument10 pagesToward Multilingual Neural Machine Translation With Universal Encoder and Decoderspandan guntiNo ratings yet
- Cross-Lingual, Multi-Speaker Text-To-Speech Synthesis Using Neural Speaker EmbeddingDocument5 pagesCross-Lingual, Multi-Speaker Text-To-Speech Synthesis Using Neural Speaker Embeddingabaynesh mogesNo ratings yet
- Spoken Language Parsing Using Phrase-Level Grammars and Trainable ClassifiersDocument8 pagesSpoken Language Parsing Using Phrase-Level Grammars and Trainable ClassifiersnombreNo ratings yet
- Improving Neural Machine Translation Models With Monolingual DataDocument11 pagesImproving Neural Machine Translation Models With Monolingual DataYgana AnyNo ratings yet
- Transformer 1806.06957Document12 pagesTransformer 1806.06957Aparajita AggarwalNo ratings yet
- Cross-Modal Language Generation Using Pivot Stabilization For Web-Scale Language CoverageDocument11 pagesCross-Modal Language Generation Using Pivot Stabilization For Web-Scale Language CoverageHarishNandanNo ratings yet
- Pre-Trained Multilingual Sequence-to-Sequence ModelsDocument10 pagesPre-Trained Multilingual Sequence-to-Sequence ModelsAsim OthmanNo ratings yet
- NICT ATR Chinese-Japanese-English Speech-To-Speech Translation SystemDocument5 pagesNICT ATR Chinese-Japanese-English Speech-To-Speech Translation SystemFikadu MengistuNo ratings yet
- Neural Codec Language Models Are Zero-Shot Text To Speech SynthesizersDocument16 pagesNeural Codec Language Models Are Zero-Shot Text To Speech SynthesizersSophia AyllaNo ratings yet
- Sequence-to-Sequence Models Can Directly Transcribe Foreign SpeechDocument5 pagesSequence-to-Sequence Models Can Directly Transcribe Foreign SpeechAnonymous HUY0yRexYfNo ratings yet
- Information Extraction From Free-Form CV DocumentsDocument18 pagesInformation Extraction From Free-Form CV DocumentsGhassen HedhiliNo ratings yet
- Any-Language Frame-Semantic ParsingDocument5 pagesAny-Language Frame-Semantic ParsingJames CheeNo ratings yet
- RadmmmDocument5 pagesRadmmmkyeonjNo ratings yet
- Unsupervised Cross-Lingual Representation Learning For Speech RecognitionDocument11 pagesUnsupervised Cross-Lingual Representation Learning For Speech RecognitionCraig BakerNo ratings yet
- Yourtts: Towards Zero-Shot Multi-Speaker Tts and Zero-Shot Voice Conversion For EveryoneDocument8 pagesYourtts: Towards Zero-Shot Multi-Speaker Tts and Zero-Shot Voice Conversion For EveryoneJefferson Quispe PinaresNo ratings yet
- How Good Is Your Tokenizer? On The Monolingual Performance of Multilingual Language ModelsDocument28 pagesHow Good Is Your Tokenizer? On The Monolingual Performance of Multilingual Language ModelsMarcela MackováNo ratings yet
- Zero ShotDocument11 pagesZero ShotallfanaccNo ratings yet
- mt5 A Massively Multilingual Pre Trained Text To Text 9iojxtx56wDocument16 pagesmt5 A Massively Multilingual Pre Trained Text To Text 9iojxtx56wAbhishek JunghareNo ratings yet
- emnlp2019-D19-1168-Hierarchical Modeling of Global Context For Document-Level Neural Machine TranslationDocument10 pagesemnlp2019-D19-1168-Hierarchical Modeling of Global Context For Document-Level Neural Machine TranslationDeyi XiongNo ratings yet
- Contrastive Learning For Universal Zero-Shot NLI With Cross-Lingual Sentence EmbeddingsDocument14 pagesContrastive Learning For Universal Zero-Shot NLI With Cross-Lingual Sentence EmbeddingsMd. KowsherNo ratings yet
- Paper 3 PDFDocument8 pagesPaper 3 PDFivinayakNo ratings yet
- An Analysis of Neural Language Modeling at Multiple Scales: Melis Et Al. 2018Document10 pagesAn Analysis of Neural Language Modeling at Multiple Scales: Melis Et Al. 2018Juan ZarateNo ratings yet
- Gupta Et Al 2019 - Character-Based NMT With TransformerDocument16 pagesGupta Et Al 2019 - Character-Based NMT With TransformermccccccNo ratings yet
- Unit-Based Speech-to-Speech Translation Without Parallel DataDocument12 pagesUnit-Based Speech-to-Speech Translation Without Parallel DataLaurent BesacierNo ratings yet
- Predicting Target Language CCG Supertags Improves Neural Machine TranslationDocument12 pagesPredicting Target Language CCG Supertags Improves Neural Machine TranslationGalina AlexeevaNo ratings yet
- Challenges in NMT - 1907.05019Document27 pagesChallenges in NMT - 1907.05019Aparajita AggarwalNo ratings yet
- Google's Multilingual Neural Machine Translation System: Enabling Zero-Shot TranslationDocument17 pagesGoogle's Multilingual Neural Machine Translation System: Enabling Zero-Shot TranslationAdewole AkorexNo ratings yet
- 2021 Acl-Long 453Document13 pages2021 Acl-Long 453bosheng dingNo ratings yet
- 2022 Naacl-Srw 18Document7 pages2022 Naacl-Srw 18Vo Nhu YNo ratings yet
- Acoustic Word Embeddings MDPIDocument9 pagesAcoustic Word Embeddings MDPIAlfredo EsquivelJNo ratings yet
- Lexicon-Free Conversational Speech Recognition With Neural NetworksDocument10 pagesLexicon-Free Conversational Speech Recognition With Neural NetworksNah Mate-pleaseNo ratings yet
- 1378 7760 1 PBDocument6 pages1378 7760 1 PBРома КравчукNo ratings yet
- 2023 Acl-Long 66Document16 pages2023 Acl-Long 66会爆炸的小米NoteNo ratings yet
- Linguistic Input Features Improve Neural Machine TranslationDocument9 pagesLinguistic Input Features Improve Neural Machine Translation22080359No ratings yet
- RohitKundu DisfluencyCorrection SurveyPaperDocument10 pagesRohitKundu DisfluencyCorrection SurveyPaperIt's MeNo ratings yet
- Multi-Task Learning For Multiple Language TranslationDocument10 pagesMulti-Task Learning For Multiple Language TranslationTimNo ratings yet
- CSL PublisedDocument17 pagesCSL PublisedMah NoorNo ratings yet
- BASE TTS: Lessons From Building A Billion-Parameter Text-to-Speech Model On 100K Hours of Data (2402.08093)Document27 pagesBASE TTS: Lessons From Building A Billion-Parameter Text-to-Speech Model On 100K Hours of Data (2402.08093)JohnNo ratings yet
- How multilingual is Multilingual BERTDocument6 pagesHow multilingual is Multilingual BERTkingjames23No ratings yet
- Concatenative ProgrammingDocument6 pagesConcatenative ProgrammingmartincarpenterNo ratings yet
- Massively Multilingual Transfer for NERDocument14 pagesMassively Multilingual Transfer for NERMehari YohannesNo ratings yet
- TemplateDocument5 pagesTemplateLaurent BesacierNo ratings yet
- Sign Language Transformers: Joint End-To-End Sign Language Recognition and TranslationDocument11 pagesSign Language Transformers: Joint End-To-End Sign Language Recognition and TranslationGoku ultra instinctNo ratings yet
- Universal Sentence Encoder for Transfer LearningDocument7 pagesUniversal Sentence Encoder for Transfer Learningviterbi kkkNo ratings yet
- NLP-Cube - End-To-End Raw Text Processing With Neural NetworksDocument9 pagesNLP-Cube - End-To-End Raw Text Processing With Neural NetworksLeonNo ratings yet
- Dual Monolingual Cross-Entropy-Delta Filtering of Noisy Parallel DataDocument7 pagesDual Monolingual Cross-Entropy-Delta Filtering of Noisy Parallel DataChristophe ServanNo ratings yet
- Tagged Back-Translation: Isaac Caswell, Ciprian Chelba, David Grangier Google ResearchDocument11 pagesTagged Back-Translation: Isaac Caswell, Ciprian Chelba, David Grangier Google ResearchYgana AnyNo ratings yet
- Sequence Labelling Using Stochastic Final State Transducers (SFSTS)Document5 pagesSequence Labelling Using Stochastic Final State Transducers (SFSTS)Federico MarinelliNo ratings yet
- Africa From The OAU To The African UnionDocument17 pagesAfrica From The OAU To The African UniongorditoNo ratings yet
- Role of Eacj in The Eac Cu-CmDocument17 pagesRole of Eacj in The Eac Cu-CmgorditoNo ratings yet
- Ecb Spacereport202012 bb2038bbb6 enDocument148 pagesEcb Spacereport202012 bb2038bbb6 engorditoNo ratings yet
- EAC Integration - Enabling Peace and Security ArchitectureDocument18 pagesEAC Integration - Enabling Peace and Security ArchitectureMåurå MogeniNo ratings yet
- SGN 4 37 86 Protocol To Operationalize The Extended Jurisdiction of The East African Court of Justice 2013Document5 pagesSGN 4 37 86 Protocol To Operationalize The Extended Jurisdiction of The East African Court of Justice 2013gorditoNo ratings yet
- Overview of The EACJDocument14 pagesOverview of The EACJgorditoNo ratings yet
- A Simple PDFDocument2 pagesA Simple PDFJaheer MakalNo ratings yet
- Resort Map: Click Desired Area To View More DetailDocument7 pagesResort Map: Click Desired Area To View More DetailgorditoNo ratings yet
- Progress Report Vol.1 Final 01.04.2016Document576 pagesProgress Report Vol.1 Final 01.04.2016gorditoNo ratings yet
- Shirgure P.S. (2013) 28-35Document9 pagesShirgure P.S. (2013) 28-35gorditoNo ratings yet
- 5 - Freezing and Frozen Storage of Fish and Shellfish ProductsDocument10 pages5 - Freezing and Frozen Storage of Fish and Shellfish ProductsgorditoNo ratings yet
- Impacts of sequential stresses on maize crop and simulationDocument11 pagesImpacts of sequential stresses on maize crop and simulationgorditoNo ratings yet
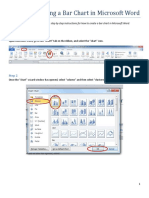
- Create Bar Charts in WordDocument6 pagesCreate Bar Charts in WordgorditoNo ratings yet
- Covid 19 Pho Order Nightclubs Food DrinkDocument16 pagesCovid 19 Pho Order Nightclubs Food DrinkgorditoNo ratings yet
- IJAS Feb.'2016Document3 pagesIJAS Feb.'2016gorditoNo ratings yet
- In The Shadow of HappinessDocument42 pagesIn The Shadow of HappinessLuke MarcusNo ratings yet
- ºéæºlééxé Eòé Éöj É (Éê®Úºé®: Deòewue-PetveDocument24 pagesºéæºlééxé Eòé Éöj É (Éê®Úºé®: Deòewue-PetvegorditoNo ratings yet
- Report of The 2nd Timor-Leste National Aquaculture ForumDocument23 pagesReport of The 2nd Timor-Leste National Aquaculture ForumgorditoNo ratings yet
- GS1 General SpecificationsDocument516 pagesGS1 General SpecificationssamuelNo ratings yet
- 2008211221-Kumar ContractorDocument2 pages2008211221-Kumar ContractorgorditoNo ratings yet
- Eaton 9130 Tower UPS: Product BrochureDocument2 pagesEaton 9130 Tower UPS: Product BrochuregorditoNo ratings yet
- Zulu Lady Property Report Provides Geological Analysis and Exploration RecommendationsDocument24 pagesZulu Lady Property Report Provides Geological Analysis and Exploration RecommendationsgorditoNo ratings yet
- Living and Surviving TampaDocument41 pagesLiving and Surviving TampagorditoNo ratings yet
- Istrict Tampa Ybor City: Nnel D Ntown Tampa HarbouDocument3 pagesIstrict Tampa Ybor City: Nnel D Ntown Tampa HarbougorditoNo ratings yet
- Metis 238352Document7 pagesMetis 238352gorditoNo ratings yet
- Natura 2000 PAF for Territory 2014-2020Document38 pagesNatura 2000 PAF for Territory 2014-2020gorditoNo ratings yet
- SciPostPhys 4 3 014Document34 pagesSciPostPhys 4 3 014gorditoNo ratings yet
- A Rapid Bootstrap Algorithm For The Raxml Web ServersDocument14 pagesA Rapid Bootstrap Algorithm For The Raxml Web ServersgorditoNo ratings yet
- Rapid Diagnostic Centres Vision and ImplementationDocument41 pagesRapid Diagnostic Centres Vision and ImplementationgorditoNo ratings yet
- Lesson Plan Lbs 400Document3 pagesLesson Plan Lbs 400api-286079584No ratings yet
- Times Zones Level 1 - Students BookDocument148 pagesTimes Zones Level 1 - Students BookYanka BeatrizNo ratings yet
- Software Testing Technical FAQsDocument115 pagesSoftware Testing Technical FAQsKambhampati RaghavendraNo ratings yet
- Wuolah Free Katherine Mansfield BlissDocument17 pagesWuolah Free Katherine Mansfield Blissinmaculadaferia23No ratings yet
- 2019 02 05 Lecture3 sql2 PDFDocument123 pages2019 02 05 Lecture3 sql2 PDFibnusani31No ratings yet
- Neonate Movement Is Synchronized With Adult SpeechDocument3 pagesNeonate Movement Is Synchronized With Adult SpeechMarie Christine laznikNo ratings yet
- Uniguard ManualDocument30 pagesUniguard ManualRuben Ortiz CaramNo ratings yet
- Vocabulary: Where Can You Find The Following Things? Match The Pictures To The Geographical FeaturesDocument3 pagesVocabulary: Where Can You Find The Following Things? Match The Pictures To The Geographical FeaturesAnonymous DYWcBrC4No ratings yet
- Literacy Planning Sheet Year Group: Reception Stimulus: Jolly Phonics Day Skill Learning Objective Main Teaching Focused Task(s) Key Skill 1Document2 pagesLiteracy Planning Sheet Year Group: Reception Stimulus: Jolly Phonics Day Skill Learning Objective Main Teaching Focused Task(s) Key Skill 1Engy HassanNo ratings yet
- Curriculum Vitae: Tubagus G.PDocument3 pagesCurriculum Vitae: Tubagus G.PTB Gita PriadiNo ratings yet
- Diaz Deanna WritingtheoryessaygradedDocument7 pagesDiaz Deanna Writingtheoryessaygradedapi-242147675No ratings yet
- Yl8 Whats The Weather Like UkDocument5 pagesYl8 Whats The Weather Like UkSylwiaNo ratings yet
- GEM S2 - S3 Issues - HXC Floppy Drive EmulatorDocument6 pagesGEM S2 - S3 Issues - HXC Floppy Drive EmulatorMentore SiestoNo ratings yet
- Questões EPCAR - Simulado 1Document5 pagesQuestões EPCAR - Simulado 1meusgatos2024No ratings yet
- Edu 201 Portfolio Project 4 - PhilosophyDocument5 pagesEdu 201 Portfolio Project 4 - Philosophyapi-616989648No ratings yet
- Flannel (Felt) Boards and Activity Sets: All Rights ReservedDocument9 pagesFlannel (Felt) Boards and Activity Sets: All Rights ReservedHammad TauqeerNo ratings yet
- Role of Design Department in Printing TextileDocument14 pagesRole of Design Department in Printing TextileAbdul RaphayNo ratings yet
- 3 5 PronounsDocument3 pages3 5 PronounsPratyuusha PunjabiNo ratings yet
- Adventist Youth Class - GuideDocument56 pagesAdventist Youth Class - Guideapi-270614046No ratings yet
- Writing a Reply LetterDocument1 pageWriting a Reply Letterhbat saidNo ratings yet
- Mathematics in The Modern WorldDocument3 pagesMathematics in The Modern WorldRey Angelica Garcia TampusNo ratings yet
- Sweet Khenjeza Pornela Bsed-Ii March 9, 2021 Mrs. Marites Estremadura VergaraDocument2 pagesSweet Khenjeza Pornela Bsed-Ii March 9, 2021 Mrs. Marites Estremadura VergaraKhenjeza PornelaNo ratings yet
- WiX TutorialDocument63 pagesWiX Tutorialr0k0t100% (4)
- Modul 5 B Inggris Kls 1 - KD 3.5 - 4.5Document16 pagesModul 5 B Inggris Kls 1 - KD 3.5 - 4.5kebonarekNo ratings yet
- Vietnam War Essay Question Ehd520Document4 pagesVietnam War Essay Question Ehd520api-295133412No ratings yet
- DLL-Q3 Week3Document23 pagesDLL-Q3 Week3Crisalline SantosNo ratings yet
- Unit 3Document9 pagesUnit 3AjmalNo ratings yet