You might also like
- Numerical Analysis: Errors in Numerical ComputationsDocument275 pagesNumerical Analysis: Errors in Numerical ComputationsSayyeda Neha Fatima100% (1)
- Chapter 1 - Modelling, Computers and Error AnalysisDocument35 pagesChapter 1 - Modelling, Computers and Error AnalysisAzmiHafifiNo ratings yet
- Digital ElectronicsDocument64 pagesDigital ElectronicshaalefomNo ratings yet
- DFA and NFA Complete ExamplesDocument23 pagesDFA and NFA Complete ExamplesAbbas HasanNo ratings yet
- CS323: Lecture #1: Types of ErrorsDocument4 pagesCS323: Lecture #1: Types of ErrorsMuhammad chaudharyNo ratings yet
- November 2012 Bachelor of Computer Application (BCA) - Semester 3 BC0043 - Computer Oriented Numericalmethods - 4 CreditsDocument5 pagesNovember 2012 Bachelor of Computer Application (BCA) - Semester 3 BC0043 - Computer Oriented Numericalmethods - 4 CreditsChandan KumarNo ratings yet
- Scientific Computing - LESSON 1: Computer Arithmetic and Error Analysis 1Document10 pagesScientific Computing - LESSON 1: Computer Arithmetic and Error Analysis 1Lee Hei LongNo ratings yet
- Numerical MethodsDocument72 pagesNumerical MethodsAndreas NeophytouNo ratings yet
- Numerical Analysis 1Document81 pagesNumerical Analysis 1tinotenda nziramasangaNo ratings yet
- MAT005-Lab-Exercise-3Document3 pagesMAT005-Lab-Exercise-3junalynnerosaNo ratings yet
- Mathematical ModelingDocument14 pagesMathematical ModelingClary FrayNo ratings yet
- ErrorsDocument106 pagesErrorsapi-375687150% (2)
- Course Code: CS-71 Course Title: Computer Oriented Numerical TechniquesDocument5 pagesCourse Code: CS-71 Course Title: Computer Oriented Numerical TechniquesJasmeet SinghNo ratings yet
- Programming Fundamentals (CS1002) : Assignment 4 (125 Marks) + 10 Bonus MarksDocument5 pagesProgramming Fundamentals (CS1002) : Assignment 4 (125 Marks) + 10 Bonus MarksGM IqbalNo ratings yet
- Numerical Analysis Lecture NotesDocument122 pagesNumerical Analysis Lecture NotesDr Simran KaurNo ratings yet
- Roundoff and Truncation Errors in Engineering CalculationsDocument25 pagesRoundoff and Truncation Errors in Engineering CalculationsAnonymous ueh2VMT5GNo ratings yet
- What Is Your Structural Model Not Telling YouDocument11 pagesWhat Is Your Structural Model Not Telling YouMohammed Junaid ShaikhNo ratings yet
- Teknik Komputasi (TEI 116) : 3 Sks Oleh: Husni Rois Ali, S.T., M.Eng. Noor Akhmad Setiawan, S.T., M.T., PH.DDocument44 pagesTeknik Komputasi (TEI 116) : 3 Sks Oleh: Husni Rois Ali, S.T., M.Eng. Noor Akhmad Setiawan, S.T., M.T., PH.DblackzenyNo ratings yet
- Exdbjava PDFDocument22 pagesExdbjava PDFelibunNo ratings yet
- Exercises Java Code Blocks Conditionals Loops PrecisionDocument22 pagesExercises Java Code Blocks Conditionals Loops PrecisionVũ HiềnNo ratings yet
- Numerical Programming I (For CSE) : Final ExamDocument8 pagesNumerical Programming I (For CSE) : Final ExamhisuinNo ratings yet
- Arbitrary-Precision Decimal Floating-Point NumbersDocument6 pagesArbitrary-Precision Decimal Floating-Point Numbers黄子龙No ratings yet
- Data Analysis Assignment HelpDocument8 pagesData Analysis Assignment HelpStatistics Homework SolverNo ratings yet
- Lect 3 ErrorsDocument5 pagesLect 3 ErrorsAlaa FjNo ratings yet
- An Introduction To Affine ArithmeticDocument16 pagesAn Introduction To Affine Arithmeticgigio lassoNo ratings yet
- Numerical Methods BasicsDocument24 pagesNumerical Methods Basicsfatcode27No ratings yet
- Lecture 3: Numerical Error: Zhenning Cai August 26, 2019Document5 pagesLecture 3: Numerical Error: Zhenning Cai August 26, 2019Liu JianghaoNo ratings yet
- Calculating Consumer Surplus Using IntegrationDocument18 pagesCalculating Consumer Surplus Using IntegrationDan EnzerNo ratings yet
- NG - Argument Reduction For Huge Arguments: Good To The Last BitDocument8 pagesNG - Argument Reduction For Huge Arguments: Good To The Last BitDerek O'ConnorNo ratings yet
- R Numeric ProgrammingDocument124 pagesR Numeric Programmingvsuarezf2732100% (1)
- Numerical Methods: Rounding Error and ConditioningDocument11 pagesNumerical Methods: Rounding Error and ConditioningMiljan TrivicNo ratings yet
- Basic Number Theory-1: Tutorial ProblemsDocument10 pagesBasic Number Theory-1: Tutorial ProblemsdkitovNo ratings yet
- Automatic Differentiation, C++ Templates AndPhotogrammetryDocument14 pagesAutomatic Differentiation, C++ Templates AndPhotogrammetrygorot1No ratings yet
- MEC503 Lecture2Document8 pagesMEC503 Lecture2مصطفى عبدالله عبدالرحمن اغاNo ratings yet
- ELEC3030 Notes v1Document118 pagesELEC3030 Notes v1kosmos3384No ratings yet
- Numerical Analysis 1 - 2022-2023 CoursesDocument65 pagesNumerical Analysis 1 - 2022-2023 Courseschaymaahamou2015No ratings yet
- Adaptive Quadrature RevisitedDocument19 pagesAdaptive Quadrature RevisitedVenkatesh PeriasamyNo ratings yet
- Computing Numerically With Functions Instead of NumbersDocument11 pagesComputing Numerically With Functions Instead of NumbersSaifuddin AriefNo ratings yet
- Fast Inverse Square RootDocument8 pagesFast Inverse Square RootMaxminlevelNo ratings yet
- Adaptive Quadrature RevisitedDocument18 pagesAdaptive Quadrature RevisitedSaifuddin AriefNo ratings yet
- (Turner) - Applied Scientific Computing - Chap - 02Document19 pages(Turner) - Applied Scientific Computing - Chap - 02DanielaSofiaRubianoBlancoNo ratings yet
- Sample Solutions For System DynamicsDocument7 pagesSample Solutions For System DynamicsameershamiehNo ratings yet
- Adaptive Quadrature RevisitedDocument19 pagesAdaptive Quadrature RevisitedDianaNo ratings yet
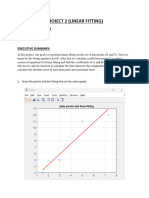
- sunjay_project2_linearDocument3 pagessunjay_project2_linearch8fzk5v74No ratings yet
- 1456308539E textofChapter1Module1Document10 pages1456308539E textofChapter1Module1Santosh SuryavanshiNo ratings yet
- Numerical Analysis Errors and ApproximationsDocument11 pagesNumerical Analysis Errors and ApproximationsAmheph SoftNo ratings yet
- MA402 Hw1 SolutionDocument6 pagesMA402 Hw1 SolutionAndrea StancescuNo ratings yet
- Math2059 p2Document23 pagesMath2059 p2mecengNo ratings yet
- Numc PDFDocument18 pagesNumc PDFMadhur MayankNo ratings yet
- Solutions Manual Scientific ComputingDocument192 pagesSolutions Manual Scientific ComputingSanjeev Gupta0% (1)
- CP NumericalDifferentiationDocument3 pagesCP NumericalDifferentiationAini SukurNo ratings yet
- Curve Fitting TechniquesDocument14 pagesCurve Fitting TechniquesAveenNo ratings yet
- Approximations and Errors in Numerical ComputingDocument12 pagesApproximations and Errors in Numerical ComputingAhmadul Karim Chowdhury100% (2)
- Chap 12Document22 pagesChap 12Hadi HassanNo ratings yet
- IP2223 Lab 1Document4 pagesIP2223 Lab 1MhmNo ratings yet
- Fourth Yr S1 Ch19Document89 pagesFourth Yr S1 Ch19Thar KoNo ratings yet
- CH#1 Error Analysis & Difference Operators-06-03-2023-Fisrt-FormDocument66 pagesCH#1 Error Analysis & Difference Operators-06-03-2023-Fisrt-FormSyed HuzaifaNo ratings yet
- Sail Mast ReportDocument6 pagesSail Mast ReportMax KondrathNo ratings yet
- Solving Equations (Finding Zeros)Document20 pagesSolving Equations (Finding Zeros)nguyendaibkaNo ratings yet
- Computational Error and Complexity in Science and Engineering: Computational Error and ComplexityFrom EverandComputational Error and Complexity in Science and Engineering: Computational Error and ComplexityNo ratings yet
- Module1.3-Data Manipulation-Digital Codes&SignedNumberRepresentationDocument25 pagesModule1.3-Data Manipulation-Digital Codes&SignedNumberRepresentationTeejay De GuzmanNo ratings yet
- Number Systems, Operations, and CodesDocument35 pagesNumber Systems, Operations, and CodesMohamed SaadNo ratings yet
- LECTURE B 2 Minimization of The FSMDocument24 pagesLECTURE B 2 Minimization of The FSMShiladitya GangulyNo ratings yet
- Chapter 4: Combinational Circuits Analysis and DesignDocument26 pagesChapter 4: Combinational Circuits Analysis and DesignAbdul RehmanNo ratings yet
- Mid Semester Exam - Computer Fundamentals - (101) - SLIITDocument4 pagesMid Semester Exam - Computer Fundamentals - (101) - SLIITSankha Palihawadana100% (2)
- Instruction: Answer ALL The Questions: MCFC Sample Test Ge 1 of 3Document3 pagesInstruction: Answer ALL The Questions: MCFC Sample Test Ge 1 of 3Arvin KovanNo ratings yet
- Sequential Logic: Inel 4205 Logic Circuits SPRING 2008Document54 pagesSequential Logic: Inel 4205 Logic Circuits SPRING 2008Hanish ChowdaryNo ratings yet
- Ugrd cs6301 Logic Design Digital Computer Circuits Prelim To Finals Perfect - CompressDocument9 pagesUgrd cs6301 Logic Design Digital Computer Circuits Prelim To Finals Perfect - CompressMike Rafael NagañoNo ratings yet
- Modifications OF Turing MachinesDocument20 pagesModifications OF Turing MachinesGajalakshmi AshokNo ratings yet
- AM - EN.U4CSE20148 COA Lab Sheet 4Document13 pagesAM - EN.U4CSE20148 COA Lab Sheet 4Arjun ReddyNo ratings yet
- FLA Unit IV PDADocument16 pagesFLA Unit IV PDAnlʇɐ ɯnsıɔ ULTA MUSICNo ratings yet
- Lecture 12Document22 pagesLecture 12Lord BeerusNo ratings yet
- Solutions For Problem Set 7: CS 373: Theory of ComputationDocument3 pagesSolutions For Problem Set 7: CS 373: Theory of ComputationJoshNo ratings yet
- UntitledDocument4 pagesUntitledBigious BoiousNo ratings yet
- Experiment-10 (Adder & Subtractor)Document7 pagesExperiment-10 (Adder & Subtractor)M BalajiNo ratings yet
- CEF352 Lect2Document18 pagesCEF352 Lect2Tabi JosephNo ratings yet
- Structural InductionDocument52 pagesStructural InductionDavid IancuNo ratings yet
- Chapter 4 and 5Document71 pagesChapter 4 and 5Mikiyas AbebeNo ratings yet
- Minimize DFA and Construct NFA for Regular ExpressionDocument3 pagesMinimize DFA and Construct NFA for Regular Expressionsaurabmi2No ratings yet
- Technical Software Pic Crc16Document7 pagesTechnical Software Pic Crc16Esmael PradoNo ratings yet
- M SC CS Syllabus 2017 2018 PDFDocument49 pagesM SC CS Syllabus 2017 2018 PDFRaja ANo ratings yet
- Pointers and Reference Parameters: CSE 251 Dr. Charles B. Owen Programming in C 1Document44 pagesPointers and Reference Parameters: CSE 251 Dr. Charles B. Owen Programming in C 1NEERATINo ratings yet
- Mrs.v.uma Digital System Design LABDocument70 pagesMrs.v.uma Digital System Design LABRutuja KakadeNo ratings yet
- Assignment 3Document3 pagesAssignment 3SA GamingNo ratings yet
- Chapt 07Document74 pagesChapt 07anand_duraiswamyNo ratings yet
- 2 Data RepresentationDocument20 pages2 Data RepresentationHuma IqrarNo ratings yet
- Digital Logic & Processors: Design Concepts of ALU: Arithmetic FunctionsDocument23 pagesDigital Logic & Processors: Design Concepts of ALU: Arithmetic Functionskoppuravuri kusumaNo ratings yet
- Complexity Theory - Chapter 1 - IntroductionDocument14 pagesComplexity Theory - Chapter 1 - IntroductionMaki ErkuNo ratings yet