You might also like
- Research Paper On String MatchingDocument7 pagesResearch Paper On String Matchingggteukwhf100% (1)
- Unit-4 AdsDocument31 pagesUnit-4 AdsRohit Kumar100% (1)
- UNIT-V String MatchingDocument24 pagesUNIT-V String MatchingJaya krishnaNo ratings yet
- Brute Force AlgorithmDocument4 pagesBrute Force AlgorithmShima FanissaNo ratings yet
- Brute Force Algorithm PDFDocument4 pagesBrute Force Algorithm PDFRaj VermaNo ratings yet
- DS V Unit NotesDocument33 pagesDS V Unit NotesAlagandula KalyaniNo ratings yet
- A Fast String Matching Algorithm: H N Verma, Ravendra Singh M.Tech (CSE-0104cs09mt16) RKDF IST Bhopal, IndiaDocument7 pagesA Fast String Matching Algorithm: H N Verma, Ravendra Singh M.Tech (CSE-0104cs09mt16) RKDF IST Bhopal, IndiaRobbi Zhuge RahimNo ratings yet
- A FAST Pattern Matching Algorithm: S. S. Sheik, Sumit K. Aggarwal, Anindya Poddar, N. Balakrishnan, and K. SekarDocument6 pagesA FAST Pattern Matching Algorithm: S. S. Sheik, Sumit K. Aggarwal, Anindya Poddar, N. Balakrishnan, and K. SekarAbdul RafayNo ratings yet
- A Two Way Pattern Matching Algorithm Using Sliding PatternsDocument5 pagesA Two Way Pattern Matching Algorithm Using Sliding PatternsganeshNo ratings yet
- Design and Analysis of Algorithms: Dr. Sobia ArshadDocument43 pagesDesign and Analysis of Algorithms: Dr. Sobia ArshadMohsin AliNo ratings yet
- Adsa ReportDocument9 pagesAdsa ReportShaurya SethiNo ratings yet
- A Fast Algorithm For Multi-Pattern SearchingDocument11 pagesA Fast Algorithm For Multi-Pattern SearchingHovo ApoyanNo ratings yet
- Data Structures Unit 5Document20 pagesData Structures Unit 5SYED SHDNNo ratings yet
- Bidirectional Exact Pattern Matching Algorithm: Iftikhar Hussain, Muhammad Zubair, Jamil Ahmed and Junaid ZaffarDocument1 pageBidirectional Exact Pattern Matching Algorithm: Iftikhar Hussain, Muhammad Zubair, Jamil Ahmed and Junaid ZaffarZia RehmanNo ratings yet
- PartB ReportDocument10 pagesPartB ReportMohammed Zeaul HaqueNo ratings yet
- 8 TextProcessingDocument40 pages8 TextProcessingĐàm ChiếnNo ratings yet
- String Algorithms in C: Efficient Text Representation and SearchFrom EverandString Algorithms in C: Efficient Text Representation and SearchNo ratings yet
- Research Paper On Knuth Morris PrattDocument6 pagesResearch Paper On Knuth Morris Prattfyr5efrr100% (1)
- Commentz-Walter: Any Better Than Aho-Corasick For Peptide Identification?Document5 pagesCommentz-Walter: Any Better Than Aho-Corasick For Peptide Identification?White Globe Publications (IJORCS)No ratings yet
- Acstv10n8 43Document14 pagesAcstv10n8 43yetsedawNo ratings yet
- Trings and Attern Atching: - Brute Force, Rabin-Karp, Knuth-Morris-Pratt - Regular ExpressionsDocument21 pagesTrings and Attern Atching: - Brute Force, Rabin-Karp, Knuth-Morris-Pratt - Regular ExpressionsPranjal SanjanwalaNo ratings yet
- Pattern Search in A Single GenomeDocument34 pagesPattern Search in A Single GenomeChaNifatul ChaiRiyahNo ratings yet
- String MatchingDocument27 pagesString Matchingprateekrana462No ratings yet
- String Match - Horspool Sad LifeDocument4 pagesString Match - Horspool Sad Lifezamirk kaoNo ratings yet
- Trings and Attern Atching: - Brute Force, Rabin-Karp, Knuth-Morris-PrattDocument49 pagesTrings and Attern Atching: - Brute Force, Rabin-Karp, Knuth-Morris-PrattslogeshwariNo ratings yet
- String Matching Algorithms: International Journal of Engineering and Computer Science March 2018Document5 pagesString Matching Algorithms: International Journal of Engineering and Computer Science March 2018bishal sarmaNo ratings yet
- AbstractDocument12 pagesAbstractSrilu SateeshNo ratings yet
- CT Lecture 5-Applications of FADocument15 pagesCT Lecture 5-Applications of FAelizayoelsNo ratings yet
- Fast Pattern Matching In: StringsDocument28 pagesFast Pattern Matching In: Stringsvanaj123No ratings yet
- String MatchingDocument18 pagesString MatchingTamim HossainNo ratings yet
- String Matching Algorithms: 1 Brute ForceDocument5 pagesString Matching Algorithms: 1 Brute ForceAarushi RaiNo ratings yet
- RB Matcher String Matching TechniqueDocument4 pagesRB Matcher String Matching TechniqueRaseshJaniNo ratings yet
- Position S + 1 in Text T) If 0 S N - M and T (S + 1 - . S + M) P (1 - . M) (That Is, If T (S + J) P (J), For 1 J M) - IfDocument2 pagesPosition S + 1 in Text T) If 0 S N - M and T (S + 1 - . S + M) P (1 - . M) (That Is, If T (S + J) P (J), For 1 J M) - IfXavier TxA100% (1)
- String Matching 0Document40 pagesString Matching 0avikantk94No ratings yet
- Purdue E-Pubs Purdue E-PubsDocument18 pagesPurdue E-Pubs Purdue E-PubsSuraj SameersimNo ratings yet
- Rabin Karp Plagiarism CheckDocument16 pagesRabin Karp Plagiarism ChecknishetaNo ratings yet
- Brute Force AlgorithmDocument14 pagesBrute Force AlgorithmRakshita Tuli100% (1)
- A Comparison of Single Keyword Pattern Matching Algorithms: AbstractDocument5 pagesA Comparison of Single Keyword Pattern Matching Algorithms: AbstractInternational Journal of Engineering and TechniquesNo ratings yet
- Paper 20Document4 pagesPaper 20wisdombasedcomputingNo ratings yet
- Lecture Notes On Pattern Matching AlgorithmsDocument16 pagesLecture Notes On Pattern Matching AlgorithmsNAEEM99No ratings yet
- Information Retrieval - Chapter 10 - String Searching AlgorithmsDocument27 pagesInformation Retrieval - Chapter 10 - String Searching Algorithmsmohamed.khalidNo ratings yet
- Fast Pattern Matching in Strings Knuth PDFDocument2 pagesFast Pattern Matching in Strings Knuth PDFBethNo ratings yet
- Rabin-Karp String Matching Algorithm: Presented By: Marish Kr. GuptaDocument18 pagesRabin-Karp String Matching Algorithm: Presented By: Marish Kr. GuptaMarishSinglaNo ratings yet
- Rabin KarpDocument13 pagesRabin KarpIT Skills All About TechnologiesNo ratings yet
- Fast Pattern Matching in Strings PDFDocument2 pagesFast Pattern Matching in Strings PDFJasonNo ratings yet
- StringsDocument23 pagesStringsAbhijit SinhaNo ratings yet
- Sample Entropy 1Document13 pagesSample Entropy 1DetaiACNo ratings yet
- Survey Paper On String MatchingDocument4 pagesSurvey Paper On String MatchingSaurabh KumarNo ratings yet
- Boyer-Moore String Search: - How Does It Work? - Examples - Complexity - AcknowledgementsDocument14 pagesBoyer-Moore String Search: - How Does It Work? - Examples - Complexity - AcknowledgementsjyoshnaNo ratings yet
- Space and Time Trade OffDocument8 pagesSpace and Time Trade OffSheshnath HadbeNo ratings yet
- Ir AsnmentDocument6 pagesIr AsnmentFijul AhammedNo ratings yet
- Text Pattern Search Using Naïve Algorithm: Justine Estoesta, Patricia Mae Omana, Winci John SinghDocument5 pagesText Pattern Search Using Naïve Algorithm: Justine Estoesta, Patricia Mae Omana, Winci John SinghjustineNo ratings yet
- A Fast Multiple String-Pattern Matching AlgorithmDocument22 pagesA Fast Multiple String-Pattern Matching AlgorithmVenki MeenuNo ratings yet
- Logical IndexingDocument6 pagesLogical IndexingrickycuyNo ratings yet
- UNIT-4 PPT NewDocument47 pagesUNIT-4 PPT Newlaxmi.slvNo ratings yet
- Sequence Similarity Between Genetic Codes Using Improved Longest Common Subsequence AlgorithmDocument4 pagesSequence Similarity Between Genetic Codes Using Improved Longest Common Subsequence AlgorithmEditor IJRITCCNo ratings yet
- UNIT-5 DAA Complete NotesDocument52 pagesUNIT-5 DAA Complete NotesAman LakhwariaNo ratings yet
- String Matching Algorithms and Their Applicability in Various ApplicationsDocument5 pagesString Matching Algorithms and Their Applicability in Various ApplicationsyetsedawNo ratings yet
- 11 Data Structures and Algorithms - Narasimha KarumanchiDocument12 pages11 Data Structures and Algorithms - Narasimha KarumanchiAngelinaPramanaNo ratings yet
- Nformation Etrieval Ystems: P.Veera SwamyDocument73 pagesNformation Etrieval Ystems: P.Veera Swamyganeshjaggineni1927No ratings yet
- Integrated Services: Dr. Siwar RekikDocument19 pagesIntegrated Services: Dr. Siwar RekiknourahNo ratings yet
- Fundamentals of Analysis of Algorithms EfficiencyDocument40 pagesFundamentals of Analysis of Algorithms EfficiencynourahNo ratings yet
- Differentiated Services: Dr. Lamia BerricheDocument12 pagesDifferentiated Services: Dr. Lamia BerrichenourahNo ratings yet
- Differentiated Services: Dr. Lamia BerricheDocument12 pagesDifferentiated Services: Dr. Lamia BerrichenourahNo ratings yet
- CH 01 NDocument21 pagesCH 01 NnourahNo ratings yet
- CH 01 NDocument21 pagesCH 01 NnourahNo ratings yet
- A Review of Various K-Nearest Neighbor Query Processing TechniquesDocument10 pagesA Review of Various K-Nearest Neighbor Query Processing TechniquesnourahNo ratings yet
- 2013 Midterm 2 Exam SolutionDocument10 pages2013 Midterm 2 Exam SolutionnourahNo ratings yet
- Exact String Matching Algorithms Survey Issues andDocument25 pagesExact String Matching Algorithms Survey Issues andnourahNo ratings yet
- ExercisesOSPF English WithSolutionsDocument5 pagesExercisesOSPF English WithSolutionsnourahNo ratings yet
- ExercisesOSPF English WithSolutionsDocument5 pagesExercisesOSPF English WithSolutionsnourahNo ratings yet
- Computer Networking: ExercisesDocument69 pagesComputer Networking: ExercisesnourahNo ratings yet
- A Genetic Algorithm For The Maximum Clique ProblemDocument29 pagesA Genetic Algorithm For The Maximum Clique ProblemnourahNo ratings yet
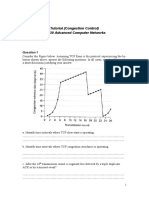
- Tutorial (Congestion Control) CS630 Advanced Computer NetworksDocument3 pagesTutorial (Congestion Control) CS630 Advanced Computer NetworksnourahNo ratings yet
- Frame 1 Captured On Router R1: Tutorial (MPLS) CS630 Advanced Computer NetworksDocument4 pagesFrame 1 Captured On Router R1: Tutorial (MPLS) CS630 Advanced Computer NetworksnourahNo ratings yet
- Frame 1 Captured On Router R1: Tutorial (MPLS) CS630 Advanced Computer NetworksDocument4 pagesFrame 1 Captured On Router R1: Tutorial (MPLS) CS630 Advanced Computer NetworksnourahNo ratings yet
- Tcpip AnswersDocument4 pagesTcpip AnswersFarhan Sheikh MuhammadNo ratings yet
- Kuliah5.1 - (Integrasi Numerik)Document120 pagesKuliah5.1 - (Integrasi Numerik)adrian bargasNo ratings yet
- Introduction To Numerical Analysis: Cho, Hyoung Kyu Cho, Hyoung KyuDocument93 pagesIntroduction To Numerical Analysis: Cho, Hyoung Kyu Cho, Hyoung Kyusadik paltaNo ratings yet
- Vlsidsp Chap4 PDFDocument33 pagesVlsidsp Chap4 PDFgaru1991No ratings yet
- Audio Processing Using MatlabDocument12 pagesAudio Processing Using MatlabMuneeb IrfanNo ratings yet
- 8 - 10. DS Theory and Lab SyllabusDocument3 pages8 - 10. DS Theory and Lab SyllabusChennamadhavuni SahithiNo ratings yet
- Islamic University of Technology (IUT) : ObjectiveDocument4 pagesIslamic University of Technology (IUT) : ObjectiveNazifa NawerNo ratings yet
- Cso 102 Week 1Document30 pagesCso 102 Week 1Rahul kumar KeshriNo ratings yet
- Assignement Problem Case StudyDocument6 pagesAssignement Problem Case StudyYubraj JhaNo ratings yet
- Control Systems Laboratory: Hamza OSAMA &haider Jamal&salah MahdiDocument27 pagesControl Systems Laboratory: Hamza OSAMA &haider Jamal&salah MahdiAhmed Mohammed khalfNo ratings yet
- Computational Methods in Engineering: Code No: MA1902 M. Tech I Semester Regular Examinations, April 2015Document2 pagesComputational Methods in Engineering: Code No: MA1902 M. Tech I Semester Regular Examinations, April 2015Joshua SimonNo ratings yet
- Computers & Industrial Engineering: Guohui Zhang, Xinyu Shao, Peigen Li, Liang GaoDocument10 pagesComputers & Industrial Engineering: Guohui Zhang, Xinyu Shao, Peigen Li, Liang Gaocloud69windNo ratings yet
- 01 InterpolationDocument9 pages01 InterpolationNagesh RaoNo ratings yet
- MIT Numerical PDEDocument119 pagesMIT Numerical PDEKruger JoeNo ratings yet
- A Common-Sense Guide To Data Structures and Algorithms, Second EditionDocument14 pagesA Common-Sense Guide To Data Structures and Algorithms, Second Editionabnaod5363No ratings yet
- EE 583 Lecture10Document26 pagesEE 583 Lecture10AndriyonoHutagalungNo ratings yet
- ML Ques Bank For 3rd Unit PDFDocument8 pagesML Ques Bank For 3rd Unit PDFshreyashNo ratings yet
- Frequency Domain Least-Squares Reverse Time Migration Using Low-Rank Green'S Function For High Memory EfficiencyDocument5 pagesFrequency Domain Least-Squares Reverse Time Migration Using Low-Rank Green'S Function For High Memory EfficiencyRodrigo SantanaNo ratings yet
- Informed Search Algorithms: Chapter 3, Sections 5-6Document24 pagesInformed Search Algorithms: Chapter 3, Sections 5-6SridharNo ratings yet
- Chapter14 PDFDocument11 pagesChapter14 PDFHimanshuNo ratings yet
- Segmentation 05Document29 pagesSegmentation 05KumarPatraNo ratings yet
- Res NetDocument46 pagesRes Netjaffar bikatNo ratings yet
- ML (AutoRecovered)Document4 pagesML (AutoRecovered)IQRA IMRANNo ratings yet
- Age Estimation Using Ensemble of Deep Learning Models: Author NameDocument46 pagesAge Estimation Using Ensemble of Deep Learning Models: Author NameRifat ParveenNo ratings yet
- Pink4 ManualDocument60 pagesPink4 ManualNERDE-SE MAISNo ratings yet
- QuestionsDocument4 pagesQuestionsJayachandra JcNo ratings yet
- Machine Learning For Natural Language Processing: Hidden Markov ModelsDocument33 pagesMachine Learning For Natural Language Processing: Hidden Markov ModelsHưngNo ratings yet
- Vlsi - FFT Report FinalDocument22 pagesVlsi - FFT Report Finalkk0511No ratings yet
- Gradient Descent: Disclaimer: This PPT Is Modified Based On Hung-Yi LeeDocument38 pagesGradient Descent: Disclaimer: This PPT Is Modified Based On Hung-Yi Leeaniketshrimal986749No ratings yet
- Machine Learning Complete-Course-Notes PolimiDocument107 pagesMachine Learning Complete-Course-Notes PolimiabcdNo ratings yet
- PolynomialsDocument17 pagesPolynomialschand7790100% (3)