You might also like
- Unlocking Concurrency: Computer ArchitectureDocument10 pagesUnlocking Concurrency: Computer ArchitectureSaisri ReddyNo ratings yet
- Introduction To Parallel Computing: John Von Neumann Institute For ComputingDocument18 pagesIntroduction To Parallel Computing: John Von Neumann Institute For Computingsandeep_nagar29No ratings yet
- Potential Approaches To Parallel Computation of Rayleigh Integrals in Measuring Acoustic Pressure and IntensityDocument5 pagesPotential Approaches To Parallel Computation of Rayleigh Integrals in Measuring Acoustic Pressure and Intensityblhblh123No ratings yet
- Chapter 1Document25 pagesChapter 1chinmayNo ratings yet
- Rahul Bansal 360 Parallel Computing FileDocument67 pagesRahul Bansal 360 Parallel Computing FileRanjeet SinghNo ratings yet
- Week 5 - The Impact of Multi-Core Computing On Computational OptimizationDocument11 pagesWeek 5 - The Impact of Multi-Core Computing On Computational OptimizationGame AccountNo ratings yet
- 2.3 Dichotomy of Parallel Computing PlatformsDocument6 pages2.3 Dichotomy of Parallel Computing PlatformsNaira ElazabNo ratings yet
- 18 R. A. Kendall Et Al.: Mpi PutDocument4 pages18 R. A. Kendall Et Al.: Mpi PutlatinwolfNo ratings yet
- Capacity Planning For Virtual SystemsDocument11 pagesCapacity Planning For Virtual Systemssreeni17No ratings yet
- Crash-Only SoftwareDocument6 pagesCrash-Only SoftwareJeremySharpNo ratings yet
- Scimakelatex 14983 Some+thingDocument7 pagesScimakelatex 14983 Some+thingscribd-centralNo ratings yet
- CA Classes-251-255Document5 pagesCA Classes-251-255SrinivasaRaoNo ratings yet
- Modern Problems For The Smalltalk VM: Boris ShingarovDocument8 pagesModern Problems For The Smalltalk VM: Boris ShingarovSambasiva SudaNo ratings yet
- Supporting Linux Without An MMU Class #407: D. Jeff DionneDocument3 pagesSupporting Linux Without An MMU Class #407: D. Jeff Dionnemelvin45No ratings yet
- Towards Transparent Parallel/Distributed Support For Real-Time Embedded ApplicationsDocument4 pagesTowards Transparent Parallel/Distributed Support For Real-Time Embedded Applicationsbhalchimtushar0No ratings yet
- Scimakelatex 69254 Travis+Herrick Michael+meredith Austin+stoneDocument7 pagesScimakelatex 69254 Travis+Herrick Michael+meredith Austin+stoneTravis HerrickNo ratings yet
- Clustering The Java Virtual Machine Using Aspect-Oriented ProgrammingDocument8 pagesClustering The Java Virtual Machine Using Aspect-Oriented ProgrammingSharath VenkiNo ratings yet
- Computer96 PsDocument26 pagesComputer96 PsDom DeSiciliaNo ratings yet
- Minimizing Impact On JAVA Virtual Machine Via JAVA Code Optimization PDFDocument6 pagesMinimizing Impact On JAVA Virtual Machine Via JAVA Code Optimization PDFkkisNo ratings yet
- Memory ModelDocument35 pagesMemory Modelmgcse4866No ratings yet
- OS Plate 1Document5 pagesOS Plate 1Tara SearsNo ratings yet
- Global Semaphores in A Parallel Programming Environment P. Theodoropoulos, P° Tsanakas and G. PapakonstantinouDocument2 pagesGlobal Semaphores in A Parallel Programming Environment P. Theodoropoulos, P° Tsanakas and G. PapakonstantinouنورالدنياNo ratings yet
- Farhan Zaidi, Zakaullah Kiani Advanced IMS Inc. Ontario CanadaDocument23 pagesFarhan Zaidi, Zakaullah Kiani Advanced IMS Inc. Ontario CanadaGenilson AlmeidaNo ratings yet
- Operating System 2Document29 pagesOperating System 2nazim khanNo ratings yet
- Enabling Java For High-Performance Computing: Exploiting Distributed Shared Memory and Remote Method InvocationDocument14 pagesEnabling Java For High-Performance Computing: Exploiting Distributed Shared Memory and Remote Method InvocationlakshmiepathyNo ratings yet
- Parallel Processing in LINUX (PareshDocument13 pagesParallel Processing in LINUX (PareshDIPAK VINAYAK SHIRBHATENo ratings yet
- Module 5Document138 pagesModule 5yashu JNo ratings yet
- 3.3-Recent Trends in Parallel ComputingDocument12 pages3.3-Recent Trends in Parallel ComputingChetan SolankiNo ratings yet
- Answers Chapter 1 To 4Document4 pagesAnswers Chapter 1 To 4parameshwar6No ratings yet
- Novices Guide To Assembler - Part IIDocument6 pagesNovices Guide To Assembler - Part IIdavidkibmNo ratings yet
- Hotcloud15 WangDocument6 pagesHotcloud15 WangayeniNo ratings yet
- OS - Chapter - 4 - Memory ManagementDocument48 pagesOS - Chapter - 4 - Memory Managementabelcreed1994No ratings yet
- A Lightweight Real-Time Executable Finite State Machine ModelDocument6 pagesA Lightweight Real-Time Executable Finite State Machine ModelBogdan ComsaNo ratings yet
- Chapter 2 Embedded MicrocontrollersDocument5 pagesChapter 2 Embedded MicrocontrollersyishakNo ratings yet
- Modeling For Fault Tolerance in Cloud Computing EnvironmentDocument11 pagesModeling For Fault Tolerance in Cloud Computing EnvironmentMd Moazzem HossainNo ratings yet
- Asset-V1 VIT+MSC1004+2020+type@asset+block@W9 NotesDocument72 pagesAsset-V1 VIT+MSC1004+2020+type@asset+block@W9 NotesAYUSH GURTU 17BEC0185No ratings yet
- A Trip Down Memory LaneDocument2 pagesA Trip Down Memory LanehoalnNo ratings yet
- Constructing The Producer-Consumer Problem Using Heterogeneous ModelsDocument8 pagesConstructing The Producer-Consumer Problem Using Heterogeneous ModelsMauro MaldoNo ratings yet
- Mpi CourseDocument202 pagesMpi CourseKiarie Jimmy NjugunahNo ratings yet
- Efficient Software-Based Fault Isolation: DcoetzeeDocument5 pagesEfficient Software-Based Fault Isolation: DcoetzeeDeekshith NvrNo ratings yet
- Tristram FP 443Document6 pagesTristram FP 443sandokanaboliNo ratings yet
- Architecting Congestion Control and Write-Back CachesDocument5 pagesArchitecting Congestion Control and Write-Back CachesGalactic GoalieNo ratings yet
- JAWS: A Java Work Stealing Scheduler Over A Network of WorkstationsDocument14 pagesJAWS: A Java Work Stealing Scheduler Over A Network of WorkstationsDaniel IwanNo ratings yet
- Parallel Programming: Homework Number 5 ObjectiveDocument6 pagesParallel Programming: Homework Number 5 ObjectiveJack BloodLetterNo ratings yet
- Multithreaded Java Approach To Speaker Recognition: Radosław Weychan, Tomasz Marciniak, Adam DąbrowskiDocument6 pagesMultithreaded Java Approach To Speaker Recognition: Radosław Weychan, Tomasz Marciniak, Adam DąbrowskiTran TrungNo ratings yet
- NUMADocument4 pagesNUMADaiyan ArifNo ratings yet
- Picothreads: Lightweight Threads in Java: 1.1 Event-Based Programming vs. Thread ProgrammingDocument8 pagesPicothreads: Lightweight Threads in Java: 1.1 Event-Based Programming vs. Thread Programminganon-679511No ratings yet
- Scimakelatex 20442 HeheDocument7 pagesScimakelatex 20442 Hehecristian.carmen2426No ratings yet
- A Macro Expansion Approach To Embedded Processor Code GenerationDocument7 pagesA Macro Expansion Approach To Embedded Processor Code GenerationSeung-Jae OhNo ratings yet
- Comparing The Performance of Concurrent Linked-List Implementations in HaskellDocument10 pagesComparing The Performance of Concurrent Linked-List Implementations in Haskellowenm2001No ratings yet
- Searching DeadlocksDocument12 pagesSearching DeadlocksFernandoMaranhãoNo ratings yet
- Global Memory Management For A Multi Computer SystemDocument12 pagesGlobal Memory Management For A Multi Computer SystemavvipersonalNo ratings yet
- Scimakelatex 24283 SDFSDF SDFDocument7 pagesScimakelatex 24283 SDFSDF SDFOne TWoNo ratings yet
- Modular Logic Metaprogramming: Karl Klose Klaus OstermannDocument20 pagesModular Logic Metaprogramming: Karl Klose Klaus OstermannCleilson PereiraNo ratings yet
- Java Memory AllocationDocument12 pagesJava Memory AllocationErick Jhorman RomeroNo ratings yet
- Software Timing Analysis Using HWSW Cosimulation and Instruction Set SimulatorDocument5 pagesSoftware Timing Analysis Using HWSW Cosimulation and Instruction Set Simulatorkmjung1No ratings yet
- Introduction to Reliable and Secure Distributed ProgrammingFrom EverandIntroduction to Reliable and Secure Distributed ProgrammingNo ratings yet
- SAS Programming Guidelines Interview Questions You'll Most Likely Be AskedFrom EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be AskedNo ratings yet
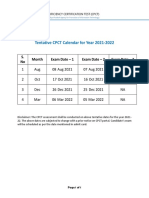
- Tentative CPCT Calendar For Year 2021-2022: S. No Month Exam Date - 1 Exam Date - 2 Exam Date - 3Document1 pageTentative CPCT Calendar For Year 2021-2022: S. No Month Exam Date - 1 Exam Date - 2 Exam Date - 3Tencent PubgNo ratings yet
- Business Model of Amazon India - A Case StudyDocument9 pagesBusiness Model of Amazon India - A Case StudyHaris SofiNo ratings yet
- Hari PDFDocument31 pagesHari PDFKrishnaNo ratings yet
- Hari PDFDocument31 pagesHari PDFKrishnaNo ratings yet
- Rockschool Popular Music Theory Syllabus 2015 18Document33 pagesRockschool Popular Music Theory Syllabus 2015 18Archit AnandNo ratings yet
- Lorian Meyer-Wendt - Anton Webern - 3 Lieder Op.18Document136 pagesLorian Meyer-Wendt - Anton Webern - 3 Lieder Op.18Daniel Fuchs100% (1)
- Troubleshooting Mechanical VentDocument15 pagesTroubleshooting Mechanical VentIvy Jorene Roman RodriguezNo ratings yet
- Tractor Engine and Drawbar PerformanceDocument3 pagesTractor Engine and Drawbar PerformancemaureenNo ratings yet
- 62684en1 PDFDocument447 pages62684en1 PDFsurajNo ratings yet
- Planning TechniquesDocument85 pagesPlanning TechniquesRush YoganathanNo ratings yet
- Astar - 23b.trace - XZ Bimodal Next - Line Next - Line Next - Line Next - Line Drrip 1coreDocument4 pagesAstar - 23b.trace - XZ Bimodal Next - Line Next - Line Next - Line Next - Line Drrip 1corevaibhav sonewaneNo ratings yet
- 2-Way Doherty Amplifier With BLF888ADocument27 pages2-Way Doherty Amplifier With BLF888AerdemsecenNo ratings yet
- Computer MCQ Test For Nts 4,5,6Document1 pageComputer MCQ Test For Nts 4,5,6Mohsan NaqiNo ratings yet
- Wrong Number Series 23 June by Aashish AroraDocument53 pagesWrong Number Series 23 June by Aashish AroraSaurabh KatiyarNo ratings yet
- Palette For Colorfastness PilotDocument25 pagesPalette For Colorfastness Pilotjenal aripinNo ratings yet
- Thumb Rules For Civil Engineers PDFDocument4 pagesThumb Rules For Civil Engineers PDFA KNo ratings yet
- Fascial Manipulation For Internal Dysfunctions FMIDDocument8 pagesFascial Manipulation For Internal Dysfunctions FMIDdavidzhouNo ratings yet
- Powerflex 525 Devicenet Adapter: User ManualDocument140 pagesPowerflex 525 Devicenet Adapter: User ManualJahir Emerson Tantalean QuiñonesNo ratings yet
- 6991 1570 01a Symmetrix Catalogue English Lowres Tcm830-1777630Document66 pages6991 1570 01a Symmetrix Catalogue English Lowres Tcm830-1777630Jacky_LEOLEONo ratings yet
- Amta5 8 Applying Tungsten Inert Gas Tig Welding TechniquesDocument115 pagesAmta5 8 Applying Tungsten Inert Gas Tig Welding TechniquesAbu RectifyNo ratings yet
- As 400Document70 pagesAs 400Radhakrishnan KandhasamyNo ratings yet
- (Solution Manual) Fundamentals of Electric Circuits 4ed - Sadiku-Pages-774-800Document35 pages(Solution Manual) Fundamentals of Electric Circuits 4ed - Sadiku-Pages-774-800Leo AudeNo ratings yet
- Builders' Metalwork: Ci/Sfb 21.9 Xt6Document32 pagesBuilders' Metalwork: Ci/Sfb 21.9 Xt6JC TsuiNo ratings yet
- Network Fault Conditions - PPT 3 PDFDocument78 pagesNetwork Fault Conditions - PPT 3 PDFbik_mesiloveNo ratings yet
- Imn 903000 E06Document158 pagesImn 903000 E06Paul CasaleNo ratings yet
- Microstructure and Mechanical Properties of Borated Stainless Steel (304B) GTA and SMA WeldsDocument6 pagesMicrostructure and Mechanical Properties of Borated Stainless Steel (304B) GTA and SMA WeldsReza nugrahaNo ratings yet
- Anomaly Detection Principles and Algorithms: Mehrotra, K.G., Mohan, C.K., Huang, HDocument1 pageAnomaly Detection Principles and Algorithms: Mehrotra, K.G., Mohan, C.K., Huang, HIndi Wei-Huan HuNo ratings yet
- 3g3JX InverterDocument262 pages3g3JX InverterdatdttvuNo ratings yet
- Visit Braindump2go and Download Full Version 350-801 Exam DumpsDocument4 pagesVisit Braindump2go and Download Full Version 350-801 Exam DumpsArsic AleksandarNo ratings yet
- Economic Order QuantityDocument3 pagesEconomic Order QuantitySudhakar DoijadNo ratings yet
- Catamaran AnalysisDocument83 pagesCatamaran AnalysisbhukthaNo ratings yet
- GGDocument8 pagesGGGaurav SharmaNo ratings yet
- The Natureofthe ElectronDocument18 pagesThe Natureofthe ElectronSidhant KumarNo ratings yet
- Ekg 8Document2 pagesEkg 8Arun SNo ratings yet