You might also like
- AWS Certified Cloud Practitioner - Practice Paper 3: AWS Certified Cloud Practitioner, #3From EverandAWS Certified Cloud Practitioner - Practice Paper 3: AWS Certified Cloud Practitioner, #3Rating: 5 out of 5 stars5/5 (1)
- Cost Optimize in Could ComputingDocument4 pagesCost Optimize in Could Computingpaid workNo ratings yet
- CloudonomicsDocument11 pagesCloudonomicsRojaNo ratings yet
- Week 5 - WatermarkDocument63 pagesWeek 5 - Watermarkshailesh karthikNo ratings yet
- Cost-Aware Cloud Storage Service Allocation For Distributed Data GatheringDocument5 pagesCost-Aware Cloud Storage Service Allocation For Distributed Data GatheringCatalin NegruNo ratings yet
- Monetary Cost Optimizations For Hosting Workflow-As-A-Service in Iaas CloudsDocument15 pagesMonetary Cost Optimizations For Hosting Workflow-As-A-Service in Iaas CloudsSelvaNo ratings yet
- Ijcet: International Journal of Computer Engineering & Technology (Ijcet)Document5 pagesIjcet: International Journal of Computer Engineering & Technology (Ijcet)IAEME PublicationNo ratings yet
- Efficient Fault Tolerant Cost Optimized Approach For Scientific Workflow Via Optimal Replication Technique Within Cloud Computing EcosystemDocument11 pagesEfficient Fault Tolerant Cost Optimized Approach For Scientific Workflow Via Optimal Replication Technique Within Cloud Computing EcosystemIAES IJAINo ratings yet
- Big Data Solutions for Practice Exercises of Chapter 10Document4 pagesBig Data Solutions for Practice Exercises of Chapter 10NUBG Gamer0% (1)
- Training Deep Autoencoders For Collaborative Filtering: Oleksii Kuchaiev Boris GinsburgDocument5 pagesTraining Deep Autoencoders For Collaborative Filtering: Oleksii Kuchaiev Boris GinsburgĐứcĐiệuNo ratings yet
- Uploading and Replicating Internet of Things (Iot) Data On Distributed Cloud StorageDocument9 pagesUploading and Replicating Internet of Things (Iot) Data On Distributed Cloud StorageKartika SariNo ratings yet
- Cloud Computing Task Scheduling Policy Based On Improved Particle Swarm OptimizationDocument3 pagesCloud Computing Task Scheduling Policy Based On Improved Particle Swarm Optimizationu chaitanyaNo ratings yet
- An Optimal Cloud Resource Provisioning (OCRP) Algorithm On-Demand and Reservation PlansDocument5 pagesAn Optimal Cloud Resource Provisioning (OCRP) Algorithm On-Demand and Reservation PlansIJRASETPublicationsNo ratings yet
- Evolving Heuristics For Dynamic Vehicle Routing With Time Windows Using Genetic ProgrammingDocument8 pagesEvolving Heuristics For Dynamic Vehicle Routing With Time Windows Using Genetic ProgrammingKasuri AbilashiniNo ratings yet
- Storage For RHOS and Cloud Paks Portfolio Seller Presentation - 2021-Oct-06Document28 pagesStorage For RHOS and Cloud Paks Portfolio Seller Presentation - 2021-Oct-06Elvis Frank Camacho VillegasNo ratings yet
- Li 2016Document7 pagesLi 2016Raj VJNo ratings yet
- Multi-Objective Particle Swarm Optimization For Resource Allocation in Cloud ComputingDocument5 pagesMulti-Objective Particle Swarm Optimization For Resource Allocation in Cloud ComputingcapodelcapoNo ratings yet
- Task Scheduling Based On Cost and Execution Time Using Ameliorate Grey Wolf Optimizer Algorithm in Cloud ComputingDocument11 pagesTask Scheduling Based On Cost and Execution Time Using Ameliorate Grey Wolf Optimizer Algorithm in Cloud ComputingAli Asghar Pourhaji KazemNo ratings yet
- 2017 ICCV Hsieh Drone-Based Object CountingDocument9 pages2017 ICCV Hsieh Drone-Based Object CountingdakshNo ratings yet
- A Study of Task Scheduling Based On Differential Evolution Algorithm in Cloud ComputingDocument4 pagesA Study of Task Scheduling Based On Differential Evolution Algorithm in Cloud Computingu chaitanyaNo ratings yet
- Realistic and Safe Outsourcing of Linear Programming in Cloud ComputingDocument3 pagesRealistic and Safe Outsourcing of Linear Programming in Cloud ComputingerpublicationNo ratings yet
- 1 s2.0 S1319157818304270 MainDocument13 pages1 s2.0 S1319157818304270 MainFiliphos EyoelNo ratings yet
- A Deep Reinforcement Learning-Based Offloading Scheme For Multi-Access Edge Computing-Supported Extended Reality SystemsDocument11 pagesA Deep Reinforcement Learning-Based Offloading Scheme For Multi-Access Edge Computing-Supported Extended Reality SystemsMikassa AckrNo ratings yet
- A Minimum-Cost Flow Model For Workload Optimization On Cloud InfrastructureDocument8 pagesA Minimum-Cost Flow Model For Workload Optimization On Cloud InfrastructureakshatNo ratings yet
- DeepEdge A New QoE-Based Resource Allocation Framework Using Deep Reinforcement Learning For Future Heterogeneous Edge-IoT ApplicationsDocument13 pagesDeepEdge A New QoE-Based Resource Allocation Framework Using Deep Reinforcement Learning For Future Heterogeneous Edge-IoT Applicationsbondgg537No ratings yet
- Caching Strategies and Economic Optimization in Mobile NetworkDocument6 pagesCaching Strategies and Economic Optimization in Mobile NetworkEmmanuel TonyeNo ratings yet
- REPEAT 1 Better, Faster, Cheaper Compute Cost-Optimizing Amazon EC2 CMP202-R1Document54 pagesREPEAT 1 Better, Faster, Cheaper Compute Cost-Optimizing Amazon EC2 CMP202-R1Rajeev JhaNo ratings yet
- Composable Cost Estimation and Monitoring For CompDocument11 pagesComposable Cost Estimation and Monitoring For CompTech FlixNo ratings yet
- Storage For RHOS and Cloud Paks Portfolio Seller PresenDocument25 pagesStorage For RHOS and Cloud Paks Portfolio Seller PresenElisa GarciaRNo ratings yet
- Cloud AnekaDocument34 pagesCloud Anekatieungunhi139No ratings yet
- High Availability in DHTS: Erasure Coding vs. Replication: Rodrigo Rodrigues and Barbara Liskov MitDocument6 pagesHigh Availability in DHTS: Erasure Coding vs. Replication: Rodrigo Rodrigues and Barbara Liskov MitNghĩa ZerNo ratings yet
- Cost Optimization For Dynamic Replication and Migration of Data in Cloud Data CentersDocument14 pagesCost Optimization For Dynamic Replication and Migration of Data in Cloud Data CentersPallaviRanaNo ratings yet
- Interactive Inspection of Complex Multi-Object Industrial AssembliesDocument17 pagesInteractive Inspection of Complex Multi-Object Industrial AssembliesRares BentaNo ratings yet
- Yodea PaperDocument5 pagesYodea PaperMaria PilarNo ratings yet
- Profit MaximizationDocument3 pagesProfit MaximizationKumarecitNo ratings yet
- IJEAS0302018Document3 pagesIJEAS0302018erpublicationNo ratings yet
- AWS CCP Mockup Test 3Document62 pagesAWS CCP Mockup Test 3IrfanHikmawanIINo ratings yet
- Towards Dynamic On-Demand Fog Computing Formation Based On Containerization TechnologyDocument6 pagesTowards Dynamic On-Demand Fog Computing Formation Based On Containerization Technologyadithya adigaNo ratings yet
- The Firm S Cost Minimization ProblemDocument4 pagesThe Firm S Cost Minimization ProblemkevinNo ratings yet
- AWS Cloud Economics Journey - Introductory Guide 2019Document6 pagesAWS Cloud Economics Journey - Introductory Guide 2019Mihir Ranjan AcharyaNo ratings yet
- ConferenceDocument15 pagesConferenceHandyNo ratings yet
- Biran 2018Document7 pagesBiran 2018Ali Asghar Pourhaji KazemNo ratings yet
- Chapter 11Document22 pagesChapter 11PauloNo ratings yet
- (IJCST-V8I6P5) :dr. Isabella JonesDocument6 pages(IJCST-V8I6P5) :dr. Isabella JonesEighthSenseGroupNo ratings yet
- Benefits of AWS in Modern Cloud Over On-Premises MethodDocument9 pagesBenefits of AWS in Modern Cloud Over On-Premises MethodIJRASETPublicationsNo ratings yet
- Video-on-Demand Server Selection and PlacementDocument12 pagesVideo-on-Demand Server Selection and PlacementGangaNo ratings yet
- Large Scale Docking in The CloudDocument24 pagesLarge Scale Docking in The CloudAlobrixinvestigaçom InvestigaçomNo ratings yet
- Intelligent Workload Factoring For A Hybrid Cloud Computing ModelDocument9 pagesIntelligent Workload Factoring For A Hybrid Cloud Computing ModelrajeshdhevanNo ratings yet
- Cloud InfrastructureDocument45 pagesCloud InfrastructureSubhadip Das SarmaNo ratings yet
- Load Balancing of Tasks On Cloud Computing Using Time Complexity of Proposed AlgorithmDocument7 pagesLoad Balancing of Tasks On Cloud Computing Using Time Complexity of Proposed Algorithmvieira salvadorNo ratings yet
- 1 s2.0 S1877050910002449 MainDocument10 pages1 s2.0 S1877050910002449 MainTech FlixNo ratings yet
- AWS Knowledge BaseDocument12 pagesAWS Knowledge BaseadminNo ratings yet
- Ieee Argencon 2016 Paper 19Document7 pagesIeee Argencon 2016 Paper 19ademargcjuniorNo ratings yet
- Job PDFDocument6 pagesJob PDFaswigaNo ratings yet
- Cloud Task Scheduling Based On Ant Colony OptimizationDocument9 pagesCloud Task Scheduling Based On Ant Colony OptimizationShaswata BhuniaNo ratings yet
- Li Zhang Arm CloudDocument4 pagesLi Zhang Arm CloudBradu VNo ratings yet
- Cloud Computing - IT60020Document2 pagesCloud Computing - IT60020Arijit PanigrahyNo ratings yet
- Sciencedirect: Cluster Based Application Mapping Strategy For 2D NocDocument8 pagesSciencedirect: Cluster Based Application Mapping Strategy For 2D Nochema SreedharanNo ratings yet
- Xenapp On Oracle Cloud InfrastructureDocument24 pagesXenapp On Oracle Cloud InfrastructureSri KanthNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Information Theory (IJIT)Document1 pageInternational Journal On Information Theory (IJIT)ijitjournalNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- International Journal On Cloud Computing: Services and Architecture (IJCCSA)Document2 pagesInternational Journal On Cloud Computing: Services and Architecture (IJCCSA)Anonymous roqsSNZNo ratings yet
- Digital Banking - Architecture Strategies Using Cloud ComputingDocument10 pagesDigital Banking - Architecture Strategies Using Cloud ComputingAnonymous roqsSNZNo ratings yet
- Blockchain Based Data Security As A Service in Cloud Platform SecurityDocument8 pagesBlockchain Based Data Security As A Service in Cloud Platform SecurityAnonymous roqsSNZNo ratings yet
- Subjective QuestionsDocument8 pagesSubjective QuestionsKeerthan kNo ratings yet
- Acteduk Ct6 Hand Qho v04Document58 pagesActeduk Ct6 Hand Qho v04ankitag612No ratings yet
- hw4 SolDocument5 pageshw4 SolanthalyaNo ratings yet
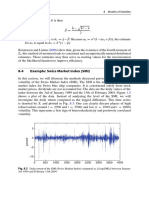
- 8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityDocument3 pages8.4 Example: Swiss Market Index (SMI) : 188 8 Models of VolatilityNickesh ShahNo ratings yet
- ECE 368 Review Part 1Document55 pagesECE 368 Review Part 1Jialun LyuNo ratings yet
- SHS Core - Statistics and Probability CGDocument11 pagesSHS Core - Statistics and Probability CGCarol Zamora100% (1)
- One Way DesignDocument104 pagesOne Way DesignUkhtie JulieNo ratings yet
- A Short Monograph On Analysis of Variance (ANOVA) : T R Pgp-DsbaDocument44 pagesA Short Monograph On Analysis of Variance (ANOVA) : T R Pgp-DsbarajatNo ratings yet
- Batc 602 and Itae007 AssignmentsDocument8 pagesBatc 602 and Itae007 AssignmentsInvictus IndiansNo ratings yet
- Sigmoid Function Definition - DeepAIDocument15 pagesSigmoid Function Definition - DeepAIsushilnamoijamNo ratings yet
- Understanding The Z - ScoreDocument63 pagesUnderstanding The Z - ScoreRossel Jane CampilloNo ratings yet
- Probability ExamplesDocument28 pagesProbability ExamplesasdaNo ratings yet
- NT Rand 2Document44 pagesNT Rand 2narelemilioNo ratings yet
- Research ProposalDocument15 pagesResearch ProposalYasantha ChanakaNo ratings yet
- John P. Nolan - Stable DistributionsDocument34 pagesJohn P. Nolan - Stable DistributionsDániel KincsesNo ratings yet
- Mai 4.11 Normal DistributionDocument16 pagesMai 4.11 Normal DistributionPravar TrivediNo ratings yet
- Eng ISM Chapter 7 Probability by Mandenhall SolutionDocument28 pagesEng ISM Chapter 7 Probability by Mandenhall SolutionUzair Khan100% (1)
- Alan Agresti, Christine A. Franklin, Bernhard Klingenberg-Statistics - The Art and Science of Learning From Data-Pearson (2017)Document10 pagesAlan Agresti, Christine A. Franklin, Bernhard Klingenberg-Statistics - The Art and Science of Learning From Data-Pearson (2017)luana testoniNo ratings yet
- STAT 251 Statistics Notes UBCDocument292 pagesSTAT 251 Statistics Notes UBChavarticanNo ratings yet
- Introducing Communication Research Paths of Inquiry 4Th Edition Full ChapterDocument41 pagesIntroducing Communication Research Paths of Inquiry 4Th Edition Full Chapterjames.popp962100% (23)
- Risk Assessment and Pooling - Book 2Document21 pagesRisk Assessment and Pooling - Book 2Ahmed El KhateebNo ratings yet
- WGN 8Document5 pagesWGN 8david joshua paraisoNo ratings yet
- Mass Volume CurveDocument29 pagesMass Volume CurveDeepakGujraniyaNo ratings yet
- AC and Lightning Breakdown Strength of Mineral Oil Nytro Gemini X and 10GBNDocument7 pagesAC and Lightning Breakdown Strength of Mineral Oil Nytro Gemini X and 10GBNJicheng PiaoNo ratings yet
- Business Statistics Assignment 4Document18 pagesBusiness Statistics Assignment 4Ujwal KhanapurkarNo ratings yet
- Data Screening AssumptionsDocument29 pagesData Screening Assumptionshina firdousNo ratings yet
- Strahler 1954Document25 pagesStrahler 1954Valter AlbinoNo ratings yet
- Why Distributions Matter (16 Jan 2012)Document43 pagesWhy Distributions Matter (16 Jan 2012)Peter UrbaniNo ratings yet
- Sample Mean DistributionDocument10 pagesSample Mean DistributionRyan ChungNo ratings yet
- 85th Precentile SpeedDocument12 pages85th Precentile SpeedRudi SuyonoNo ratings yet