You might also like
- m5 Daa TierDocument28 pagesm5 Daa TierShan MpNo ratings yet
- Module-5: BacktrackingDocument29 pagesModule-5: Backtrackingsunita chalageriNo ratings yet
- Daa Module 1Document30 pagesDaa Module 1Abhishek DubeyNo ratings yet
- DAA Module-5Document30 pagesDAA Module-5Zeha 1No ratings yet
- Daa m5 NotesDocument29 pagesDaa m5 NotesPrajwal OconnerNo ratings yet
- Design & Analysis of Algorithms (10Cs43) Unit-Vii: Coping With Limitations of Algorithmic Power BacktrackingDocument8 pagesDesign & Analysis of Algorithms (10Cs43) Unit-Vii: Coping With Limitations of Algorithmic Power BacktrackingShreyans SonthaliaNo ratings yet
- Lecture Notes On Design and Analysis of Algorithms 18CS42: Module-5: BacktrackingDocument29 pagesLecture Notes On Design and Analysis of Algorithms 18CS42: Module-5: BacktrackingBhanuranjan S BNo ratings yet
- 18CS42 - Module 5Document52 pages18CS42 - Module 5dreamforya03No ratings yet
- Unit 14 Coping With The Limitations of Algorithm Power: StructureDocument21 pagesUnit 14 Coping With The Limitations of Algorithm Power: StructureRaj SinghNo ratings yet
- Sleeping Barber ProblemDocument29 pagesSleeping Barber ProblemAbhay KumarNo ratings yet
- 20itt43 Daa Unit VDocument60 pages20itt43 Daa Unit Vrt.cseNo ratings yet
- Combinatorial Search: Li Yin March 29, 2020Document30 pagesCombinatorial Search: Li Yin March 29, 2020markNo ratings yet
- Branch and Bound Optimization AlgorithmDocument7 pagesBranch and Bound Optimization AlgorithmRidhima Amit KhamesraNo ratings yet
- What Is Difference Between Backtracking and Branch and Bound MethodDocument4 pagesWhat Is Difference Between Backtracking and Branch and Bound MethodMahi On D Rockzz67% (3)
- Assignment - 1 AIM: Implement A Approach For Any Suitable Application. ObjectiveDocument17 pagesAssignment - 1 AIM: Implement A Approach For Any Suitable Application. ObjectiveTECOA136TejasJadhavNo ratings yet
- DAA Unit 5Document14 pagesDAA Unit 5hari karanNo ratings yet
- Modul Iii Strategi Algoritma: TujuanDocument10 pagesModul Iii Strategi Algoritma: TujuanAndhika CiptaNo ratings yet
- Unit 5Document16 pagesUnit 5Nimmati Satheesh KannanNo ratings yet
- Module 5Document41 pagesModule 5cbgopinathNo ratings yet
- LinalgDocument12 pagesLinalgcuongptNo ratings yet
- Data Structures Unit VDocument31 pagesData Structures Unit VG KalaiarasiNo ratings yet
- What is an algorithm and why is it neededDocument6 pagesWhat is an algorithm and why is it neededabdullah Mamun KhanNo ratings yet
- How algorithms solve problems efficientlyDocument6 pagesHow algorithms solve problems efficientlyabdullah Mamun KhanNo ratings yet
- SE-Comps SEM4 AOA-CBCGS DEC19 SOLUTIONDocument19 pagesSE-Comps SEM4 AOA-CBCGS DEC19 SOLUTIONSagar SaklaniNo ratings yet
- Mcs 031 qns2 Image: Travelling Salesman Problem Previous PostDocument5 pagesMcs 031 qns2 Image: Travelling Salesman Problem Previous PostUmesh sharmaNo ratings yet
- Eight QueensDocument5 pagesEight QueensManjeet BhukalNo ratings yet
- Unit 3 Divide and Conquer: StructureDocument18 pagesUnit 3 Divide and Conquer: StructureJohn ArthurNo ratings yet
- DAA Monograph PDFDocument119 pagesDAA Monograph PDFjay SinghNo ratings yet
- Imp Notes For Final Term by Daniyal Subhani Cs502 Important Question With Answer PreparedDocument9 pagesImp Notes For Final Term by Daniyal Subhani Cs502 Important Question With Answer PreparedYasir WaseemNo ratings yet
- Department of Computer Science and EngineeringDocument10 pagesDepartment of Computer Science and EngineeringRamesh KumarNo ratings yet
- Daa CT2Document7 pagesDaa CT2shivam kacholeNo ratings yet
- Use of Recursion and DP in Board GamesDocument25 pagesUse of Recursion and DP in Board GamesRajneesh GoyalNo ratings yet
- ADA QB SolDocument13 pagesADA QB Solankitaarya1207No ratings yet
- Module-2:Divide and ConquerDocument26 pagesModule-2:Divide and ConquerSk ShettyNo ratings yet
- Solving Sudoku PuzzlesDocument17 pagesSolving Sudoku PuzzlesAyush BhatiaNo ratings yet
- Daa Aat2 PlagDocument5 pagesDaa Aat2 PlagNehanth AdmirerNo ratings yet
- Algorithms Lab GuideDocument62 pagesAlgorithms Lab GuideRajendraYalaburgiNo ratings yet
- Algo Prev Year Solution 2019 and 2018Document23 pagesAlgo Prev Year Solution 2019 and 2018Md. Abdur RoufNo ratings yet
- Daa Unit-IvDocument16 pagesDaa Unit-Ivsivakanthvaddi61No ratings yet
- Daa Module 6Document17 pagesDaa Module 6dunduNo ratings yet
- Aiml Case StudyDocument9 pagesAiml Case StudyAMAN PANDEYNo ratings yet
- Analysis of PuzzlesDocument46 pagesAnalysis of PuzzlesmuradNo ratings yet
- DSA 2016 T1 Solution: Optimal Pairing Sequence for Merge SortDocument3 pagesDSA 2016 T1 Solution: Optimal Pairing Sequence for Merge SortShreyas PatelNo ratings yet
- Case Study Aiml ReportDocument9 pagesCase Study Aiml ReportAMAN PANDEYNo ratings yet
- Non-Linear Recursive Backtracking: Li Yin April 5, 2019Document18 pagesNon-Linear Recursive Backtracking: Li Yin April 5, 2019markNo ratings yet
- Root-Locus Analysis of Delayed First and Second Order SystemsDocument8 pagesRoot-Locus Analysis of Delayed First and Second Order SystemsSanika TalathiNo ratings yet
- 8 Queens Problem AlgorithmDocument3 pages8 Queens Problem Algorithmroopashreemurugan7No ratings yet
- What Are Stacks and QueuesDocument13 pagesWhat Are Stacks and QueuesrizawanshaikhNo ratings yet
- CSC14003 - Introduction to AI Homework 02Document6 pagesCSC14003 - Introduction to AI Homework 02Nguyen HikariNo ratings yet
- Ku Assignment 4th Sem 41Document9 pagesKu Assignment 4th Sem 41Rachit KhandelwalNo ratings yet
- Basic Techniques For Design and Analysis of AlgorithmsDocument3 pagesBasic Techniques For Design and Analysis of AlgorithmsHernan SepulvedaNo ratings yet
- 1 Complexity and RecursionDocument6 pages1 Complexity and RecursionShuvadeep DasNo ratings yet
- Merge Sort: Divide and ConquerDocument18 pagesMerge Sort: Divide and ConquervinithNo ratings yet
- Unit Iv - DaaDocument100 pagesUnit Iv - DaaSaksham SahayNo ratings yet
- UNIT-2: Divide and ConquerDocument25 pagesUNIT-2: Divide and ConquerSathyendra Kumar VNo ratings yet
- MIT6 006F11 ps1Document6 pagesMIT6 006F11 ps1Ye QianNo ratings yet
- Problem Reduction: - AND-OR Graph - AO SearchDocument31 pagesProblem Reduction: - AND-OR Graph - AO Searchmiriyala nagendraNo ratings yet
- Assignment - 3 SolutionDocument28 pagesAssignment - 3 SolutionRitesh SutraveNo ratings yet
- Java Programming For BSC It 4th Sem Kuvempu UniversityDocument52 pagesJava Programming For BSC It 4th Sem Kuvempu UniversityUsha Shaw100% (1)
- Chapter-14 Final Aerobic-DigestionDocument18 pagesChapter-14 Final Aerobic-DigestionIrvin joseNo ratings yet
- 1 Gravity IntroductionDocument13 pages1 Gravity IntroductionPerry SegereNo ratings yet
- Purchase Specification FOR 1250A, 1000V, DC CONTACTOR FOR Oil Rig ApplicationDocument5 pagesPurchase Specification FOR 1250A, 1000V, DC CONTACTOR FOR Oil Rig ApplicationAhmed ShaabanNo ratings yet
- Circuit Cellar 354 2020-01Document84 pagesCircuit Cellar 354 2020-01romanNo ratings yet
- GCE Examinations Mechanics Module M1 Paper K MARKING GUIDEDocument4 pagesGCE Examinations Mechanics Module M1 Paper K MARKING GUIDEAbhiKhanNo ratings yet
- Intraoral ProjectionsDocument73 pagesIntraoral ProjectionsrespikNo ratings yet
- Marine Engine-6170 Series: General SpecificationsDocument3 pagesMarine Engine-6170 Series: General SpecificationsTrần Hoài VinhNo ratings yet
- Definitions: - : I) Soft PalateDocument30 pagesDefinitions: - : I) Soft PalateNikita AggarwalNo ratings yet
- MagnusDocument26 pagesMagnussvsreeramaNo ratings yet
- Viva QuestionsDocument8 pagesViva QuestionsPrabinjose100% (1)
- Samsung CAC Duct S Brochure 20140729 0Document16 pagesSamsung CAC Duct S Brochure 20140729 0Callany AnycallNo ratings yet
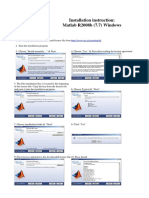
- Matlab R2008b-Installation InstructionDocument2 pagesMatlab R2008b-Installation InstructionDicky Chandra SuryaNo ratings yet
- Ladd CC 1964 - Stress-Strain Behavior of Saturated Clay and Basic Strength Principles PDFDocument125 pagesLadd CC 1964 - Stress-Strain Behavior of Saturated Clay and Basic Strength Principles PDFSaraswati NoorNo ratings yet
- JBM Report (20331) MEDocument30 pagesJBM Report (20331) MEKshitijKumarNo ratings yet
- (BPL12-12FR) : VRLA Rechargeable BatteryDocument1 page(BPL12-12FR) : VRLA Rechargeable BatteryAlexander PischulinNo ratings yet
- Passive DesignDocument97 pagesPassive DesignOreo De VeraNo ratings yet
- IIT-JEE - 2020 - 2021: BY Referral CodeDocument31 pagesIIT-JEE - 2020 - 2021: BY Referral CodeBishwadeep RoyNo ratings yet
- Android KMSGDocument62 pagesAndroid KMSGraimanalmughnii67No ratings yet
- Si924x - Class D Audio Driver With Precision Dead-Time GeneratorDocument1 pageSi924x - Class D Audio Driver With Precision Dead-Time GeneratorBen M'rad SkanderNo ratings yet
- Non-Thermal Plasma Pyrolysis of Organic WasteDocument14 pagesNon-Thermal Plasma Pyrolysis of Organic WasteMai OsamaNo ratings yet
- Map Grid and Compass RoseDocument3 pagesMap Grid and Compass RosePatricia BelangerNo ratings yet
- Manual Aid 2Document136 pagesManual Aid 2Luis Chinchilla CruzNo ratings yet
- Multi-Hole Orifice CalculationDocument10 pagesMulti-Hole Orifice Calculationadrianrrcc100% (1)
- (Catalog Reciprocating Engine) WÄRTSILÄ Brochure-O-E-W31Document7 pages(Catalog Reciprocating Engine) WÄRTSILÄ Brochure-O-E-W31ppourmoghaddamNo ratings yet
- Hard Gelatin CapsulesDocument58 pagesHard Gelatin Capsulesas.jessy0608No ratings yet
- Structural beam drawingsDocument1 pageStructural beam drawingsnathan kNo ratings yet
- Royal College Grade 08 Geography First Term Paper English MediumDocument7 pagesRoyal College Grade 08 Geography First Term Paper English MediumNimali Dias67% (3)
- Grade: Third Grade Unit Title: Matter Course/Subject: Science Approximate Time Required: 1 WeekDocument6 pagesGrade: Third Grade Unit Title: Matter Course/Subject: Science Approximate Time Required: 1 Weekapi-272854858No ratings yet
- Checklist On Continuous Ambulatory Peritoneal Dialysis (Capd)Document3 pagesChecklist On Continuous Ambulatory Peritoneal Dialysis (Capd)Sheryl Ann Barit PedinesNo ratings yet