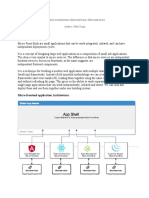
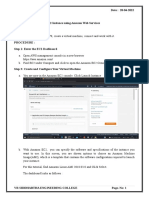
You might also like
- The Cloud Resume Challenge BookDocument135 pagesThe Cloud Resume Challenge BookMichael Critcher100% (3)
- AWS Academy Cloud Architecting Module 09 Student Guide: 200-ACACAD-20-EN-SGDocument87 pagesAWS Academy Cloud Architecting Module 09 Student Guide: 200-ACACAD-20-EN-SGM Rizki AsriyandaNo ratings yet
- Architecting A Website Using The Serverless TechnologyDocument21 pagesArchitecting A Website Using The Serverless Technologydheeraj patilNo ratings yet
- Whitepaper Micro Frontend PDFDocument6 pagesWhitepaper Micro Frontend PDFAayush TripathiNo ratings yet
- Heli Bhavsar: EducationDocument2 pagesHeli Bhavsar: EducationKV AcharyaNo ratings yet
- Glue DGDocument1,032 pagesGlue DGAnil ReddyNo ratings yet
- (Dec-2020) AWS Certified Solutions Architect - Professional (SAP-C01) Exam DumpsDocument12 pages(Dec-2020) AWS Certified Solutions Architect - Professional (SAP-C01) Exam DumpsAishu NaiduNo ratings yet
- 3 Maarek TestDocument106 pages3 Maarek TestAkash PaulNo ratings yet
- AWS Interview QuestionsDocument31 pagesAWS Interview QuestionsAditya Bhuyan60% (5)
- Sureshraja Kolisetti: Profile SummaryDocument4 pagesSureshraja Kolisetti: Profile SummaryNitin SinghNo ratings yet
- REPEAT 1 Modernizing Microsoft SQL Server On AWS WIN301-R1Document54 pagesREPEAT 1 Modernizing Microsoft SQL Server On AWS WIN301-R1Rajeev JhaNo ratings yet
- Subject: Cloud Web Services: Module Name: Introduction To EC2Document135 pagesSubject: Cloud Web Services: Module Name: Introduction To EC2Buffalo GamingNo ratings yet
- File Storage Services: David TuckerDocument36 pagesFile Storage Services: David TuckerBao LeNo ratings yet
- E BookDocument231 pagesE BookAnonymous HPXJ6ONo ratings yet
- Web On Reactive Stack SpringDocument92 pagesWeb On Reactive Stack SpringJose Miguel Romero SevillaNo ratings yet
- Cloud ComputingDocument44 pagesCloud ComputingSmita KondaNo ratings yet
- Web ReactiveDocument175 pagesWeb Reactivemani kanta swamyNo ratings yet
- Webtestclient: Version 5.2.6.releaseDocument11 pagesWebtestclient: Version 5.2.6.releaseRaul Andrés Alzate GómezNo ratings yet
- 2.1 HCC-AWS-Lab-1024 PDFDocument2 pages2.1 HCC-AWS-Lab-1024 PDFRaphael GalvaoNo ratings yet
- Maven2 Quick ReferenceDocument4 pagesMaven2 Quick Referencenathandelane5347No ratings yet
- Angular 7 Boilerplate TutorialDocument14 pagesAngular 7 Boilerplate TutorialDheeraj Bharat Sethi50% (2)
- Cloud Infrastructure Services (CIS) Course Outcome (CO) 2: (Session 7)Document31 pagesCloud Infrastructure Services (CIS) Course Outcome (CO) 2: (Session 7)srinivas tikkanaNo ratings yet
- Anotation in JavaDocument5 pagesAnotation in JavaagnyaaathavaasiNo ratings yet
- Webflux - A Practical Guide To Reactive ApplicationsDocument189 pagesWebflux - A Practical Guide To Reactive ApplicationsCH LEENo ratings yet
- Reactive SpringDocument101 pagesReactive SpringSunjay BhallaNo ratings yet
- What Is Actually A Design Document!Document18 pagesWhat Is Actually A Design Document!Seg InfNo ratings yet
- Java 8 Streams Cheat SheetDocument1 pageJava 8 Streams Cheat Sheetrahul kumarNo ratings yet
- Freelance Contract Template 33Document4 pagesFreelance Contract Template 33RismaNo ratings yet
- SAAC03-Services SummaryDocument8 pagesSAAC03-Services Summaryjoseluis.vihuNo ratings yet
- Angular QuestionsDocument14 pagesAngular QuestionsMahesh Reddy sayamollaNo ratings yet
- Prince2® Foundation and PractitionerDocument11 pagesPrince2® Foundation and PractitionerGayarthri JNo ratings yet
- C& DS Lab ManualDocument181 pagesC& DS Lab ManualNaresh IcefireNo ratings yet
- Content: Chapter I Java Programming Language, Sqlite and Android Studio .3Document36 pagesContent: Chapter I Java Programming Language, Sqlite and Android Studio .3Жасур АшырбаевNo ratings yet
- Management and Governance Services SlidesDocument36 pagesManagement and Governance Services SlidesP. ShinyNo ratings yet
- Stream APIDocument4 pagesStream APINIKHIL B SNo ratings yet
- 2020 AWS Ramp Up Guide DeveloperDocument20 pages2020 AWS Ramp Up Guide DeveloperWay DevNo ratings yet
- Testing WebtestclientDocument7 pagesTesting WebtestclientAkarsh LNo ratings yet
- Angular 13 - 40 HDocument5 pagesAngular 13 - 40 HyogNo ratings yet
- 01 Spring Boot OverviewDocument166 pages01 Spring Boot OverviewChotuNo ratings yet
- Spring MVC: Bharat Singh 27-May-2019Document51 pagesSpring MVC: Bharat Singh 27-May-2019Anonymous oXo00b7KyNo ratings yet
- Hibernate Interview Questions: Click HereDocument38 pagesHibernate Interview Questions: Click HereMdNo ratings yet
- Containers and MicroservicesDocument20 pagesContainers and MicroservicesLamis AhmadNo ratings yet
- Amazon Web ServicesDocument82 pagesAmazon Web ServicesRocket BunnyNo ratings yet
- AWS CloudNotesDocument8 pagesAWS CloudNotesmeggem6No ratings yet
- Spring LiveDocument353 pagesSpring Liveapi-3704669100% (1)
- FREE AWS Solution Architect Sample Exam Questions Ed1Document44 pagesFREE AWS Solution Architect Sample Exam Questions Ed1Osu GodblessNo ratings yet
- Lab-6 Ec2 InstanceDocument11 pagesLab-6 Ec2 InstanceEswarchandra PinjalaNo ratings yet
- Hibernate Tutorial - OdtDocument75 pagesHibernate Tutorial - OdtboyongNo ratings yet
- Spring Boot AnnotationsDocument12 pagesSpring Boot AnnotationsMedNejjarNo ratings yet
- Spring Web-ReactiveDocument179 pagesSpring Web-ReactiveCiprian Nicu RosuNo ratings yet
- Core Spring 3.1.2.RELEASE Student HandoutDocument830 pagesCore Spring 3.1.2.RELEASE Student HandoutNaoufel AbbassiNo ratings yet
- Top Cloud Service Providers - A Quick Comparison - AvengaDocument25 pagesTop Cloud Service Providers - A Quick Comparison - AvengaPerry DooNo ratings yet
- Experience: DEVOPS ENGINEER, Wipro Technologies (Pune)Document2 pagesExperience: DEVOPS ENGINEER, Wipro Technologies (Pune)Rishabh PareekNo ratings yet
- Design Patterns in JavaDocument5 pagesDesign Patterns in JavaBhavesh KNo ratings yet
- Angualr5 Interview QuestionsDocument15 pagesAngualr5 Interview Questionsking4u9No ratings yet
- Kubernetes ATC Kube Ebook-Final Feb 2020 PDFDocument11 pagesKubernetes ATC Kube Ebook-Final Feb 2020 PDFnicolepetrescuNo ratings yet
- Better Apps Angular 2 Day1Document125 pagesBetter Apps Angular 2 Day1abhishekdubey2011No ratings yet
- Angular 01052023Document62 pagesAngular 01052023Y20CS113 MANOJ KUMAR CHATTINo ratings yet
- JUnit 5 Migration GuideDocument31 pagesJUnit 5 Migration Guidemichele.b26No ratings yet
- Event Processing for Business: Organizing the Real-Time EnterpriseFrom EverandEvent Processing for Business: Organizing the Real-Time EnterpriseNo ratings yet
- Introducing Maven: A Build Tool for Today's Java DevelopersFrom EverandIntroducing Maven: A Build Tool for Today's Java DevelopersNo ratings yet
- Cloud: Get All The Support And Guidance You Need To Be A Success At Using The CLOUDFrom EverandCloud: Get All The Support And Guidance You Need To Be A Success At Using The CLOUDNo ratings yet
- Implementing OAuth 2.0 With AWS API Gateway, Lambda, DynamoDB, and KMS - Part 2 - by Bilal Ashfaq - MediumDocument34 pagesImplementing OAuth 2.0 With AWS API Gateway, Lambda, DynamoDB, and KMS - Part 2 - by Bilal Ashfaq - MediumProf SilvaNo ratings yet
- AWS Scenario BasedDocument16 pagesAWS Scenario BasedShivNo ratings yet
- Python Essentials For AWS Cloud Developers Run and Deploy Cloud-Based Python Applications Using AWS PDFDocument224 pagesPython Essentials For AWS Cloud Developers Run and Deploy Cloud-Based Python Applications Using AWS PDFGéza NagyNo ratings yet
- Lambda DG PDFDocument544 pagesLambda DG PDFViren PatelNo ratings yet
- Developing On AwsDocument7 pagesDeveloping On Awsalton032No ratings yet
- Tutorials Dojo Study Guide AWS Certified Developer Associate 2023-03-21 OzqpcjDocument211 pagesTutorials Dojo Study Guide AWS Certified Developer Associate 2023-03-21 OzqpcjMichael AngeloNo ratings yet
- AWS Certified DevOps Engineer - Professional Certification and Beyond - Autor (Adam Book)Document638 pagesAWS Certified DevOps Engineer - Professional Certification and Beyond - Autor (Adam Book)O Espetacular Marquês AranhaNo ratings yet
- Aws TestDocument123 pagesAws TestSATYA NARAYAN DASNo ratings yet
- Click To Edit Master Title Style AWS Certified Solutions Architect Crash Course V2Document136 pagesClick To Edit Master Title Style AWS Certified Solutions Architect Crash Course V2yugandhar_ch100% (2)
- Video On Demand On Aws PDFDocument21 pagesVideo On Demand On Aws PDFshreyasNo ratings yet
- Arch Dump May23Document207 pagesArch Dump May23Xiaotian ChengNo ratings yet
- Aws Interview QuestionsDocument49 pagesAws Interview Questionsyuva razNo ratings yet
- Amazon Web Services Bootcamp 1788294459Document330 pagesAmazon Web Services Bootcamp 1788294459He Jasper100% (1)
- Aws Certified Cloud Practitioner CLF c02 0e73050f7ab8Document37 pagesAws Certified Cloud Practitioner CLF c02 0e73050f7ab8plagarNo ratings yet
- AWS Serverless Applications LensDocument82 pagesAWS Serverless Applications LensArun UpadhyayNo ratings yet
- Aws Cloudendure Migration Factory Solution: Implementation GuideDocument54 pagesAws Cloudendure Migration Factory Solution: Implementation GuideJohnsanjay kNo ratings yet
- Roger Manzo Back EndDocument1 pageRoger Manzo Back EndRoger ManzoNo ratings yet
- AWS - Kinesis QuizletDocument15 pagesAWS - Kinesis QuizletchandraNo ratings yet
- AWS Certified Solutions Architect Associate SAA C02 DemoDocument12 pagesAWS Certified Solutions Architect Associate SAA C02 DemocprathapmmNo ratings yet
- G7 Amazon DynamoDBDocument22 pagesG7 Amazon DynamoDBRAGUPATHI MNo ratings yet
- Exam Prep For AWS Certified Solutions Architect - Associate: Domain 1 - Organizational ComplexityDocument3 pagesExam Prep For AWS Certified Solutions Architect - Associate: Domain 1 - Organizational ComplexityJohann LeeNo ratings yet
- AWS Solutions Architect Associate (SAA-C01) Sample Exam QuestionsDocument4 pagesAWS Solutions Architect Associate (SAA-C01) Sample Exam QuestionsRajendraNo ratings yet