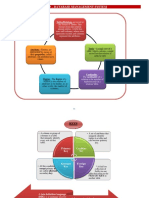
You might also like
- Oracle WorkflowDocument56 pagesOracle WorkflowladabalaNo ratings yet
- Perl 0411 PDFDocument124 pagesPerl 0411 PDFGobara Dhan100% (1)
- Introduction To PerlDocument62 pagesIntroduction To PerlParimal Dave100% (1)
- Scripting Languages Advanced Perl: Course: 67557 Hebrew University Lecturer: Elliot Jaffe - הפי טוילאDocument44 pagesScripting Languages Advanced Perl: Course: 67557 Hebrew University Lecturer: Elliot Jaffe - הפי טוילאvcosmin100% (1)
- Pandas: Reference SheetDocument9 pagesPandas: Reference SheetdeveshagNo ratings yet
- CodeJam Exercise 3 CDSDocument34 pagesCodeJam Exercise 3 CDSGurushantha DoddamaniNo ratings yet
- EDA Cheat Sheet - Exploratory Data AnalysisDocument2 pagesEDA Cheat Sheet - Exploratory Data AnalysisVanshika RastogiNo ratings yet
- 1 SQRDocument31 pages1 SQRYashwanthNo ratings yet
- DatavischeatsheetDocument2 pagesDatavischeatsheetrcg97.hdNo ratings yet
- Chapter 4 Arrays in PHPDocument26 pagesChapter 4 Arrays in PHPmohamedabdulkadir767No ratings yet
- Unit 4 - Session 6Document33 pagesUnit 4 - Session 6Mahek Agarwal (RA1911003010893)No ratings yet
- Practical Extraction and Reporting LanguageDocument45 pagesPractical Extraction and Reporting LanguageitanilmitsNo ratings yet
- Python-for-Data-Analysis (PandasDocument31 pagesPython-for-Data-Analysis (PandasNaman JainNo ratings yet
- R BasicDocument16 pagesR BasicTaslima ChowdhuryNo ratings yet
- SQL NotesDocument24 pagesSQL NotesTheMemes GuyNo ratings yet
- Chapter 4 Arrays in PHP-1Document21 pagesChapter 4 Arrays in PHP-1AbdallaNo ratings yet
- Clustsig RDocument7 pagesClustsig RSeverodvinsk MasterskayaNo ratings yet
- Data Manipulation Using R: Acm Datascience CampDocument35 pagesData Manipulation Using R: Acm Datascience CampAnurag SharmaNo ratings yet
- Database Management SystemDocument9 pagesDatabase Management SystemDivyanshu YadavNo ratings yet
- Python For Data Science Nympy and PandasDocument4 pagesPython For Data Science Nympy and PandasStocknEarnNo ratings yet
- PerlDocument62 pagesPerlvivek_121079No ratings yet
- PYTHON PANDAS Cheat SheetDocument2 pagesPYTHON PANDAS Cheat SheetIndri Dayanah AyulaniNo ratings yet
- Data Definition Language: Module of InstructionDocument14 pagesData Definition Language: Module of Instructionchobiipiggy26No ratings yet
- Machine Learning Lab: Delhi Technological UniversityDocument6 pagesMachine Learning Lab: Delhi Technological UniversityHimanshu SinghNo ratings yet
- Commands SQL, Python (BASICS)Document7 pagesCommands SQL, Python (BASICS)Kuldeep GangwarNo ratings yet
- 3Y3Z2Xzqn7 U Y%K : 2. How To Create A Data Frame Using A Dictionary of Pre-Existing Columns or Numpy 2D Arrays?Document8 pages3Y3Z2Xzqn7 U Y%K : 2. How To Create A Data Frame Using A Dictionary of Pre-Existing Columns or Numpy 2D Arrays?Sudan PudasainiNo ratings yet
- Chap2 P3Document36 pagesChap2 P3HO KUN HANNo ratings yet
- Arrays and Do LoopsDocument18 pagesArrays and Do LoopsMpho SeutloaliNo ratings yet
- CS50 2023 NotesDocument26 pagesCS50 2023 Notesjohnappleseed4lifeNo ratings yet
- Unit 3 - Database Management System: Tables/Relations Are Saved inDocument15 pagesUnit 3 - Database Management System: Tables/Relations Are Saved inriyaNo ratings yet
- Very Short Answer Type Q-1Document1 pageVery Short Answer Type Q-1B9B25No ratings yet
- Content Pandas Cheat SheetDocument9 pagesContent Pandas Cheat SheetTurya GangulyNo ratings yet
- COMFUN2 Chapter 11 12Document4 pagesCOMFUN2 Chapter 11 12Jd AzadaNo ratings yet
- PHP - Variable TypesDocument6 pagesPHP - Variable TypesFetsum LakewNo ratings yet
- PandasDocument41 pagesPandasSivam ChinnaNo ratings yet
- 03 - Introduction To Pandas 6Document1 page03 - Introduction To Pandas 6Kabir WestNo ratings yet
- Exploratory Data Analysis and Graphics: Lab 2Document19 pagesExploratory Data Analysis and Graphics: Lab 2juntujuntuNo ratings yet
- Array in PHP: Course: Z1167 Advanced in Web Based Application Development Year: 2019Document26 pagesArray in PHP: Course: Z1167 Advanced in Web Based Application Development Year: 2019Adrian TanuwijayaNo ratings yet
- Data Cleansing - ManipulationDocument22 pagesData Cleansing - Manipulationheryads100% (1)
- Sample Paper 2 SolDocument3 pagesSample Paper 2 SolUnknown ManNo ratings yet
- Import Theory Question - SQLDocument5 pagesImport Theory Question - SQLI'M POPZSHA GAMERNo ratings yet
- Trie - WikipediaDocument10 pagesTrie - WikipediaxbsdNo ratings yet
- Omputer Cience: 3. ArraysDocument48 pagesOmputer Cience: 3. ArraysHassan TariqNo ratings yet
- CS8651 - Ip - Unit - Iv - 2 - PHP VariablesDocument8 pagesCS8651 - Ip - Unit - Iv - 2 - PHP VariablesDurai samyNo ratings yet
- Data & Variable Transformation: Recode and Transform Variables Summarise Variables and Cases Descriptives and SummariesDocument1 pageData & Variable Transformation: Recode and Transform Variables Summarise Variables and Cases Descriptives and SummariesayrusuryaNo ratings yet
- 13 Standard Algorithms: 13.1 Finding The Right Element: Binary SearchDocument26 pages13 Standard Algorithms: 13.1 Finding The Right Element: Binary Searchapi-3745065No ratings yet
- PW2 DataCleaningDocument6 pagesPW2 DataCleaninghhaline9No ratings yet
- Perl BasicsDocument90 pagesPerl BasicsprajwalshekarNo ratings yet
- An Introduction To Data Entry, Data Analysis, and Graphing Using SPSSDocument49 pagesAn Introduction To Data Entry, Data Analysis, and Graphing Using SPSSMinhNo ratings yet
- Merge, Join, and Concatenate: Concatenating ObjectsDocument62 pagesMerge, Join, and Concatenate: Concatenating ObjectssureshNo ratings yet
- Python Data Frame NewDocument32 pagesPython Data Frame NewBen TenNo ratings yet
- PYTHON Pandas and Manipulation DataDocument36 pagesPYTHON Pandas and Manipulation DataQORRY HILDA TIFNo ratings yet
- 8 TypeDocument81 pages8 Typean.nguyenhoang2003No ratings yet
- Cheats Hee TenDocument14 pagesCheats Hee Tenspleen-5230No ratings yet
- Algor 39Document27 pagesAlgor 39heypartygirlNo ratings yet
- Demo Class 15 and 16102022 (Pandas in Python)Document45 pagesDemo Class 15 and 16102022 (Pandas in Python)Oskar NguyenNo ratings yet
- Day 1Document8 pagesDay 1kryptonNo ratings yet
- Data Exploration PreparationDocument12 pagesData Exploration Preparationhamidsithole65No ratings yet
- Imp DetailsDocument6 pagesImp DetailsJyotirmay SahuNo ratings yet
- ITS62604 Tutorial 6 (Answer)Document2 pagesITS62604 Tutorial 6 (Answer)Teng Jun tehNo ratings yet
- Week 7Document10 pagesWeek 7Hanumanthu GouthamiNo ratings yet
- Rural Livelihood ChangeDocument11 pagesRural Livelihood ChangeThai ChiNo ratings yet
- Radel2010 Article AgriculturalLivelihoodTransitiDocument14 pagesRadel2010 Article AgriculturalLivelihoodTransitiThai ChiNo ratings yet
- Global Forest TransitionDocument33 pagesGlobal Forest TransitionThai ChiNo ratings yet
- Course1 Theme2 List and LoopDocument1 pageCourse1 Theme2 List and LoopThai ChiNo ratings yet
- UNIT-3 Data Mining Primitives, Languages, and System ArchitecturesDocument27 pagesUNIT-3 Data Mining Primitives, Languages, and System ArchitecturesdeeuGirlNo ratings yet
- 1 Driving SchoolDocument4 pages1 Driving SchoolSab Fumi100% (1)
- Dbms Lab ManualDocument96 pagesDbms Lab ManualMEDAGUM AARTHI VINATHI LAKSHMI CSEUG-2020 BATCHNo ratings yet
- DSM Ar Staging Interface Base TablesDocument3 pagesDSM Ar Staging Interface Base TablesNagaraj GuntiNo ratings yet
- Massachusetts Institute of Technology: Database Systems: Fall 2008 Quiz IIDocument12 pagesMassachusetts Institute of Technology: Database Systems: Fall 2008 Quiz IIigoginNo ratings yet
- DBMS Set 1Document13 pagesDBMS Set 1Santhosh K100% (1)
- DAC 11gDocument358 pagesDAC 11gbsampatk100% (1)
- Chapter 5. Enhanced Entity Relationship ModelingDocument33 pagesChapter 5. Enhanced Entity Relationship ModelingKiburNo ratings yet
- What Is Normalization in SQL and What Are Its TypesDocument6 pagesWhat Is Normalization in SQL and What Are Its TypesSaagar ShetageNo ratings yet
- Miro Sap MMDocument5 pagesMiro Sap MMPradipta Mallick100% (1)
- Geodatabase: KH 4513 Geographical Information System (Gis)Document15 pagesGeodatabase: KH 4513 Geographical Information System (Gis)Fatima rafiqNo ratings yet
- Spring Hibernate JSF Primefaces IntergrationDocument21 pagesSpring Hibernate JSF Primefaces IntergrationHuy Quan VuNo ratings yet
- Veeam Backup 11 0 Enterprise Manager User GuideDocument341 pagesVeeam Backup 11 0 Enterprise Manager User Guidemafe Murcia100% (1)
- Altered FingerprintsDocument22 pagesAltered FingerprintsVPLAN INFOTECHNo ratings yet
- Database Programming With PL/SQL 1-1: Practice ActivitiesDocument2 pagesDatabase Programming With PL/SQL 1-1: Practice ActivitiesNaski KuafniNo ratings yet
- Introduction To Oracle Database ApplianceDocument4 pagesIntroduction To Oracle Database ApplianceAmr MohammedNo ratings yet
- Oracle Database 12cR2 New FeaturesDocument48 pagesOracle Database 12cR2 New FeaturesConstantin CaiaNo ratings yet
- Installing Oracle Database 11g Release 1 On Enterprise Linux 5 (32 - and 64-Bit)Document19 pagesInstalling Oracle Database 11g Release 1 On Enterprise Linux 5 (32 - and 64-Bit)Irena SusantiNo ratings yet
- Master AccessSQLDocument66 pagesMaster AccessSQLBenjaminBegovicNo ratings yet
- Data Warehousing and Data MiningDocument18 pagesData Warehousing and Data Mininglskannan47No ratings yet
- Solution ErDocument4 pagesSolution ErAhmad M. Khalifi100% (1)
- memoq introduction module 1 - setting up a memoq project.mp4-文稿-转写结果Document4 pagesmemoq introduction module 1 - setting up a memoq project.mp4-文稿-转写结果COLA PEMBERTONNo ratings yet
- MySQL Engine Os 44Document7 pagesMySQL Engine Os 44Mostafa RoshdyNo ratings yet
- Ou Dbms IV Sem NotesDocument127 pagesOu Dbms IV Sem NotesVistasNo ratings yet
- Configure Bind As A Master-Authoritative Private DNS ServerDocument4 pagesConfigure Bind As A Master-Authoritative Private DNS ServerDimuthu Ruwan Bandara DaundasekaraNo ratings yet
- Best Practices - BW Data Loading & PerformanceDocument37 pagesBest Practices - BW Data Loading & PerformanceDebanshu Mukherjee0% (1)
- Lab 1 Introduction To OracleDocument18 pagesLab 1 Introduction To OracleKaram SalahNo ratings yet