You might also like
- Organize Workplace InformationDocument5 pagesOrganize Workplace InformationBiruk Tilahun100% (3)
- AzureDocument58 pagesAzurezeeshankaizerNo ratings yet
- 7Document140 pages7Rishab ChoubeyNo ratings yet
- An Emotional Recommender System For Music PDFDocument12 pagesAn Emotional Recommender System For Music PDFKelner XavierNo ratings yet
- Business Intelligence: Coursework 2 M00678748Document19 pagesBusiness Intelligence: Coursework 2 M00678748Lyfe A1No ratings yet
- Short AnswerDocument14 pagesShort AnswerAtul KumarNo ratings yet
- Business Analytics NotesDocument6 pagesBusiness Analytics NotesCNPHIRINo ratings yet
- System Analysis and Design BBAN602 Unit 2Document46 pagesSystem Analysis and Design BBAN602 Unit 2vivekrockNo ratings yet
- Module 1 Bsais3b GasconalyssamarieDocument10 pagesModule 1 Bsais3b GasconalyssamarieAlyssaNo ratings yet
- Ap08-Aa9-Ev05. Inglés - Taller de Aplicación de Estrategias para La Comprensión de Textos Técnicos en InglésDocument12 pagesAp08-Aa9-Ev05. Inglés - Taller de Aplicación de Estrategias para La Comprensión de Textos Técnicos en Inglésraul andres contreras ortizNo ratings yet
- Actividad de Proyecto 8 Strategies For Succesful Reading Name: Jady Alejandra RestrepoDocument15 pagesActividad de Proyecto 8 Strategies For Succesful Reading Name: Jady Alejandra Restrepocamilo rodriguezNo ratings yet
- Dorothy Llagasicmt 2Document6 pagesDorothy Llagasicmt 2Tiffany PetersNo ratings yet
- Topics:: - How IS Affects Org. - Managers and Decision Making - How IS Affects Decision Making - Dss - GdssDocument49 pagesTopics:: - How IS Affects Org. - Managers and Decision Making - How IS Affects Decision Making - Dss - Gdssankita_johriNo ratings yet
- Module-1 BSAIS3B LUMAPAYROSALIEDocument10 pagesModule-1 BSAIS3B LUMAPAYROSALIEAlyssaNo ratings yet
- Decision Making: Discussion TopicDocument3 pagesDecision Making: Discussion TopicRagini PNo ratings yet
- Systems Analyst As ConsultantDocument4 pagesSystems Analyst As ConsultantRajesh SharmaNo ratings yet
- Ap08 Aa9 Ev05 Formato Taller Aplicacion Estrategias Comprension Textos Tecnicos Ingles 1Document14 pagesAp08 Aa9 Ev05 Formato Taller Aplicacion Estrategias Comprension Textos Tecnicos Ingles 1neftali zambrano ramirezNo ratings yet
- AP08-AA9-EV05. InglésDocument14 pagesAP08-AA9-EV05. InglésCARLOS WILMER BARRERO ROCHANo ratings yet
- Taller Textos Tecnicos Ingles Yobany MeraDocument12 pagesTaller Textos Tecnicos Ingles Yobany MeraYobany Mera jimenezNo ratings yet
- Unit - 6Document35 pagesUnit - 6eldorado.se69No ratings yet
- Tugas - 1 AkuisisiDocument3 pagesTugas - 1 AkuisisiMiko SiregarNo ratings yet
- Group Descision Support SystemDocument15 pagesGroup Descision Support SystemBabnish JoshiNo ratings yet
- Essay QuestionsDocument28 pagesEssay QuestionskamdoNo ratings yet
- +taller de Aplicación de Estrategias para La Comprensión de Textos Técnicos en InglésDocument14 pages+taller de Aplicación de Estrategias para La Comprensión de Textos Técnicos en InglésJUAN CARLOS SAIZ OLIVEROSNo ratings yet
- Mis 3Document73 pagesMis 3JithuHashMiNo ratings yet
- Aplicacion de Estrategias para La Compresion de Textos en InglesDocument13 pagesAplicacion de Estrategias para La Compresion de Textos en InglesAndres AriasNo ratings yet
- Chapter 8 O'Brien - Decision Support SystemDocument3 pagesChapter 8 O'Brien - Decision Support SystemnurulditaprNo ratings yet
- Ap08 Aa9 Ev05Document13 pagesAp08 Aa9 Ev05George CondeNo ratings yet
- Management Information Systems Q and ADocument29 pagesManagement Information Systems Q and APrem KumarNo ratings yet
- Taller de Aplicación de Estrategias para La Comprensión de Textos Técnicos en InglésDocument13 pagesTaller de Aplicación de Estrategias para La Comprensión de Textos Técnicos en InglésDeivy Julian ValenciaNo ratings yet
- Tugas Review Enchanging Decision Making Sim 2021 Santi Aslamiyah Hasibuan 180502049Document6 pagesTugas Review Enchanging Decision Making Sim 2021 Santi Aslamiyah Hasibuan 180502049anitaNo ratings yet
- AP08-AA9-EV05-C ODOFICACIONTaller-Aplicacion-Estrategias-Comprension-Textos-Tecnicos-InglesDocument13 pagesAP08-AA9-EV05-C ODOFICACIONTaller-Aplicacion-Estrategias-Comprension-Textos-Tecnicos-Ingleskira gomezNo ratings yet
- System Analysis and Design: Information Gathering: Unobtrusive MethodsDocument51 pagesSystem Analysis and Design: Information Gathering: Unobtrusive MethodsNovel SarkerNo ratings yet
- Mis - Mba Sem 1 Module 1Document45 pagesMis - Mba Sem 1 Module 1Pooja PandyaNo ratings yet
- AP08 AA9 EV05 Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesDocument14 pagesAP08 AA9 EV05 Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesLiliana VarelaNo ratings yet
- University Managing Information and Knowledg Assignment: UnityDocument10 pagesUniversity Managing Information and Knowledg Assignment: Unityአረጋዊ ሐይለማርያምNo ratings yet
- Actividad de Proyecto 8 Strategies For Succesful Reading Name: Charles Andres Romero RDocument12 pagesActividad de Proyecto 8 Strategies For Succesful Reading Name: Charles Andres Romero RCarlos RomeroNo ratings yet
- How Technology-Purchasing Decisions Are Really Made: The at TheDocument21 pagesHow Technology-Purchasing Decisions Are Really Made: The at TheVaibhav PrasadNo ratings yet
- Assingment CSE301 A60006420098 BY PIYUSH ANANDDocument8 pagesAssingment CSE301 A60006420098 BY PIYUSH ANANDPiyush AnandNo ratings yet
- Information System (Is)Document27 pagesInformation System (Is)Pooja RaiNo ratings yet
- Actividad de Proyecto 8 Strategies For Succesful Reading NameDocument13 pagesActividad de Proyecto 8 Strategies For Succesful Reading NameSteven MorenoNo ratings yet
- AP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesDocument14 pagesAP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesHernan LEON MARTINEZNo ratings yet
- Ism 1Document38 pagesIsm 1Neha KanojiaNo ratings yet
- IT-510 Module 4 Part TwoDocument3 pagesIT-510 Module 4 Part Twopetetg5172No ratings yet
- Name: Haseeb Mujeeb. Roll No: 033. Class: Bba. Samester: 5 (TH) - Subject: MIS. (CH.10) Submitted To: Sir - Aneeb LashariDocument7 pagesName: Haseeb Mujeeb. Roll No: 033. Class: Bba. Samester: 5 (TH) - Subject: MIS. (CH.10) Submitted To: Sir - Aneeb LashariHaseeb MujeebNo ratings yet
- AP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesDocument13 pagesAP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesBrayan Forero80% (5)
- Information Sheet (EM Liaison)Document16 pagesInformation Sheet (EM Liaison)Do Dothings100% (1)
- Reporting G 5Document12 pagesReporting G 5Vic-Aljari RazonNo ratings yet
- MIS - Management Information SystemDocument8 pagesMIS - Management Information SystemGinu L PrakashNo ratings yet
- Lesson 1. The World of The Modern System's AnalystDocument10 pagesLesson 1. The World of The Modern System's AnalystMary Ivy PunzalanNo ratings yet
- Savitribai Phule Pune University School of Open Learning (Distance Education Program)Document21 pagesSavitribai Phule Pune University School of Open Learning (Distance Education Program)Ajinkya NaikNo ratings yet
- AP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesDocument13 pagesAP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos Inglesliliana carrillo alarconNo ratings yet
- Business AnalyticsDocument5 pagesBusiness AnalyticsAngelica EsguireroNo ratings yet
- (Chapter 2) INFORMATION SYSTEM CONCEPTSDocument57 pages(Chapter 2) INFORMATION SYSTEM CONCEPTSRodulfo Capinig GabritoNo ratings yet
- Chapter 2 - Various Concepts of MISDocument23 pagesChapter 2 - Various Concepts of MISridhimaamit100% (3)
- Mis - Abi's New Year Gift For 2012Document111 pagesMis - Abi's New Year Gift For 2012Edmond DantèsNo ratings yet
- Actividad de Proyecto 8 Strategies For Succesful ReadingDocument14 pagesActividad de Proyecto 8 Strategies For Succesful ReadingYeimmy Franco BastidasNo ratings yet
- AP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos InglesDocument13 pagesAP08 AA9 EV05 FORMATO Taller Aplicacion Estrategias Comprension Textos Tecnicos Inglesmilton martinez batistaNo ratings yet
- 3.2.2 Implications For System DesignDocument34 pages3.2.2 Implications For System DesignppghoshinNo ratings yet
- Topic 2: Management Information System: 1. Office Automation System (OAS)Document13 pagesTopic 2: Management Information System: 1. Office Automation System (OAS)Hildah JJNo ratings yet
- Everyone Wants to Work Here: Attract the Best Talent, Energize Your Team, and Be the Leader in Your MarketFrom EverandEveryone Wants to Work Here: Attract the Best Talent, Energize Your Team, and Be the Leader in Your MarketNo ratings yet
- Mixing IT Up: Information Technology Business Analysis On The RocksFrom EverandMixing IT Up: Information Technology Business Analysis On The RocksNo ratings yet
- Clothes Shopping Website ThesisDocument50 pagesClothes Shopping Website Thesisshweta choudharyNo ratings yet
- Project Thesis NEW FINALDocument50 pagesProject Thesis NEW FINALshweta choudharyNo ratings yet
- Project Thesis NEW FINALDocument50 pagesProject Thesis NEW FINALshweta choudharyNo ratings yet
- Unit 1 CNS NotesDocument14 pagesUnit 1 CNS Notesshweta choudharyNo ratings yet
- Unit 05 5.1ascertaining Hardware and Software NeedsDocument8 pagesUnit 05 5.1ascertaining Hardware and Software Needsshweta choudharyNo ratings yet
- Unit 04 4.1 Data Dictionary Concept: Field Name Data Type Field Size For Display Description ExampleDocument13 pagesUnit 04 4.1 Data Dictionary Concept: Field Name Data Type Field Size For Display Description Exampleshweta choudharyNo ratings yet
- C9 ICT Full BookDocument122 pagesC9 ICT Full BookTajtiné Bondár KatalinNo ratings yet
- CSC 432 With PQDocument32 pagesCSC 432 With PQOdesanya MichealNo ratings yet
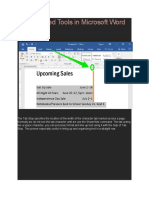
- Lab Activity No. 2 - MS Word ToolsDocument18 pagesLab Activity No. 2 - MS Word ToolsPizzaTobacco123No ratings yet
- Sound Blaster Live! 24-Bit Card 03SB041000001Document1 pageSound Blaster Live! 24-Bit Card 03SB041000001BetoSabaletaNo ratings yet
- Original Poker - Pitch Deck SpeedrunDocument15 pagesOriginal Poker - Pitch Deck SpeedrunAndersen WaquedNo ratings yet
- 2013 SENSORCOMM Early-Warning System For Machine FailureDocument7 pages2013 SENSORCOMM Early-Warning System For Machine FailureLuqman AzamNo ratings yet
- 05 Physical Design in Data Warehouse 2018Document8 pages05 Physical Design in Data Warehouse 2018AdhitamaNo ratings yet
- EC Engineer Ankit ResumeDocument3 pagesEC Engineer Ankit Resumejigs2k26232100% (2)
- Numlex 1009Document3 pagesNumlex 1009Othmane BénNo ratings yet
- Siemens 7SJ512 V3.2 Template Manual ENU TU2.20 V1.100Document13 pagesSiemens 7SJ512 V3.2 Template Manual ENU TU2.20 V1.100RaúlEmirGutiérrezLópezNo ratings yet
- Understanding Digital Image ProcessingDocument30 pagesUnderstanding Digital Image ProcessingthatisthatNo ratings yet
- Quiz 3 - Nse 2 v3 OkDocument2 pagesQuiz 3 - Nse 2 v3 OkJohn Angelo Recalde MonarNo ratings yet
- Amoeba Distributed Operating SystemDocument20 pagesAmoeba Distributed Operating Systemadam_ridzuan91No ratings yet
- Graphic Standards 04-MAR-21Document26 pagesGraphic Standards 04-MAR-21Ramesh Kavitha Sanjit 18BME0677No ratings yet
- Digital Twin Driven Additive ManufactureDocument26 pagesDigital Twin Driven Additive ManufactureNursultan JyeniskhanNo ratings yet
- MAAT MTG User ManualDocument15 pagesMAAT MTG User ManualOliver MasciarotteNo ratings yet
- Competitive Content Analysis TemplateDocument19 pagesCompetitive Content Analysis TemplatePrince PatelNo ratings yet
- WT Chap 2 CSSDocument37 pagesWT Chap 2 CSSmuskan shaikhNo ratings yet
- 13 Cit353 Tma3 10-WPS OfficeDocument12 pages13 Cit353 Tma3 10-WPS OfficeStanley IjegbulemNo ratings yet
- Computers Model PapersDocument50 pagesComputers Model PapersSubrahmanyam AdapaNo ratings yet
- Opsmvs - Opslog OverviewDocument95 pagesOpsmvs - Opslog OverviewNayyar AlamNo ratings yet
- TECHNICAL DRAFTING 10 Module 2Document26 pagesTECHNICAL DRAFTING 10 Module 2Alyssa Jean QuemuelNo ratings yet
- 255 Technical Specification Fridge-Tag 2 EDocument2 pages255 Technical Specification Fridge-Tag 2 EFima JandulNo ratings yet
- ISO 26262 Dependent Failure Analysis Using PSS: Moonki Jang, Jiwoong Kim, Dongjoo KimDocument11 pagesISO 26262 Dependent Failure Analysis Using PSS: Moonki Jang, Jiwoong Kim, Dongjoo KimMani KiranNo ratings yet
- Cat P2Document15 pagesCat P2Ricardo BartlettNo ratings yet
- Flow-Gateway-10-20-0-User GuideDocument84 pagesFlow-Gateway-10-20-0-User GuideToan NguyenNo ratings yet