You might also like
- Replika: Building An Emotional Conversation With Deep LearningDocument26 pagesReplika: Building An Emotional Conversation With Deep LearningKartikeya Shorya100% (3)
- Ericsson Minilink PDFDocument2 pagesEricsson Minilink PDFStuartNo ratings yet
- Intro To Deep LearningDocument39 pagesIntro To Deep LearninghiperboreoatlantecNo ratings yet
- 1.1 ACS ACR122U NFC Reader-Writer-Pyton Code (VERY GOOD)Document6 pages1.1 ACS ACR122U NFC Reader-Writer-Pyton Code (VERY GOOD)sarbiniNo ratings yet
- Milan Milenkovic Operating Systems Concepts and Design DF56EDocument12 pagesMilan Milenkovic Operating Systems Concepts and Design DF56EGianniNicheliNo ratings yet
- Midterms - Attempt ReviewDocument10 pagesMidterms - Attempt ReviewBibi CaliBenitoNo ratings yet
- Altered FingerprintsDocument22 pagesAltered FingerprintsVPLAN INFOTECHNo ratings yet
- 02 Predictive Maintenance Workshop - PIDI 4.0Document39 pages02 Predictive Maintenance Workshop - PIDI 4.0Zaky DriveNo ratings yet
- EDR Presentation SlidesDocument50 pagesEDR Presentation Slidesattacker 3541No ratings yet
- Data Science Applications and Research DirectionsDocument38 pagesData Science Applications and Research DirectionsRobin Rohit100% (1)
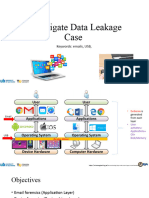
- NIST Data Leakage 04 Email USBDocument45 pagesNIST Data Leakage 04 Email USBwanNo ratings yet
- 03 Behavioral 2023-24Document86 pages03 Behavioral 2023-24lorel17157No ratings yet
- Effectively Enhancing Our Soc With Sysmon Powershell Logging and Machine Learning To Detect and Respond To Todays Threats PDFDocument43 pagesEffectively Enhancing Our Soc With Sysmon Powershell Logging and Machine Learning To Detect and Respond To Todays Threats PDFHamza IdrisNo ratings yet
- Input Design & Prototyping: CSC 401: Database Management SystemDocument29 pagesInput Design & Prototyping: CSC 401: Database Management SystemMohitul ShafirNo ratings yet
- DIET SecurityandMachineLearningBruhadeshwarDocument71 pagesDIET SecurityandMachineLearningBruhadeshwarDainikMitraNo ratings yet
- It lbcml2 01 StoryboardDocument68 pagesIt lbcml2 01 StoryboardVikram ParmarNo ratings yet
- NIST Data Leakage 04 Email USBDocument46 pagesNIST Data Leakage 04 Email USBthaivuongks2020No ratings yet
- Computer Forensic Chapter 9Document25 pagesComputer Forensic Chapter 9syahmiNo ratings yet
- 03.bobak Group IB Portfolio UpdateDocument32 pages03.bobak Group IB Portfolio Updateericstevens77777No ratings yet
- To Computing System DesignDocument76 pagesTo Computing System DesignpradeepceeNo ratings yet
- Introduction To BiometricsDocument41 pagesIntroduction To BiometricstoffiqNo ratings yet
- 1-4 To 1-5Document12 pages1-4 To 1-5Vijani RajapathiranaNo ratings yet
- NanoedgeaistudioDocument6 pagesNanoedgeaistudioAbraham GutierrezNo ratings yet
- Apex One™ As A Service: Endpoint Sensor: Trend MicroDocument3 pagesApex One™ As A Service: Endpoint Sensor: Trend MicroriyasathsafranNo ratings yet
- A41174 - Vision AI When Data Is Expensive and Constantly ChangingDocument30 pagesA41174 - Vision AI When Data Is Expensive and Constantly ChanginghenrydclNo ratings yet
- Lightweight Deep LearningDocument27 pagesLightweight Deep LearningHuston LAMNo ratings yet
- Tech Talks Discover The Security Features of Secure VaultDocument27 pagesTech Talks Discover The Security Features of Secure Vaultsanjeev sanjeevNo ratings yet
- MBA EXE 4 Final Paper CourseDocument41 pagesMBA EXE 4 Final Paper CourseOmerhayat MianNo ratings yet
- Fireeye HX SeriesDocument2 pagesFireeye HX Serieslingo.chichalaNo ratings yet
- COMP33812: Software Evolution: Andy Carpenter School of Computer ScienceDocument19 pagesCOMP33812: Software Evolution: Andy Carpenter School of Computer ScienceGeneNo ratings yet
- Deep Machine Learning Meets CybersecurityDocument14 pagesDeep Machine Learning Meets CybersecurityMILTON ENRIQUE CHINCHAY CELADANo ratings yet
- Diagnostics HandoutsDocument43 pagesDiagnostics Handoutsraghavendra swamyNo ratings yet
- Application DeterminationDocument40 pagesApplication DeterminationcraigNo ratings yet
- L2 Ict - UNIT 2: Technology Systems Revision Template: Subject Notes Revision DoneDocument8 pagesL2 Ict - UNIT 2: Technology Systems Revision Template: Subject Notes Revision Doneapi-448604259No ratings yet
- ZN17 - DoroshenkoYuS - Open Source Sandbox in A Corporate InfrastructureDocument26 pagesZN17 - DoroshenkoYuS - Open Source Sandbox in A Corporate InfrastructureTama OlanNo ratings yet
- Microprocessor Systems: - A Brief Run DownDocument28 pagesMicroprocessor Systems: - A Brief Run Downkartika_krazeNo ratings yet
- VeinDocument68 pagesVeinpriyanka extazeeNo ratings yet
- Env Acc EnvDocument52 pagesEnv Acc EnvDini ErtantoNo ratings yet
- ESD - DAY 1-PortalDocument35 pagesESD - DAY 1-PortaldraqulaincNo ratings yet
- Introduction To Iot and Its Security: Mr. Avinash KumarDocument42 pagesIntroduction To Iot and Its Security: Mr. Avinash KumarFiroz HussainNo ratings yet
- Trend Micro Deep Discovery InspectorDocument3 pagesTrend Micro Deep Discovery InspectorhaivadiNo ratings yet
- Section 7-Requirements of The Information SystemDocument44 pagesSection 7-Requirements of The Information SystemAbu Sufian MahiNo ratings yet
- مذكرات الرخصة الدولية باللغة الانجليزيةDocument94 pagesمذكرات الرخصة الدولية باللغة الانجليزيةMohammed Abd-elatyNo ratings yet
- How To Prepare For Computer Science 2210 Exam: By: Engineer Fahad Ahmad Khan, MS Software Engineering, BE TelecomDocument41 pagesHow To Prepare For Computer Science 2210 Exam: By: Engineer Fahad Ahmad Khan, MS Software Engineering, BE TelecomShahriar AzgarNo ratings yet
- Cisco Firepower and Radware Technical OverviewDocument14 pagesCisco Firepower and Radware Technical OverviewAlfredo Claros100% (1)
- Intelligent Transportation Systems (ITS) : Lelitha Devi Vanajakshi Professor Dept. of Civil EnggDocument37 pagesIntelligent Transportation Systems (ITS) : Lelitha Devi Vanajakshi Professor Dept. of Civil EnggSUBHAM SAGARNo ratings yet
- Deepsign: Deep Learning For Automatic Malware Signature Generation and ClassificationDocument20 pagesDeepsign: Deep Learning For Automatic Malware Signature Generation and ClassificationMoeen NaqviNo ratings yet
- Ready Recknor - Grade IX - CA - 2020-21Document109 pagesReady Recknor - Grade IX - CA - 2020-21HALOLLOLNo ratings yet
- Cynet Solution BriefDocument17 pagesCynet Solution BriefRey RazNo ratings yet
- ESD - DAY 1-EnhancedDocument41 pagesESD - DAY 1-EnhancedINTTICNo ratings yet
- Intrusion Detection/Prevention SystemsDocument29 pagesIntrusion Detection/Prevention SystemsDereje ChinklNo ratings yet
- Rsa Netwitness PlatformDocument7 pagesRsa Netwitness Platformdoan nguyenNo ratings yet
- Advanced Binary Deobfuscation PDFDocument136 pagesAdvanced Binary Deobfuscation PDFkougaR8No ratings yet
- Parts of ComputerDocument25 pagesParts of Computerlarkej51No ratings yet
- DSP Presentation Overview For ClassDocument71 pagesDSP Presentation Overview For ClassVarssha BNo ratings yet
- Auto Reader ReproposalDocument23 pagesAuto Reader ReproposalSun LilyNo ratings yet
- Sfespecification PDFDocument29 pagesSfespecification PDFjanoNo ratings yet
- Laboratory 2 AnswerDocument4 pagesLaboratory 2 AnswerJohn Kristoffer VillarNo ratings yet
- Problem DomainDocument4 pagesProblem DomainmadhukedarNo ratings yet
- Shri Chimanbhai Patel Institute of Computer Application Gujarat University Paper - 2008 C.F.D.PDocument14 pagesShri Chimanbhai Patel Institute of Computer Application Gujarat University Paper - 2008 C.F.D.PrajbirkalerNo ratings yet
- Mca SynopsisDocument28 pagesMca SynopsisRajbeer Kumar DasNo ratings yet
- Rapiscan 620XR ScreenDocument2 pagesRapiscan 620XR ScreenNeil Botes100% (1)
- Srs HW Steg NetDocument9 pagesSrs HW Steg Netsyeda husnaNo ratings yet
- Rapiscan 620XR ScreenDocument2 pagesRapiscan 620XR Screenpnsanat0% (1)
- Sensor Based Automated Irrigation System With Iot A Technical ReviewDocument4 pagesSensor Based Automated Irrigation System With Iot A Technical ReviewJhanina CapicioNo ratings yet
- Logistics 05 00062Document16 pagesLogistics 05 00062VikasNo ratings yet
- A Hybrid Ostu Based Niblack Binarization For Degraded Image DocumentsDocument7 pagesA Hybrid Ostu Based Niblack Binarization For Degraded Image Documentsivanz.arsiNo ratings yet
- Ripple Curve Background PowerPoint TemplatesDocument21 pagesRipple Curve Background PowerPoint TemplatesRamadhan AkbarNo ratings yet
- Hybrid Intercom Network White Paper: Intelligent Intercom-Over-IP For International Sports EventsDocument11 pagesHybrid Intercom Network White Paper: Intelligent Intercom-Over-IP For International Sports EventsdarwinNo ratings yet
- Lecture Notes 13 7Document14 pagesLecture Notes 13 7Aldrige LuisNo ratings yet
- Quarter 3 Css 9 Module 1Document14 pagesQuarter 3 Css 9 Module 1ricaNo ratings yet
- Graph TheoryDocument32 pagesGraph TheoryRvprasadNo ratings yet
- PDF - SolverDocument7 pagesPDF - SolverRAJKUMAR CHATTERJEE. (RAJA.)No ratings yet
- CIS RAM For IG1 Workbook v21.10.25Document144 pagesCIS RAM For IG1 Workbook v21.10.25pikanteNo ratings yet
- Rest Api Interview Question 20-21Document5 pagesRest Api Interview Question 20-21VijjuNo ratings yet
- Gaoler SlidesCarnivalDocument31 pagesGaoler SlidesCarnivalHind CHAFAINo ratings yet
- ABS/EBS Products: Catalog L20243, Rev. 9/12Document60 pagesABS/EBS Products: Catalog L20243, Rev. 9/12Rodrigo Hernán BascettaNo ratings yet
- Document (14) - 2Document55 pagesDocument (14) - 2ADITYA PANDEYNo ratings yet
- Stack ADT Using InterfaceDocument4 pagesStack ADT Using Interface1035 PUNEETH RAM PNo ratings yet
- Documentation - Iterm2 - macOS Terminal ReplacementDocument67 pagesDocumentation - Iterm2 - macOS Terminal ReplacementThomas AndaNo ratings yet
- C70 PLC Interface Manual - Mitsubishi Electric (B1500263engj)Document700 pagesC70 PLC Interface Manual - Mitsubishi Electric (B1500263engj)vip6k_299890070No ratings yet
- EMVCo 3DS Protocol Oct2017Document255 pagesEMVCo 3DS Protocol Oct2017vicvinodNo ratings yet
- Notas FinaisDocument2 pagesNotas FinaisFlorence FranklinNo ratings yet
- Grade 6 Holidays HomeworkDocument5 pagesGrade 6 Holidays HomeworkParul ChhabraNo ratings yet
- TLC200-Manual - (EN A11) - 20130911Document24 pagesTLC200-Manual - (EN A11) - 20130911Rigor MortisNo ratings yet
- ODK1500S-XMLDataAccess DOCU V10 enDocument23 pagesODK1500S-XMLDataAccess DOCU V10 enAlisson OliveiraNo ratings yet
- Problem Solving and Programming ConceptsDocument54 pagesProblem Solving and Programming Conceptssiva100% (1)
- Sick Lector CLV PN CP v2 1 enDocument28 pagesSick Lector CLV PN CP v2 1 enRafael GagoNo ratings yet
- Heart Disease Prediction Model: DissertationDocument4 pagesHeart Disease Prediction Model: DissertationGaurav MehraNo ratings yet