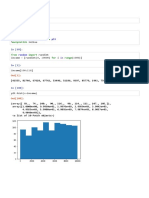
You might also like
- Develop Snakes & Ladders Game Complete Guide with Code & DesignFrom EverandDevelop Snakes & Ladders Game Complete Guide with Code & DesignNo ratings yet
- Develop Snake & Ladder Game in an Hour (Complete Guide with Code & Design)From EverandDevelop Snake & Ladder Game in an Hour (Complete Guide with Code & Design)No ratings yet
- World Happiness ReportDocument7 pagesWorld Happiness ReportMuriloMonteiroNo ratings yet
- Control System Mini Project-1Document7 pagesControl System Mini Project-1Binod MalikNo ratings yet
- Collaborative Review Task M2 1Document19 pagesCollaborative Review Task M2 1Abdullah AbdullahNo ratings yet
- ICSE BlueJ Logical ProgramDocument49 pagesICSE BlueJ Logical ProgramPrathibha S NairNo ratings yet
- Submission Group 12 Exercise 5Document42 pagesSubmission Group 12 Exercise 5Mehmet YalçınNo ratings yet
- 5.datavisulation: 0.0.1 Type of GraphsDocument30 pages5.datavisulation: 0.0.1 Type of GraphsAnish pandeyNo ratings yet
- Task 4: Exploratory Data Analysis - Terrorism Task 4: Exploratory Data Analysis - Terrorism Presented By: Nishant Kumar Presented By: Nishant KumarDocument11 pagesTask 4: Exploratory Data Analysis - Terrorism Task 4: Exploratory Data Analysis - Terrorism Presented By: Nishant Kumar Presented By: Nishant KumarnishantNo ratings yet
- 1 Linear Regression: 1.1 Data ExplorationDocument12 pages1 Linear Regression: 1.1 Data ExplorationXyzNo ratings yet
- Pie Charts, Box Plots, Scatter Plots and Bubble PlotsDocument11 pagesPie Charts, Box Plots, Scatter Plots and Bubble PlotsВильсон ЛевNo ratings yet
- 22 Dim Reduction Part-1Document9 pages22 Dim Reduction Part-1Gabriel GheorgheNo ratings yet
- Ts NotebookDocument22 pagesTs NotebookDanilo Santiago Criollo Chávez100% (1)
- Citizen Calculator SR 135 ManualDocument18 pagesCitizen Calculator SR 135 ManualBrandy JonesNo ratings yet
- Numpy NP Pandas PD Matplotlib - Pyplot PLT: Import As Import As Import As MatplotlibDocument11 pagesNumpy NP Pandas PD Matplotlib - Pyplot PLT: Import As Import As Import As MatplotlibMubasil AliNo ratings yet
- 6.datawrangling: Data VisulationDocument27 pages6.datawrangling: Data VisulationAnish pandeyNo ratings yet
- RRRRRRRRRRRRRRRRRRDocument2 pagesRRRRRRRRRRRRRRRRRRcamNo ratings yet
- Taller RDocument37 pagesTaller RHuevo SapeNo ratings yet
- Python LABDocument50 pagesPython LABToufik HossainNo ratings yet
- Year Per Capita Income (US$) 0 1970 1 1971 2 1972 3 1973 4 1974Document1 pageYear Per Capita Income (US$) 0 1970 1 1971 2 1972 3 1973 4 1974mogak92082No ratings yet
- CCDPS GZB: Summer Break Assignment For Class XII StudentsDocument4 pagesCCDPS GZB: Summer Break Assignment For Class XII StudentsDEEPTI SHARMANo ratings yet
- Project: Gapminder World Data: How The World Has Changed For 200 Years?Document19 pagesProject: Gapminder World Data: How The World Has Changed For 200 Years?Vy Đặng ThảoNo ratings yet
- Xii Cs Practical File 1Document22 pagesXii Cs Practical File 1MoniNo ratings yet
- COST of Capital Q and A1Document2 pagesCOST of Capital Q and A1Sam Sep A SixtyoneNo ratings yet
- Prac 5 PandasDocument6 pagesPrac 5 PandasheilNo ratings yet
- DbscanDocument5 pagesDbscanMuhammad GattanNo ratings yet
- Stock Price Prediction Project Utilizing LSTM TechniquesDocument14 pagesStock Price Prediction Project Utilizing LSTM TechniquesNisAr AhmadNo ratings yet
- R19C076 - Chanukya Gowda K - Mlda - Assignment-2Document19 pagesR19C076 - Chanukya Gowda K - Mlda - Assignment-2Chanukya Gowda kNo ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Police Gender Pay GapDocument4 pagesPolice Gender Pay GaphammadusNo ratings yet
- Ass 4Document2 pagesAss 4Akash SahuNo ratings yet
- Chapter 5Document22 pagesChapter 5Rajat BansalNo ratings yet
- SMDM Practice Exercise Solution - Week 1 - Loksabha Election 2019 (2) - Jupyter NotebookDocument10 pagesSMDM Practice Exercise Solution - Week 1 - Loksabha Election 2019 (2) - Jupyter NotebookSecret PsychologyNo ratings yet
- Introduction To Business Analytics: Syntax and OutputsDocument16 pagesIntroduction To Business Analytics: Syntax and OutputsGypsy KingNo ratings yet
- Fertilidad: Numpy NP Pandas PD Matplotlib - Pyplot PLT IpywidgetsDocument8 pagesFertilidad: Numpy NP Pandas PD Matplotlib - Pyplot PLT IpywidgetsKevin Fernando Ochoa Martinez100% (1)
- Nama: Mashuril Agil NIM: 0702173157 Kelas: Sistem Informasi-2 Mata Kuliah: Data ScienceDocument5 pagesNama: Mashuril Agil NIM: 0702173157 Kelas: Sistem Informasi-2 Mata Kuliah: Data Scienceada sajaNo ratings yet
- Chettinad Vidyashram STD X - Record Programs - 2021 - 2022 Artificial IntelligenceDocument15 pagesChettinad Vidyashram STD X - Record Programs - 2021 - 2022 Artificial IntelligenceAarush Ram AnandhNo ratings yet
- EDA - Session-4 - Numerical Data AnalysisDocument9 pagesEDA - Session-4 - Numerical Data Analysisjeeshu048No ratings yet
- Graph 1: Data: Observations Reasonably Spread Across Years. Distribution Across 15 OccupationsDocument12 pagesGraph 1: Data: Observations Reasonably Spread Across Years. Distribution Across 15 OccupationsWes McClintickNo ratings yet
- Eco Outlook AxisDocument26 pagesEco Outlook AxisinbanwNo ratings yet
- Tax Slab CodeDocument1 pageTax Slab CodeAbhay KambleNo ratings yet
- Nonnewtonian Problem 3-C - Jupyter NotebookDocument8 pagesNonnewtonian Problem 3-C - Jupyter NotebookPatel AnjaliNo ratings yet
- CruiserDocument95 pagesCruiserMohamed KalebNo ratings yet
- P&S 2020im14 Assignment FinalDocument29 pagesP&S 2020im14 Assignment FinalMuhammad Asim Muhammad ArshadNo ratings yet
- Erro Homologação 2333Document243 pagesErro Homologação 2333Jorge SaavedraNo ratings yet
- Countries of The World Data AnalysisDocument19 pagesCountries of The World Data AnalysisaaaaaaffffgNo ratings yet
- Arithmetic With MatricesDocument8 pagesArithmetic With MatricesViridiana BFNo ratings yet
- Cfa CalculatorDocument33 pagesCfa CalculatorTanvir Ahmed Syed100% (2)
- 3D Surface and Contour Plot Tutorial in MatlabDocument8 pages3D Surface and Contour Plot Tutorial in MatlabRenee DaleNo ratings yet
- Lab 6 K-MeansDocument3 pagesLab 6 K-MeansRana Luthfiya MezaNo ratings yet
- R Program Record Book IbaDocument24 pagesR Program Record Book IbaTEJASWININo ratings yet
- Statistic - With Python PDFDocument11 pagesStatistic - With Python PDFPutri Sanjiwani DewiNo ratings yet
- Final Practical File 2022-23Document87 pagesFinal Practical File 2022-23Kuldeep SinghNo ratings yet
- A066 PA PractDocument8 pagesA066 PA PractYash JadhavNo ratings yet
- Python Crash Course by Ehmatthes 16Document1 pagePython Crash Course by Ehmatthes 16alfonsofdezNo ratings yet
- 1 Assignment 4 - Hypothesis TestingDocument5 pages1 Assignment 4 - Hypothesis TestingFantasyyyNo ratings yet
- Mongo DBDocument194 pagesMongo DBvikashNo ratings yet
- Assignment: Master in Business AdministrationDocument18 pagesAssignment: Master in Business AdministrationkisanNo ratings yet
- Python Course Cheat SheetDocument30 pagesPython Course Cheat SheetVinayNo ratings yet
- Lab 5 EADocument4 pagesLab 5 EAAndrew TrejoNo ratings yet
- Notice of Claim Senate FinalDocument44 pagesNotice of Claim Senate FinalDanny Shapiro0% (1)
- Ceniza Vs CADocument2 pagesCeniza Vs CACarmille MagnoNo ratings yet
- 08 Cyber Crime & Cyber Laws FinalDocument50 pages08 Cyber Crime & Cyber Laws Finalshalinibabu879033% (3)
- Winner Team Memorial Petitioner Nlujaa Vox Anatolis Nation Krishnakantdnism Mnlumumbaieduin 20230910 093731 1 17Document17 pagesWinner Team Memorial Petitioner Nlujaa Vox Anatolis Nation Krishnakantdnism Mnlumumbaieduin 20230910 093731 1 17Tanmay DeshmukhNo ratings yet
- Sub 41Document12 pagesSub 41Samz AdrianNo ratings yet
- G.R. No. 126005 People vs. CerbioDocument9 pagesG.R. No. 126005 People vs. CerbiofranzesannNo ratings yet
- UNITED ALLIED EMPIRE SDN BHD v. PENGARAH TANAH 2017 8 CLJ 173Document22 pagesUNITED ALLIED EMPIRE SDN BHD v. PENGARAH TANAH 2017 8 CLJ 173NURAIN HANIS BINTI ARIFFNo ratings yet
- Business Law 1 NotesDocument74 pagesBusiness Law 1 NotesRANDAN SADIQ100% (3)
- Self Defense Training Proposal - Final PDFDocument5 pagesSelf Defense Training Proposal - Final PDFSean Jodi CosepeNo ratings yet
- Job Safety & Environmental Analysis (Jsea) : Schlumberger CTSDocument4 pagesJob Safety & Environmental Analysis (Jsea) : Schlumberger CTShans vatriolisNo ratings yet
- Wrongful Death Law FirmDocument8 pagesWrongful Death Law FirmAamir KhanNo ratings yet
- Module 7 Safety Health Management SystemsDocument34 pagesModule 7 Safety Health Management SystemsKavin RajNo ratings yet
- Executive Order No. 82 S 2012 - 1612491791Document4 pagesExecutive Order No. 82 S 2012 - 1612491791Josanne Wadwadan De CastroNo ratings yet
- Case Shell Company - Chap 04-2023Document3 pagesCase Shell Company - Chap 04-2023joynasr17No ratings yet
- T19PDocument39 pagesT19Pgauri chauhanNo ratings yet
- Baptiste LawsuitDocument42 pagesBaptiste LawsuitWTVCNo ratings yet
- Blueprint References: Title & Auxiliary InformationDocument5 pagesBlueprint References: Title & Auxiliary InformationSAQIBNo ratings yet
- Attorney General V Blake EditDocument3 pagesAttorney General V Blake EditBryanYau2001No ratings yet
- Emergency in IndiaDocument30 pagesEmergency in IndiaRiya SinghNo ratings yet
- Lecture 6 - TrustsDocument15 pagesLecture 6 - TrustsSteve KennedyNo ratings yet
- Module 6 - Determinants of MoralityDocument6 pagesModule 6 - Determinants of MoralityJulie Anne CesarNo ratings yet
- Mrl3702 Portfolio of Exercises CompleteDocument55 pagesMrl3702 Portfolio of Exercises Completetf2hzfkbnmNo ratings yet
- Law of Torts Syllabus (July-October 2022) : Ashby V White (1703) 2 Council (2003) 3 All 1122Document3 pagesLaw of Torts Syllabus (July-October 2022) : Ashby V White (1703) 2 Council (2003) 3 All 1122Zorawar AlmeidaNo ratings yet
- Agreement: Nadcap Auditee Agreement - Accreditation AuditDocument7 pagesAgreement: Nadcap Auditee Agreement - Accreditation AuditmdfNo ratings yet
- SOCORRO D. RAMIREZ v. CADocument8 pagesSOCORRO D. RAMIREZ v. CAChatNo ratings yet
- Mcglynn 2017 Rape Trials and Sexual History Evidence Reforming The Law On Third Party EvidenceDocument26 pagesMcglynn 2017 Rape Trials and Sexual History Evidence Reforming The Law On Third Party EvidenceGlory BJSNo ratings yet
- Judicial RemediesDocument23 pagesJudicial Remediesjim munkNo ratings yet
- Q4 HEALTH 9 Module 1 Week1.ALPHA TESTEDDocument14 pagesQ4 HEALTH 9 Module 1 Week1.ALPHA TESTEDCyris Gay AdolfoNo ratings yet
- EthicsDocument48 pagesEthicsTadesse Fenta100% (1)
- Social Contract - Definition, Examples, Hobbes, Locke, & Rousseau - BritannicaDocument7 pagesSocial Contract - Definition, Examples, Hobbes, Locke, & Rousseau - BritannicaErica GiesbrechtNo ratings yet