You might also like
- The Book of Hebrew Script History PDFDocument347 pagesThe Book of Hebrew Script History PDFYehoshua100% (8)
- Differences between Lz, UNT, UNB parameters in STAAD ProDocument3 pagesDifferences between Lz, UNT, UNB parameters in STAAD Prodesikudi90000% (1)
- Chapter Ten: Hebrew Weak VerbsDocument31 pagesChapter Ten: Hebrew Weak Verbssteffen han100% (5)
- 101 Helpful Python TipsDocument56 pages101 Helpful Python TipsASWINI KALYANNo ratings yet
- Super Advanced Python TechniquesDocument120 pagesSuper Advanced Python TechniquesShreyas WaghmareNo ratings yet
- PythonTraining MD Saiful Azad UMPDocument54 pagesPythonTraining MD Saiful Azad UMPMadam AzimahNo ratings yet
- HUAWEI - 03 Python AdvancedDocument22 pagesHUAWEI - 03 Python AdvancedPierpaolo VergatiNo ratings yet
- Python Fundamentals For Machine Learning Version1Document58 pagesPython Fundamentals For Machine Learning Version1NABI MNo ratings yet
- M.Khorasani Consulting & Publishing: Persian Swords in The State Hermitage Museum (Saint Petersburg 2015)Document14 pagesM.Khorasani Consulting & Publishing: Persian Swords in The State Hermitage Museum (Saint Petersburg 2015)Deakin DailNo ratings yet
- Python assignment and comparison operators guideDocument70 pagesPython assignment and comparison operators guidetik took100% (1)
- Python Lab ManualDocument19 pagesPython Lab ManualRahul YadavNo ratings yet
- College Nursing Research Framework VariablesDocument6 pagesCollege Nursing Research Framework VariablesJoshua MendozaNo ratings yet
- Tradicionalna Kuhinja Jevreja Bivse Jugoslavije OCRDocument172 pagesTradicionalna Kuhinja Jevreja Bivse Jugoslavije OCRErmina100% (1)
- Python ZTM Cheatsheet: Andrei NeagoieDocument38 pagesPython ZTM Cheatsheet: Andrei NeagoiemalikNo ratings yet
- Nested if-else loops in PythonDocument16 pagesNested if-else loops in PythonTheAncient01No ratings yet
- Python Cheat SheetDocument25 pagesPython Cheat SheetJORGE EDUARDO HUERTA ESPARZANo ratings yet
- Python - Module Test - Jupyter NotebookDocument6 pagesPython - Module Test - Jupyter NotebookPawan GosaviNo ratings yet
- TA1101練習 - Jupyter NotebookDocument14 pagesTA1101練習 - Jupyter NotebookYI-LIN CHANGNo ratings yet
- TA1101 - Jupyter NotebookDocument14 pagesTA1101 - Jupyter NotebookYI-LIN CHANGNo ratings yet
- Python Rat La Co Ban - Vo Duy Tuan 2Document92 pagesPython Rat La Co Ban - Vo Duy Tuan 2ThangPhanNo ratings yet
- TA1107 - Jupyter NotebookDocument12 pagesTA1107 - Jupyter NotebookYI-LIN CHANGNo ratings yet
- Python Basics 1689905586Document26 pagesPython Basics 1689905586Romit MaityNo ratings yet
- Resumos PythonDocument11 pagesResumos PythonAna Sofia FerreiraNo ratings yet
- Set1 - Jupyter Notebook - 091348Document3 pagesSet1 - Jupyter Notebook - 091348tabish.khan.kmr.1323No ratings yet
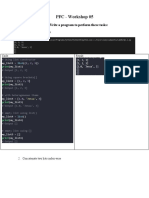
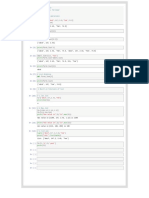
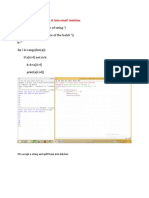
- PFC - Workshop 05: Question 1 (2.5 Marks) : Write A Program To Perform These TasksDocument7 pagesPFC - Workshop 05: Question 1 (2.5 Marks) : Write A Program To Perform These TasksDuong Thanh Duy (K17 QN)No ratings yet
- Day - 1 - String - Functions - Jupyter NotebookDocument16 pagesDay - 1 - String - Functions - Jupyter NotebookVrushali VishwasraoNo ratings yet
- 101 Helpful Python TipsDocument56 pages101 Helpful Python TipsASWINI KALYANNo ratings yet
- Lecture 2: More Data Structures: OutlineDocument16 pagesLecture 2: More Data Structures: OutlineBakari HamisiNo ratings yet
- Intro PDSDocument12 pagesIntro PDSAlbin P JNo ratings yet
- 19BBTCS069 KrishnaKantPandey DAP Lab RecordDocument100 pages19BBTCS069 KrishnaKantPandey DAP Lab RecordKrishna KantNo ratings yet
- lab1Document7 pageslab1tabish.khan.daNo ratings yet
- 3 - Intro - To - Python: 1 Using Python As A CalculatorDocument16 pages3 - Intro - To - Python: 1 Using Python As A Calculatorvb_murthyNo ratings yet
- Resumen PythonDocument13 pagesResumen PythonsanabressanabresNo ratings yet
- Basics of Python (Part I)Document11 pagesBasics of Python (Part I)venkata seshuNo ratings yet
- PythonNotesV1 0Document3 pagesPythonNotesV1 0murthygrsNo ratings yet
- While Loop: Fibonacci SeriesDocument21 pagesWhile Loop: Fibonacci SeriesAnuj RuhelaNo ratings yet
- numbers_1 - Jupyter NotebookDocument8 pagesnumbers_1 - Jupyter Notebooktabish.khan.daNo ratings yet
- Brush Up Python: 0.1 1. BasicsDocument10 pagesBrush Up Python: 0.1 1. Basicsrikdas20063433No ratings yet
- Intro to Python ProgrammingDocument18 pagesIntro to Python ProgrammingKirti GuptaNo ratings yet
- #Nguyễn Trung Thịnh - MSSV: 1851150061 - Lớp: KM18 #Printing and readingDocument18 pages#Nguyễn Trung Thịnh - MSSV: 1851150061 - Lớp: KM18 #Printing and readingNguyen Trung ThinhNo ratings yet
- What Is PythonDocument10 pagesWhat Is Pythonskylarzhang66No ratings yet
- Bucles ForDocument13 pagesBucles Forrosa maria carbajoNo ratings yet
- List, Tuple, Set Operations in PythonDocument2 pagesList, Tuple, Set Operations in PythonMANGESH BHOSALENo ratings yet
- Application of Python and Data Analytics in Oil and GAs-1Document40 pagesApplication of Python and Data Analytics in Oil and GAs-1godfreyNo ratings yet
- 12 CS Python Revision Tour 1&2 WorksheetDocument5 pages12 CS Python Revision Tour 1&2 WorksheetskltripathiNo ratings yet
- Python Class7Document18 pagesPython Class7KrishnaprasadNo ratings yet
- 01 - Variables & Output in PythonDocument8 pages01 - Variables & Output in PythonMANISH SIKHWALNo ratings yet
- 04 Data Types in PythonDocument12 pages04 Data Types in PythonKrishna GudimellaNo ratings yet
- Class 14 List Methods 2Document17 pagesClass 14 List Methods 2TheAncient01No ratings yet
- Lesson 6 ListsDocument9 pagesLesson 6 ListsPavankumar TrvdNo ratings yet
- Numbers: # Basic Calculations 1+2 5/6 # Numbers A 123.1 Print (A) B 10 Print (B) A + B C A + B Print (C)Document80 pagesNumbers: # Basic Calculations 1+2 5/6 # Numbers A 123.1 Print (A) B 10 Print (B) A + B C A + B Print (C)Ahmad NazirNo ratings yet
- Examples of Small Python ScriptsDocument16 pagesExamples of Small Python Scriptseas4787skumarNo ratings yet
- 100+ Python Tips (with Code) Skyrocket Your SkillsDocument33 pages100+ Python Tips (with Code) Skyrocket Your SkillsMonseurseyeNo ratings yet
- Lectuer Four: 1 Lecture 4: String ManipulationDocument9 pagesLectuer Four: 1 Lecture 4: String ManipulationAram SalahNo ratings yet
- Atharv BhambareDocument73 pagesAtharv Bhambarenileshlawande09No ratings yet
- Tuples: 'Physics' 'Chemistry' "A" "B" "C" "D" "E"Document7 pagesTuples: 'Physics' 'Chemistry' "A" "B" "C" "D" "E"sanju kumarNo ratings yet
- What Will Be The Output For The Following CodeDocument19 pagesWhat Will Be The Output For The Following CodebishwajNo ratings yet
- List - PracticeDocument3 pagesList - PracticeTheAncient01No ratings yet
- SumanmlDocument4 pagesSumanmlsumanNo ratings yet
- pradipDocument73 pagespradipnileshlawande09No ratings yet
- Python Assignment 4Document5 pagesPython Assignment 4Jai SaiNo ratings yet
- Python PracticalDocument35 pagesPython PracticalRahul VermaNo ratings yet
- Coding Interview Python Language EssentialsDocument5 pagesCoding Interview Python Language EssentialsSaurav SinghNo ratings yet
- Lect2 SlidesDocument24 pagesLect2 SlidestqbrowneNo ratings yet
- TA1101 - Jupyter NotebookDocument14 pagesTA1101 - Jupyter NotebookYI-LIN CHANGNo ratings yet
- Python 02 ExpressionDocument41 pagesPython 02 ExpressionYI-LIN CHANGNo ratings yet
- Python 01 IntroductionDocument40 pagesPython 01 IntroductionYI-LIN CHANGNo ratings yet
- TA1107 - Jupyter NotebookDocument12 pagesTA1107 - Jupyter NotebookYI-LIN CHANGNo ratings yet
- TA1101練習 - Jupyter NotebookDocument14 pagesTA1101練習 - Jupyter NotebookYI-LIN CHANGNo ratings yet
- SQL Interview Questions 2021Document18 pagesSQL Interview Questions 2021K RUKESHNo ratings yet
- The Periods in The History of The English LanguageDocument1 pageThe Periods in The History of The English Languagereinette82No ratings yet
- Myself As A Communicator Reflection PaperDocument4 pagesMyself As A Communicator Reflection Paperapi-512330161No ratings yet
- Plot Summary and Genre - Docx - 12Document3 pagesPlot Summary and Genre - Docx - 12Rivera MarianelNo ratings yet
- PolynomialsDocument16 pagesPolynomialsFlorentino Espinosa IINo ratings yet
- Testovi Iz EngleskogDocument15 pagesTestovi Iz EngleskogSanja100% (9)
- Fce Statement ResultsDocument1 pageFce Statement Resultsdangnganha159No ratings yet
- Nivel TeenDocument6 pagesNivel TeenAnglo Fray BentosNo ratings yet
- POWTECH HMI ManulDocument194 pagesPOWTECH HMI ManulvaronibericoNo ratings yet
- 02 OnScreen 2 Unit 2Document12 pages02 OnScreen 2 Unit 2Kami MagNo ratings yet
- The Manobo Tasaday: Real People, Real FilipinoDocument1 pageThe Manobo Tasaday: Real People, Real FilipinoBea RosalesNo ratings yet
- Material - Sesión 5: Tema: Irregular VerbsDocument3 pagesMaterial - Sesión 5: Tema: Irregular VerbsJ Paola Chavez CochachiNo ratings yet
- TNPSC General English MCQ PDFDocument137 pagesTNPSC General English MCQ PDFDiviya Pandiyan0% (1)
- LDS Old Testament Notes 05: EnochDocument8 pagesLDS Old Testament Notes 05: EnochMike ParkerNo ratings yet
- Ordering Fractions, Decimals and Percentages: Fraction Decimal PercentageDocument13 pagesOrdering Fractions, Decimals and Percentages: Fraction Decimal Percentagezainab idreesNo ratings yet
- UMS Computer Science Lab 1 IntroductionDocument2 pagesUMS Computer Science Lab 1 IntroductionIqi IceNo ratings yet
- Red WheelbarrowDocument3 pagesRed WheelbarrowARJUN MURALINo ratings yet
- Correccion Examen CuartoDocument9 pagesCorreccion Examen CuartoMiguel GonzalezNo ratings yet
- Examen Selectividad Andalucia. COVID-19Document4 pagesExamen Selectividad Andalucia. COVID-19Monica PerezNo ratings yet
- Marathy Dalith PoemsDocument3 pagesMarathy Dalith PoemsDevidas Krishnan100% (1)
- Guz ZettiDocument15 pagesGuz ZettiLeireNo ratings yet
- 33 International Kangaroo Mathematics Contest 2023: Section OneDocument8 pages33 International Kangaroo Mathematics Contest 2023: Section Onerdsiddiqui1No ratings yet
- Be: Positive And: Simple Present Negative Simple PresentDocument4 pagesBe: Positive And: Simple Present Negative Simple Presentnathalia costaNo ratings yet
- 5º Primaria SummerDocument9 pages5º Primaria SummerAnonymous 7xhhVAWCXNo ratings yet