You might also like
- Cyber-Physical Attacks: A Growing Invisible ThreatFrom EverandCyber-Physical Attacks: A Growing Invisible ThreatRating: 4.5 out of 5 stars4.5/5 (3)
- Essentials On Safety Instrumented SystemsDocument9 pagesEssentials On Safety Instrumented Systemstibi1000No ratings yet
- Bayes Rules! An Introduction To Applied Bayesian Modeling - Alicia A. Johnson, Miles Q. Ott, Mine Dogucu (2022)Document544 pagesBayes Rules! An Introduction To Applied Bayesian Modeling - Alicia A. Johnson, Miles Q. Ott, Mine Dogucu (2022)Carola Gauna0% (1)
- Blake ElectronicsDocument508 pagesBlake Electronicsk_chops33% (3)
- Bayesian Latent Class Analysis Tutorial Li2018Document23 pagesBayesian Latent Class Analysis Tutorial Li2018Dom DeSiciliaNo ratings yet
- ADA465587Document37 pagesADA465587MohamedIbrahimNo ratings yet
- CDC 8515 DS1Document10 pagesCDC 8515 DS1Sriparna PaulNo ratings yet
- Understanding Use, Misuse and Abuse of SIL - 3a.silsDocument17 pagesUnderstanding Use, Misuse and Abuse of SIL - 3a.silsJoseNo ratings yet
- New RelatedDocument5 pagesNew RelatedAslam MasihNo ratings yet
- 3A SILsDocument17 pages3A SILsahmed messallamNo ratings yet
- Vulnerability Analysis of Energy Delivery Control Systems 2011 PDFDocument183 pagesVulnerability Analysis of Energy Delivery Control Systems 2011 PDFnicanorcuNo ratings yet
- Salfner08software Reliability-1 PDFDocument22 pagesSalfner08software Reliability-1 PDFma_purwoadiNo ratings yet
- Measuring, Analyzing and Predicting SecurityDocument10 pagesMeasuring, Analyzing and Predicting SecurityAidan Consultancy ServiceNo ratings yet
- A Framework For Proactive Fault ToleranceDocument6 pagesA Framework For Proactive Fault Tolerancetechnology&movie,funny videosNo ratings yet
- Fault Tree AnalysisDocument8 pagesFault Tree Analysisankitsaxena123No ratings yet
- Reliability Engineering and System Safety: Suleyman KondakciDocument25 pagesReliability Engineering and System Safety: Suleyman Kondakcigsreis1100% (1)
- OASIcs CERTS 2019 4Document13 pagesOASIcs CERTS 2019 4Aloysius AlvinoNo ratings yet
- Determining The Reliability and Plant Availability of A Production SyztemDocument53 pagesDetermining The Reliability and Plant Availability of A Production SyztemGeorgina SuleNo ratings yet
- The Easy Path To Functional Safety ComplianceDocument3 pagesThe Easy Path To Functional Safety ComplianceSam Demha100% (1)
- Quantitative Vulnerability AssessmentDocument6 pagesQuantitative Vulnerability AssessmentSpyDr ByTeNo ratings yet
- Sec14 Paper CostinDocument17 pagesSec14 Paper CostinnicolasvNo ratings yet
- Redundancy and Diversity in Security: (B.Littlewood, L.Strigini) @CSR - City.ac - UkDocument16 pagesRedundancy and Diversity in Security: (B.Littlewood, L.Strigini) @CSR - City.ac - UkAmber GreenNo ratings yet
- "System-Of-Systems" Approach For Interdependent Critical InfrastructuresDocument8 pages"System-Of-Systems" Approach For Interdependent Critical InfrastructuresGoran MuricNo ratings yet
- Research Paper On FmeaDocument4 pagesResearch Paper On Fmeadave jinNo ratings yet
- Adepts jcn06 CamerareadyDocument21 pagesAdepts jcn06 Camerareadysoobins ppangNo ratings yet
- Failsafe Architecture UFSBIDocument7 pagesFailsafe Architecture UFSBIAkhilesh YadavNo ratings yet
- Untrustworthiness: A Trust-Based Security MetricDocument4 pagesUntrustworthiness: A Trust-Based Security MetricSuhail Qadir MirNo ratings yet
- Towards Practical Cybersecurity Mapping of STRIDEDocument11 pagesTowards Practical Cybersecurity Mapping of STRIDEsalmanqNo ratings yet
- Software Challenges in Achieving Space SafetyDocument15 pagesSoftware Challenges in Achieving Space SafetyAnonymous mE6MEje0No ratings yet
- Survey ON Fault Tolerance IN Grid Computing: P. Latchoumy and P. Sheik Abdul KhaderDocument14 pagesSurvey ON Fault Tolerance IN Grid Computing: P. Latchoumy and P. Sheik Abdul KhaderijcsesNo ratings yet
- Cybersecurity Education and Formal MethodDocument12 pagesCybersecurity Education and Formal MethodRofans ManaoNo ratings yet
- Expert Systems With Applications: Sohag KabirDocument22 pagesExpert Systems With Applications: Sohag KabirAyşenur SancakNo ratings yet
- Safety EngineeringDocument6 pagesSafety EngineeringValentin RadulescuNo ratings yet
- 3.impediments o SecurityDocument16 pages3.impediments o SecurityTakudzwa MusaririNo ratings yet
- International Journal of Network Security & Its Applications (IJNSA)Document11 pagesInternational Journal of Network Security & Its Applications (IJNSA)AIRCC - IJNSANo ratings yet
- Vulnerability Assessment For Applications Security Through Penetration Simulation and TestingDocument22 pagesVulnerability Assessment For Applications Security Through Penetration Simulation and TestingshameerNo ratings yet
- Security Application of Failure Mode and Effect Analysis (FMEA)Document17 pagesSecurity Application of Failure Mode and Effect Analysis (FMEA)NNo ratings yet
- Fault-Injection and Dependability Benchmarking For Grid Computing MiddlewareDocument10 pagesFault-Injection and Dependability Benchmarking For Grid Computing MiddlewareMustafamna Al SalamNo ratings yet
- Software Tool For Distributed Elevator SystemsDocument9 pagesSoftware Tool For Distributed Elevator Systemsnebojsa_n_nikolicNo ratings yet
- Designing Instrumentation and Control For Process SafetyDocument7 pagesDesigning Instrumentation and Control For Process SafetyAdebamboAinaNo ratings yet
- Functional Safety Concepts in Motor ControlDocument9 pagesFunctional Safety Concepts in Motor ControlYan LiuNo ratings yet
- A New Paradigm in Information Security and Network ArchitectureDocument12 pagesA New Paradigm in Information Security and Network ArchitectureMinal SalviNo ratings yet
- A Comprehensive Approach To Intrusion Detection Alert CorrelationDocument25 pagesA Comprehensive Approach To Intrusion Detection Alert Correlationali5833No ratings yet
- Kenna VMDocument25 pagesKenna VMnav pNo ratings yet
- DownloadDocument26 pagesDownloadKhải TrầnNo ratings yet
- A Novel Approach To Derive The Average-Case Behavior of Distributed Embedded SystemDocument11 pagesA Novel Approach To Derive The Average-Case Behavior of Distributed Embedded SystemijccmsNo ratings yet
- Risks Due To Convergence of Physical Security SystemsDocument5 pagesRisks Due To Convergence of Physical Security SystemsMuhammad Dawood Abu AnasNo ratings yet
- Analysis of Existing Dynamic Software Updating Techniques For Safe and Secure Industrial Control SystemsDocument11 pagesAnalysis of Existing Dynamic Software Updating Techniques For Safe and Secure Industrial Control SystemsMr Moony ShineNo ratings yet
- Finalproject Csol530Document9 pagesFinalproject Csol530api-526409506No ratings yet
- Draft NISTIR 7517 Software VulneralbilitiesDocument37 pagesDraft NISTIR 7517 Software VulneralbilitiesAlexander Suryo PrabowoNo ratings yet
- Trust and Risk Assessment Model of Popular Software Based On Known Vulnerabilities PDFDocument8 pagesTrust and Risk Assessment Model of Popular Software Based On Known Vulnerabilities PDFIt's RohanNo ratings yet
- Es Unit3 FinalDocument9 pagesEs Unit3 FinalYadavilli VinayNo ratings yet
- Principles of Trust For Embedded SystemsDocument20 pagesPrinciples of Trust For Embedded SystemsSoftware Engineering Institute PublicationsNo ratings yet
- Security and Project Management: Robert J. EllisonDocument14 pagesSecurity and Project Management: Robert J. Ellisonzakarya yahyaNo ratings yet
- Grunske Et Al-2011-Software Practice and ExperienceDocument26 pagesGrunske Et Al-2011-Software Practice and ExperienceBruno LeãoNo ratings yet
- Sec14 Paper Costin PDFDocument17 pagesSec14 Paper Costin PDFAhmed HamoudaNo ratings yet
- System ScalabilityDocument63 pagesSystem ScalabilityAnonymous 3gp5mwfNo ratings yet
- 1 s2.0 S0951832021003410 MainDocument12 pages1 s2.0 S0951832021003410 MainmkNo ratings yet
- Essentials of SisDocument9 pagesEssentials of SisNeil MenezesNo ratings yet
- Role Engineering: From Design To Evolution of Security SchemesDocument21 pagesRole Engineering: From Design To Evolution of Security SchemesJuan RedesNo ratings yet
- Object XMLDocumentDocument9 pagesObject XMLDocumentkhoshnamaNo ratings yet
- A Systematic Approach For The Design of Safety Critical SystemsDocument5 pagesA Systematic Approach For The Design of Safety Critical SystemsInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Safe and Secure Cyber-Physical Systems and Internet-of-Things SystemsFrom EverandSafe and Secure Cyber-Physical Systems and Internet-of-Things SystemsNo ratings yet
- Upcoming Automotive Standards For Fault-Tolerant CDocument13 pagesUpcoming Automotive Standards For Fault-Tolerant CvfsdgvdgNo ratings yet
- Fault Tolerance by Design Diversity Concepts and ExperimentsDocument14 pagesFault Tolerance by Design Diversity Concepts and ExperimentsvfsdgvdgNo ratings yet
- Fault-Tolerance and Fault-Intolerance - Complementary Approaches To Reliable ComputingDocument7 pagesFault-Tolerance and Fault-Intolerance - Complementary Approaches To Reliable ComputingvfsdgvdgNo ratings yet
- Proceedings Woa 2020Document256 pagesProceedings Woa 2020vfsdgvdgNo ratings yet
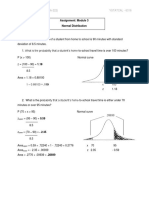
- Gungon Module 3 Stats AssignmentDocument3 pagesGungon Module 3 Stats Assignment마리레나No ratings yet
- Comandos PAUP y Mr. BayesDocument2 pagesComandos PAUP y Mr. Bayesalexander velezNo ratings yet
- 15.097: Probabilistic Modeling and Bayesian AnalysisDocument42 pages15.097: Probabilistic Modeling and Bayesian AnalysisSarbani DasguptsNo ratings yet
- Calendar - Asset-V1 - MITx+6.431x+1T2022+type@asset+block@resources - 1T2022 - Calendar - 1t2022-U10Document2 pagesCalendar - Asset-V1 - MITx+6.431x+1T2022+type@asset+block@resources - 1T2022 - Calendar - 1t2022-U10JosueMancoBarrenecheaNo ratings yet
- MCMC Bayes PDFDocument27 pagesMCMC Bayes PDFMichael TadesseNo ratings yet
- Basics of Probabilistic/Bayesian Modeling and Parameter EstimationDocument21 pagesBasics of Probabilistic/Bayesian Modeling and Parameter EstimationYash VarunNo ratings yet
- 03 MLE MAP NBayes-1-21-2015Document40 pages03 MLE MAP NBayes-1-21-2015Muhammad MurtazaNo ratings yet
- Lab 6 - Naive Bayesian Classification ExercisesDocument9 pagesLab 6 - Naive Bayesian Classification ExercisesLALITH SARANNo ratings yet
- Gamma DistributionDocument30 pagesGamma DistributionshardultagalpallewarNo ratings yet
- (MAA 4.10) BINOMIAL DISTRIBUTION - SolutionsDocument4 pages(MAA 4.10) BINOMIAL DISTRIBUTION - Solutionsvarsha.sundarNo ratings yet
- Hydro MatlabDocument6 pagesHydro MatlabRiya KatiyarNo ratings yet
- Comparative Efficacy of Various Hypoxic Training Paradi - 2023 - Journal of ExerDocument10 pagesComparative Efficacy of Various Hypoxic Training Paradi - 2023 - Journal of ExerSherriNo ratings yet
- Table of The Standard Normal Cumulative Distribution FunctionDocument1 pageTable of The Standard Normal Cumulative Distribution Functionarshiya_nawaz7802100% (1)
- Nice CV I FoundDocument5 pagesNice CV I FoundOmar MejouateNo ratings yet
- N MAb Version1Document226 pagesN MAb Version1sellerm4c1n2No ratings yet
- Bayesian Linear RegressionDocument20 pagesBayesian Linear Regressionxolar2002No ratings yet
- Bayes GaussDocument29 pagesBayes GaussYogesh Nijsure100% (1)
- Introduction To Bayesian Monte Carlo Methods in WINBUGSDocument37 pagesIntroduction To Bayesian Monte Carlo Methods in WINBUGSrshe0025004No ratings yet
- Santos HW4 Ce175-4cDocument3 pagesSantos HW4 Ce175-4cZaireen SantosNo ratings yet
- DF 10 PDFDocument7 pagesDF 10 PDFCarolina UrrutiaNo ratings yet
- BayseianDocument181 pagesBayseianMuhammad AsadNo ratings yet
- Bayesian ClassificationDocument25 pagesBayesian Classificationkanika sharmaNo ratings yet
- 2469 ArticleText 7670 1 10 20200710Document10 pages2469 ArticleText 7670 1 10 20200710Ali MahamedNo ratings yet
- Lecture 13Document27 pagesLecture 13Kanwwar PaulNo ratings yet
- Formulario Vad VacDocument2 pagesFormulario Vad VacOSCAR EMMANUEL MEJIA HERNANDEZNo ratings yet
- The Exponential Family of Distributions: P (X) H (X) eDocument13 pagesThe Exponential Family of Distributions: P (X) H (X) eMarco RNo ratings yet
- Poisson TableDocument10 pagesPoisson TableLukitawesa SoeriodikoesoemoNo ratings yet