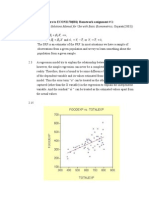
You might also like
- Examples EconometricsDocument3 pagesExamples EconometricsHương LêNo ratings yet
- MidtermII Preparation QuestionsDocument5 pagesMidtermII Preparation Questionsjoud.eljazzaziNo ratings yet
- ECON 482 Answer Key ExplainedDocument7 pagesECON 482 Answer Key ExplainedJaime Andres Chica PNo ratings yet
- hw4 SoDocument18 pageshw4 SoAbdu Abdoulaye100% (2)
- PS Solutions Chapter 14Document5 pagesPS Solutions Chapter 14Michael SubrotoNo ratings yet
- HW10 Solu F09Document4 pagesHW10 Solu F09Nimroz MominNo ratings yet
- LinearRegression - 2022Document38 pagesLinearRegression - 2022Miguel Sacristán de FrutosNo ratings yet
- HW2 SolutionDocument7 pagesHW2 Solutionrita901112No ratings yet
- Homework 8-Huilin ZhangDocument9 pagesHomework 8-Huilin ZhangMax RahmanNo ratings yet
- Set of Problems 9Document3 pagesSet of Problems 9Luca VanzNo ratings yet
- Quiz Questions on Regression Analysis and CorrelationDocument10 pagesQuiz Questions on Regression Analysis and CorrelationHarsh ShrinetNo ratings yet
- Statistics 500: Midterm 1 NameDocument6 pagesStatistics 500: Midterm 1 NameSouleymane CoulibalyNo ratings yet
- Simple Linear RegressionDocument31 pagesSimple Linear RegressionturnernpNo ratings yet
- Mid Term UmtDocument4 pagesMid Term Umtfazalulbasit9796No ratings yet
- SBR Tutorial 4 - Solution - UpdatedDocument4 pagesSBR Tutorial 4 - Solution - UpdatedZoloft Zithromax ProzacNo ratings yet
- Chapter 8 B - Trendlines and Regression AnalysisDocument73 pagesChapter 8 B - Trendlines and Regression AnalysisPankaj MaryeNo ratings yet
- Problem Set 5Document5 pagesProblem Set 5Sila KapsataNo ratings yet
- Statistics - HighlightedDocument7 pagesStatistics - HighlightedBenNo ratings yet
- PLDocument5 pagesPLMy SpotifyNo ratings yet
- Vmls - 103exercisesDocument50 pagesVmls - 103exercisessalnasuNo ratings yet
- Sample Final SolutionsDocument12 pagesSample Final SolutionsKhushboo KhanejaNo ratings yet
- LDocument8 pagesLRajesh Rao B RajNo ratings yet
- Evans Analytics2e PPT 08Document65 pagesEvans Analytics2e PPT 08txuanNo ratings yet
- HW2Document3 pagesHW2刘阳龙No ratings yet
- Problem Set 2Document3 pagesProblem Set 2Luca VanzNo ratings yet
- Problem IDocument10 pagesProblem Imgharba123No ratings yet
- Multiple Regression Models: Ey X X XDocument27 pagesMultiple Regression Models: Ey X X Xsamspeed7No ratings yet
- Solution of Problem Set 1 For Purity Hydrocarbon Data PDFDocument4 pagesSolution of Problem Set 1 For Purity Hydrocarbon Data PDFDrumil TrivediNo ratings yet
- Midterm Fall19 Solutions StatisticsDocument13 pagesMidterm Fall19 Solutions StatisticsPratyush ParasharNo ratings yet
- Aff700 1000 221209Document11 pagesAff700 1000 221209nnajichinedu20No ratings yet
- ECON2170 Homework: Regression models and hypothesis testingDocument7 pagesECON2170 Homework: Regression models and hypothesis testingPilSeung HeoNo ratings yet
- 2015 Midterm SolutionsDocument7 pages2015 Midterm SolutionsEdith Kua100% (1)
- STA 2101 Assignment 1 ReviewDocument8 pagesSTA 2101 Assignment 1 ReviewdflamsheepsNo ratings yet
- Simple Linear Regression and Correlation ExplainedDocument76 pagesSimple Linear Regression and Correlation Explainedcookiehacker100% (1)
- Chapter 05 - MulticollinearityDocument26 pagesChapter 05 - Multicollinearitymgayanan100% (1)
- Lecture 8+9 Multicollinearity and Heteroskedasticity Exercise 10.2Document3 pagesLecture 8+9 Multicollinearity and Heteroskedasticity Exercise 10.2Amelia TranNo ratings yet
- ECON 601 - Module 4 PS - Solutions - FA 19 PDFDocument11 pagesECON 601 - Module 4 PS - Solutions - FA 19 PDFTamzid IslamNo ratings yet
- Linear Regression in RDocument7 pagesLinear Regression in Rmeric8669No ratings yet
- Multiple Linear Regression: Chapter 12Document49 pagesMultiple Linear Regression: Chapter 12Ayushi MauryaNo ratings yet
- Tutorial 1Document3 pagesTutorial 1HappinessNo ratings yet
- Umair AssignmentDocument19 pagesUmair Assignmentsheraz khanNo ratings yet
- New Group AssignmentDocument10 pagesNew Group AssignmentAbnet BeleteNo ratings yet
- Exercises 4,5,6,7+test CanvasDocument5 pagesExercises 4,5,6,7+test CanvasEduardo MuñozNo ratings yet
- Excel Regression Analysis ToolsDocument19 pagesExcel Regression Analysis ToolsBiplove PokhrelNo ratings yet
- 3 Fall 2007 Exam PDFDocument7 pages3 Fall 2007 Exam PDFAchilles 777No ratings yet
- Econ452: Problem Set 2: University of Michigan - Department of EconomicsDocument4 pagesEcon452: Problem Set 2: University of Michigan - Department of EconomicsWill MillerNo ratings yet
- Forecasting Electric Bills and Teacher Salaries with Regression ModelsDocument3 pagesForecasting Electric Bills and Teacher Salaries with Regression ModelsKim ErichNo ratings yet
- Sample FinalDocument10 pagesSample FinalKhushboo KhanejaNo ratings yet
- Tutorial 9Document19 pagesTutorial 9Trang Nguyễn Ngọc ThiênNo ratings yet
- Business Research-II Notes AnalysisDocument10 pagesBusiness Research-II Notes AnalysisVIDITI JAJODIANo ratings yet
- Linear Regression Correlation AnalysisDocument24 pagesLinear Regression Correlation AnalysisSalami JamaNo ratings yet
- 103 ExercisesDocument70 pages103 Exerciseshungbkpro90No ratings yet
- Errors in Numerical ComputationsDocument17 pagesErrors in Numerical ComputationsGoura Sundar TripathyNo ratings yet
- Statistics 17 by KellerDocument76 pagesStatistics 17 by KellerMahmoudElbehairyNo ratings yet
- WK4 Session 8 Workshop (CH 10)Document28 pagesWK4 Session 8 Workshop (CH 10)Zaeem AsgharNo ratings yet
- Maths NotesDocument195 pagesMaths NotesSharon ToppoNo ratings yet
- RegressionDocument3 pagesRegressionLuyanda BlomNo ratings yet
- Somya Bhasin 24years Pune: Professional ExperienceDocument2 pagesSomya Bhasin 24years Pune: Professional ExperienceS1626No ratings yet
- SMAI Assignment 7 Report - 20161204 PDFDocument6 pagesSMAI Assignment 7 Report - 20161204 PDFAliNo ratings yet
- CasesDocument8 pagesCasesLinh TrịnhNo ratings yet
- Autoencoder Asset Pricing ModelsDocument22 pagesAutoencoder Asset Pricing ModelsEdson KitaniNo ratings yet
- PMDC Renewal FormDocument3 pagesPMDC Renewal FormAmjad Ali100% (1)
- Ict OhsDocument26 pagesIct Ohscloyd mark cabusogNo ratings yet
- r6 - SCV - PV - 2012 June MarkB PDFDocument32 pagesr6 - SCV - PV - 2012 June MarkB PDFsanjiivNo ratings yet
- HMSWeb - Handover Management SystemDocument21 pagesHMSWeb - Handover Management SystemGG GRNo ratings yet
- Cebu Oxygen Acetylene Co., vs. Drilon, G.R. No. 82849, August 2, 1989Document6 pagesCebu Oxygen Acetylene Co., vs. Drilon, G.R. No. 82849, August 2, 1989JemNo ratings yet
- Dhi-Ehs-Hsm-028 Work Over Water Rev0Document5 pagesDhi-Ehs-Hsm-028 Work Over Water Rev0Phạm Đình NghĩaNo ratings yet
- Manual Micro DNC 2dDocument31 pagesManual Micro DNC 2dDiego GarciaNo ratings yet
- DMT L4.Technical English & Communication (Information & Assignment)Document80 pagesDMT L4.Technical English & Communication (Information & Assignment)Eng Teik PhungNo ratings yet
- Key Benefits of Cloud-Based Internet of Vehicle (IoV) - Enabled Fleet Weight Management SystemDocument5 pagesKey Benefits of Cloud-Based Internet of Vehicle (IoV) - Enabled Fleet Weight Management SystemVelumani sNo ratings yet
- 2003 June Calc Paper 6 (H)Document20 pages2003 June Calc Paper 6 (H)abbasfazilNo ratings yet
- 5 Basic Model of PorterDocument6 pages5 Basic Model of PorterJahanvi PandyaNo ratings yet
- Elizabeth Line When Fully Open PDFDocument1 pageElizabeth Line When Fully Open PDFArmandoNo ratings yet
- Title Page - Super King Air C90CGTi FusionDocument2 pagesTitle Page - Super King Air C90CGTi Fusionsergio0% (1)
- Updated Scar Management Practical Guidelines Non-IDocument10 pagesUpdated Scar Management Practical Guidelines Non-IChilo PrimaNo ratings yet
- Matrix 210N Reference Manual 2017 PDFDocument167 pagesMatrix 210N Reference Manual 2017 PDFiozsa cristianNo ratings yet
- 2X16-24 Monorail Hoist-04 - 2Document1 page2X16-24 Monorail Hoist-04 - 2RafifNo ratings yet
- Comments PRAG FinalDocument13 pagesComments PRAG FinalcristiancaluianNo ratings yet
- MCQ (Trigo)Document10 pagesMCQ (Trigo)RaghavNo ratings yet
- Safety Data Sheet: SECTION 1: Identification of The Substance/mixture and of The Company/undertakingDocument8 pagesSafety Data Sheet: SECTION 1: Identification of The Substance/mixture and of The Company/undertakingFerry Dela RochaNo ratings yet
- Athus Souza - ResumeDocument2 pagesAthus Souza - ResumeArielBen-ShalomBarbosaNo ratings yet
- Baja2018 Unisa Team3 Design ReportDocument23 pagesBaja2018 Unisa Team3 Design ReportDaniel MabengoNo ratings yet
- Distributor AgreementDocument10 pagesDistributor Agreementsanket_hiremathNo ratings yet
- Soc 1 Report Salesforce Services - 5EwWEDocument75 pagesSoc 1 Report Salesforce Services - 5EwWEArif IqbalNo ratings yet
- Huawei Tecal RH2288 V2 Server Compatibility List PDFDocument30 pagesHuawei Tecal RH2288 V2 Server Compatibility List PDFMenganoFulanoNo ratings yet
- 20-Sdms-02 (Overhead Line Accessories) Rev01Document15 pages20-Sdms-02 (Overhead Line Accessories) Rev01Haytham BafoNo ratings yet
- Microprocessor 8086 Memory and ArchitectureDocument13 pagesMicroprocessor 8086 Memory and ArchitecturehrrameshhrNo ratings yet
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.From EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Rating: 5 out of 5 stars5/5 (1)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 5 out of 5 stars5/5 (5)
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingFrom EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingRating: 4.5 out of 5 stars4.5/5 (21)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldFrom EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldRating: 3 out of 5 stars3/5 (79)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsFrom EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsRating: 4.5 out of 5 stars4.5/5 (3)
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeFrom EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeRating: 4 out of 5 stars4/5 (2)
- Mental Math Secrets - How To Be a Human CalculatorFrom EverandMental Math Secrets - How To Be a Human CalculatorRating: 5 out of 5 stars5/5 (3)
- Making and Tinkering With STEM: Solving Design Challenges With Young ChildrenFrom EverandMaking and Tinkering With STEM: Solving Design Challenges With Young ChildrenNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Limitless Mind: Learn, Lead, and Live Without BarriersFrom EverandLimitless Mind: Learn, Lead, and Live Without BarriersRating: 4 out of 5 stars4/5 (6)
- A Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormFrom EverandA Mathematician's Lament: How School Cheats Us Out of Our Most Fascinating and Imaginative Art FormRating: 4.5 out of 5 stars4.5/5 (20)
- Strategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceFrom EverandStrategies for Problem Solving: Equip Kids to Solve Math Problems With ConfidenceNo ratings yet
- Calculus Workbook For Dummies with Online PracticeFrom EverandCalculus Workbook For Dummies with Online PracticeRating: 3.5 out of 5 stars3.5/5 (8)