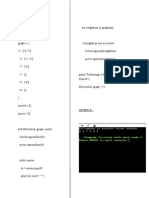
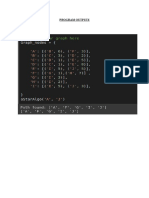
You might also like
- LabDocument25 pagesLabSyed Moizuddin QuadriNo ratings yet
- Aiml LabDocument10 pagesAiml LabTejas SuriNo ratings yet
- 7th Sem LabDocument20 pages7th Sem LabVijay Sathvika BNo ratings yet
- Aiml LabDocument13 pagesAiml LabAishwarya BiradarNo ratings yet
- AI, ML Lab ProgramsDocument1 pageAI, ML Lab ProgramsPoojaNo ratings yet
- Ai Lab ProgramsDocument7 pagesAi Lab Programshetomo5120No ratings yet
- Lab PRGMDocument16 pagesLab PRGMNitesh HuNo ratings yet
- AI and ML LABDocument9 pagesAI and ML LABAkhila RNo ratings yet
- Aiml Lab Manual NcehDocument47 pagesAiml Lab Manual NcehMadhu Chandra B CNo ratings yet
- Artificial Intelligence RecordDocument26 pagesArtificial Intelligence RecordHarishwaran V.No ratings yet
- Implement and Recursively Solve A* and AO* Search AlgorithmsDocument32 pagesImplement and Recursively Solve A* and AO* Search AlgorithmsMohanned AttamimiNo ratings yet
- AIML LabManualDocument25 pagesAIML LabManual4SF19IS072 Preksha AlvaNo ratings yet
- 11Document10 pages11vachanshetty10No ratings yet
- AIML (1st 2 PRGS)Document5 pagesAIML (1st 2 PRGS)Samar FathimaNo ratings yet
- AI-FILE001Document20 pagesAI-FILE001Aditya KashyapNo ratings yet
- A* Algorithm Implementation in PythonDocument4 pagesA* Algorithm Implementation in PythonutkarshNo ratings yet
- Implement A* Search and AO* Search Algorithms (39Document15 pagesImplement A* Search and AO* Search Algorithms (39Shubham KumarNo ratings yet
- Analyze unique values in columnsDocument17 pagesAnalyze unique values in columnsbmbzogfxhbufiwsltuNo ratings yet
- ML Lab Manual PDFDocument9 pagesML Lab Manual PDFAnonymous KvIcYFNo ratings yet
- Ai Practical FileDocument14 pagesAi Practical FileSo JaNo ratings yet
- 15CSL76 StudentsDocument18 pages15CSL76 StudentsYounus KhanNo ratings yet
- 0 AimlfinalDocument24 pages0 Aimlfinalarvindhrk05No ratings yet
- FA16-BCS-178 (AI ASSIGNMENT#2 8puzzle)Document6 pagesFA16-BCS-178 (AI ASSIGNMENT#2 8puzzle)Faran KhalidNo ratings yet
- Ai FileDocument9 pagesAi FileArpit TyagiNo ratings yet
- "Sheikh Fazilatunnesa Mujib University": Computer Science & Engineering (CSE)Document6 pages"Sheikh Fazilatunnesa Mujib University": Computer Science & Engineering (CSE)ashraful islam shihabNo ratings yet
- ML Lab ManualDocument28 pagesML Lab ManualSharan PatilNo ratings yet
- Aiml LabDocument14 pagesAiml Lab1DT19IS146TriveniNo ratings yet
- DAA RecordDocument15 pagesDAA Recorddharun0704No ratings yet
- DAA LabDocument41 pagesDAA Labpalaniperumal041979No ratings yet
- Machine Learning ProgramsDocument17 pagesMachine Learning ProgramsRachana MedehalNo ratings yet
- Aiml Lab Manual 2023Document17 pagesAiml Lab Manual 2023shamilie17No ratings yet
- Program 1Document25 pagesProgram 1Asif BadegharNo ratings yet
- Input of AIDocument7 pagesInput of AIParth IsasareNo ratings yet
- Assignment No: 04: CodeDocument20 pagesAssignment No: 04: CodeVishwakarma UniversityNo ratings yet
- Search Algorithm Assignment !Document12 pagesSearch Algorithm Assignment !anurag.nuweshNo ratings yet
- Exno 1,2Document3 pagesExno 1,2kpramya19No ratings yet
- Ai ML ProgramsDocument34 pagesAi ML ProgramsYasar BilalNo ratings yet
- Implement Depth First Search & Breadth First Search Graph AlgorithmsDocument42 pagesImplement Depth First Search & Breadth First Search Graph AlgorithmsAadarsh YadavNo ratings yet
- GBFS 10 26Document5 pagesGBFS 10 26Mohammad JubayerNo ratings yet
- GBFS 10 21Document5 pagesGBFS 10 21Mohammad JubayerNo ratings yet
- GBFS 10 2Document5 pagesGBFS 10 2Mohammad JubayerNo ratings yet
- GBFS 10 3Document5 pagesGBFS 10 3Mohammad JubayerNo ratings yet
- GBFS 2Document5 pagesGBFS 2Mohammad JubayerNo ratings yet
- GBFS 6Document5 pagesGBFS 6Mohammad JubayerNo ratings yet
- Daa LabDocument22 pagesDaa Labvikas 5G9No ratings yet
- Quiz Pertemuan 3 Dan Pertemuan 4Document10 pagesQuiz Pertemuan 3 Dan Pertemuan 4Adit SanurNo ratings yet
- AIML Lab ManualDocument9 pagesAIML Lab ManualAARUNI RAINo ratings yet
- ML Laboratory Demonstrates Machine Learning AlgorithmsDocument33 pagesML Laboratory Demonstrates Machine Learning AlgorithmsPradyumna A KubearNo ratings yet
- AI For DSDocument15 pagesAI For DSB.C.H. ReddyNo ratings yet
- Jntuk R20 MLDocument43 pagesJntuk R20 MLSushNo ratings yet
- Python Matrix MultiplicationDocument29 pagesPython Matrix Multiplicationsagar panchalNo ratings yet
- ML ManualDocument42 pagesML ManualRafa AnanNo ratings yet
- OutputDocument65 pagesOutputit's technicalNo ratings yet
- Ada Lab FileDocument25 pagesAda Lab FileRishi KumarNo ratings yet
- Document 4Document29 pagesDocument 4RahulNo ratings yet
- ML Lab ImplementationsDocument11 pagesML Lab ImplementationsaakashNo ratings yet
- Lecture 04 - Install Python Dan Searching in PythonDocument10 pagesLecture 04 - Install Python Dan Searching in PythonAdit SanurNo ratings yet
- ABHISHEK CHAUHAN'S AI PRACTICAL SUBMISSIONDocument39 pagesABHISHEK CHAUHAN'S AI PRACTICAL SUBMISSIONZoyaNo ratings yet
- OutputDocument65 pagesOutputit's technicalNo ratings yet
- BDA-Case StudyDocument2 pagesBDA-Case StudyNeeraja RajeshNo ratings yet
- Aiml Lab - Open Ended ExperimentsDocument6 pagesAiml Lab - Open Ended ExperimentsNeeraja RajeshNo ratings yet
- Program OutputsDocument8 pagesProgram OutputsNeeraja RajeshNo ratings yet
- Few AIML Lab Viva QADocument3 pagesFew AIML Lab Viva QANeeraja RajeshNo ratings yet
- Data Mining and Warehousing TopicsDocument6 pagesData Mining and Warehousing TopicsArchana DeviNo ratings yet
- Difference Between CURE Clustering and DBSCAN Clustering - GeeksforGeeksDocument3 pagesDifference Between CURE Clustering and DBSCAN Clustering - GeeksforGeeksRavindra Kumar PrajapatiNo ratings yet
- Thesis On Data Warehousing and Data MiningDocument8 pagesThesis On Data Warehousing and Data Miningaflpcdwfunzfed100% (2)
- Student Performance AnalysisDocument6 pagesStudent Performance AnalysisMohamed BoussakssouNo ratings yet
- Mis Project - BibasDocument39 pagesMis Project - BibasKamlesh NegiNo ratings yet
- Ssignment Achine Earning: Innah Niversity FOR OmenDocument6 pagesSsignment Achine Earning: Innah Niversity FOR OmenAnonymous HTDoUfUgzNo ratings yet
- Data Mining in Higher EducationDocument7 pagesData Mining in Higher EducationgurlergulceNo ratings yet
- MBA 4th Sem MBAIIT1 - SAD - Unit-2 - NotesDocument20 pagesMBA 4th Sem MBAIIT1 - SAD - Unit-2 - NotesvivekkumarsNo ratings yet
- KDD Cup 2009 customer prediction challengeDocument8 pagesKDD Cup 2009 customer prediction challengeBen NgNo ratings yet
- Clarifying The Research Question Through Secondary Data and ExplorationDocument27 pagesClarifying The Research Question Through Secondary Data and Explorationsameer43786No ratings yet
- Software Engineering Unit-3Document25 pagesSoftware Engineering Unit-3balakrishna akulaNo ratings yet
- Data MiningDocument25 pagesData Miningapi-3765947100% (13)
- HMM Credit Card Fraud DetectionDocument20 pagesHMM Credit Card Fraud DetectionvijaybtechNo ratings yet
- Multidimensional Data Mode:-: Characteristics of Data WarehouseDocument26 pagesMultidimensional Data Mode:-: Characteristics of Data Warehousepalprakah100% (1)
- ML 2Document3 pagesML 2suresh reddyNo ratings yet
- 224 Block-3Document129 pages224 Block-3shivam saxenaNo ratings yet
- Chapter 1Document43 pagesChapter 1SanthoshNo ratings yet
- Big Data Mining, and AnalyticsDocument22 pagesBig Data Mining, and AnalyticsAriadna Setentaytres100% (1)
- Undergoverned Spaces: Strong States, Poor ControlDocument3 pagesUndergoverned Spaces: Strong States, Poor ControlJohn A. BertettoNo ratings yet
- Hot Topics For Research Papers in Computer ScienceDocument8 pagesHot Topics For Research Papers in Computer Sciencegz8jpg31No ratings yet
- 9 Selling Predictive AnalyticsDocument25 pages9 Selling Predictive Analyticsvendetta6546No ratings yet
- Reading ListDocument4 pagesReading ListHayley XieNo ratings yet
- Microsoft Machine Learning Algorithm Cheat Sheet v2 PDFDocument1 pageMicrosoft Machine Learning Algorithm Cheat Sheet v2 PDFamitag007100% (1)
- 19 - Sessionppt - ClusteringalgosDocument36 pages19 - Sessionppt - ClusteringalgosGraisy BiswalNo ratings yet
- Applications of Statistics and Probablity To Software EngineeringDocument6 pagesApplications of Statistics and Probablity To Software EngineeringHèñók Mk50% (4)
- ch01 IntroDocument45 pagesch01 IntroEzekiel LohNo ratings yet
- What Motivated Data Mining? Why Is It Important?Document14 pagesWhat Motivated Data Mining? Why Is It Important?Naresh Babu MeruguNo ratings yet
- Analisis Algoritma K-Medoids Clustering Dalam Pengelompokan Penyebaran Covid-19 Di IndonesiaDocument8 pagesAnalisis Algoritma K-Medoids Clustering Dalam Pengelompokan Penyebaran Covid-19 Di IndonesiaKenneth SabandarNo ratings yet
- Enterprise Big Data Framework Guide V1.4 2 PDFDocument121 pagesEnterprise Big Data Framework Guide V1.4 2 PDFJack Chang100% (1)