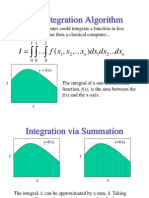
You might also like
- Variance Reduction TechniquesDocument48 pagesVariance Reduction TechniquesjohnqNo ratings yet
- Numerical Solution RL CircuitDocument11 pagesNumerical Solution RL CircuitSachin Kumar Bhoi0% (1)
- Matlab HW PDFDocument3 pagesMatlab HW PDFMohammed AbdulnaserNo ratings yet
- MATLAB Functions for DSPDocument21 pagesMATLAB Functions for DSPRobyNo ratings yet
- Variance Reduction Techniques 1Document48 pagesVariance Reduction Techniques 1Teng PengNo ratings yet
- CmdieDocument8 pagesCmdieBeny AbdouNo ratings yet
- Monte Carlo Methods PDFDocument6 pagesMonte Carlo Methods PDFbhuniakanishkaNo ratings yet
- NLAFull Notes 22Document59 pagesNLAFull Notes 22forspamreceivalNo ratings yet
- CS210 Lect07Document5 pagesCS210 Lect07aleyhaiderNo ratings yet
- Lab Experiment-5 Discrete Cosine Transform/discrete Fourier Transform AimDocument29 pagesLab Experiment-5 Discrete Cosine Transform/discrete Fourier Transform AimVineeth KumarNo ratings yet
- Ejercicio Power MethodDocument2 pagesEjercicio Power MethodAxel Flores ArandaNo ratings yet
- Rep Sol 1701687561892Document11 pagesRep Sol 1701687561892satwikNo ratings yet
- Matlab Examples AE470Document24 pagesMatlab Examples AE470JonyLopezNo ratings yet
- DSP Lab 1 PDFDocument10 pagesDSP Lab 1 PDFSaif HassanNo ratings yet
- Section1 2Document22 pagesSection1 2James WrightNo ratings yet
- HW 5Document5 pagesHW 5Johnathan TuckerNo ratings yet
- Final Project: Power MethodDocument9 pagesFinal Project: Power MethodZhijie TangNo ratings yet
- Lab 1: Model SelectionDocument6 pagesLab 1: Model SelectionthomasverbekeNo ratings yet
- DSP Manual 1Document138 pagesDSP Manual 1sunny407No ratings yet
- Digital Signal ProcessingDocument20 pagesDigital Signal Processingusamadar707No ratings yet
- ENGM541 Lab5 Runge Kutta SimulinkstatespaceDocument5 pagesENGM541 Lab5 Runge Kutta SimulinkstatespaceAbiodun GbengaNo ratings yet
- Seminar Report On Contraction Mapping in Adaptive FiltersDocument14 pagesSeminar Report On Contraction Mapping in Adaptive FiltersSrinivasSunnyNo ratings yet
- Adaptive Filters Guide: Wiener, LMS & RLS Algorithms ExplainedDocument41 pagesAdaptive Filters Guide: Wiener, LMS & RLS Algorithms Explaineddhurgham zwaidNo ratings yet
- DSP Lab Manual 5 Semester Electronics and Communication EngineeringDocument138 pagesDSP Lab Manual 5 Semester Electronics and Communication EngineeringSuguna ShivannaNo ratings yet
- Engineering ComputationDocument16 pagesEngineering ComputationAnonymous oYtSN7SNo ratings yet
- Errors and PropagationDocument8 pagesErrors and PropagationJhon MuñozNo ratings yet
- DSP Lab Manual 5 Semester Electronics and Communication EngineeringDocument147 pagesDSP Lab Manual 5 Semester Electronics and Communication Engineeringrupa_123No ratings yet
- Digital Signal Processing Lab ManualDocument138 pagesDigital Signal Processing Lab Manuals98940359030% (1)
- Monte Carlo BasicsDocument23 pagesMonte Carlo BasicsIon IvanNo ratings yet
- Justin RombergDocument69 pagesJustin RombergNIKHIL SHARMANo ratings yet
- MCG4308 Lec4Document25 pagesMCG4308 Lec4Christian PaultreNo ratings yet
- DSP Lab Sheet 2 PDFDocument50 pagesDSP Lab Sheet 2 PDFSreekrishna DasNo ratings yet
- Signal Processing Lab Convolution QuestionsDocument2 pagesSignal Processing Lab Convolution QuestionsRodrigoNo ratings yet
- TypedDocument5 pagesTypedsaalimNo ratings yet
- Computer Exercise 3 in Stationary Stochastic Processes, HT 21Document9 pagesComputer Exercise 3 in Stationary Stochastic Processes, HT 21David BorgerNo ratings yet
- Lab 15—Power Method for Dominant EigenvalueDocument2 pagesLab 15—Power Method for Dominant EigenvalueKnNan KhowajaNo ratings yet
- Week 3Document81 pagesWeek 3Joceal1989No ratings yet
- Matrix MultDocument6 pagesMatrix Multdaweley389No ratings yet
- Assign2 F15Document5 pagesAssign2 F15Lindsey HoffmanNo ratings yet
- Practical Guide 03 Power SeriesDocument8 pagesPractical Guide 03 Power SeriesEmilNo ratings yet
- Nonlinear Solvers GuideDocument14 pagesNonlinear Solvers GuideRasheed KibriaNo ratings yet
- The Integration Algorithm: DX DX DX X X X F IDocument30 pagesThe Integration Algorithm: DX DX DX X X X F IsuhasnambiarNo ratings yet
- Lab Experiment-3 Karhunen-Loeve TransformDocument6 pagesLab Experiment-3 Karhunen-Loeve TransformVineeth KumarNo ratings yet
- Yt X HT D: Lecture 9: Convolution Evaluation: Continuous Time SystemDocument5 pagesYt X HT D: Lecture 9: Convolution Evaluation: Continuous Time SystemRajat RameshNo ratings yet
- Intro Eigen-Value TypedDocument5 pagesIntro Eigen-Value TypedpathanshamsheerkhanNo ratings yet
- April 2009 FinalDocument10 pagesApril 2009 FinalAdalric LeungNo ratings yet
- Waveform Generation MatlabDocument11 pagesWaveform Generation MatlabArmando CajahuaringaNo ratings yet
- Dimensionality Reduction Unit-5 Dr. H C Vijayalakshmi: Reference 1. AmpleDocument66 pagesDimensionality Reduction Unit-5 Dr. H C Vijayalakshmi: Reference 1. AmpleBatemanNo ratings yet
- Section1 10Document17 pagesSection1 10sonti11No ratings yet
- Signal Processing in MATLABDocument3 pagesSignal Processing in MATLABRadu VancaNo ratings yet
- Computational Lab in Physics: Solving Differential EquationsDocument20 pagesComputational Lab in Physics: Solving Differential Equationsbenefit187No ratings yet
- Homework 3Document6 pagesHomework 3maxNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Factorization of Boundary Value Problems Using the Invariant Embedding MethodFrom EverandFactorization of Boundary Value Problems Using the Invariant Embedding MethodNo ratings yet
- Difference Equations in Normed Spaces: Stability and OscillationsFrom EverandDifference Equations in Normed Spaces: Stability and OscillationsNo ratings yet
- Interactions between Electromagnetic Fields and Matter: Vieweg Tracts in Pure and Applied PhysicsFrom EverandInteractions between Electromagnetic Fields and Matter: Vieweg Tracts in Pure and Applied PhysicsNo ratings yet
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"From EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Rating: 2.5 out of 5 stars2.5/5 (2)
- Calendario Evaluacion ContinuaDocument1 pageCalendario Evaluacion ContinuaMarisnelvys CabrejaNo ratings yet
- Exercise Sheet 0Document1 pageExercise Sheet 0Marisnelvys CabrejaNo ratings yet
- 00ojo Heat Ecuation and Convection DiffusionDocument10 pages00ojo Heat Ecuation and Convection DiffusionMarisnelvys CabrejaNo ratings yet
- Programa inDocument3 pagesPrograma inMarisnelvys CabrejaNo ratings yet
- Applied Discrete Mathematics - Graph Theory and ApplicationsDocument2 pagesApplied Discrete Mathematics - Graph Theory and ApplicationsMarisnelvys CabrejaNo ratings yet
- Practice 24 25Document10 pagesPractice 24 25Marisnelvys CabrejaNo ratings yet
- Practice 16 17 18Document13 pagesPractice 16 17 18Marisnelvys CabrejaNo ratings yet
- Practice 11 12Document27 pagesPractice 11 12Marisnelvys CabrejaNo ratings yet
- Spectra of GraphsDocument256 pagesSpectra of GraphsMarisnelvys CabrejaNo ratings yet
- Team Performance ReviewDocument7 pagesTeam Performance ReviewMarisnelvys CabrejaNo ratings yet
- Practice 6 8Document12 pagesPractice 6 8Marisnelvys CabrejaNo ratings yet
- Practice 21 22 23Document8 pagesPractice 21 22 23Marisnelvys CabrejaNo ratings yet
- Problems 5Document14 pagesProblems 5Marisnelvys CabrejaNo ratings yet
- Practice 4Document7 pagesPractice 4Marisnelvys CabrejaNo ratings yet
- Crecimiento AlgDocument27 pagesCrecimiento AlgMarisnelvys CabrejaNo ratings yet
- How To Use Compress.mDocument1 pageHow To Use Compress.mMarisnelvys CabrejaNo ratings yet
- Matlab Code GrowthDocument16 pagesMatlab Code GrowthMarisnelvys CabrejaNo ratings yet
- Assignment 04Document5 pagesAssignment 04Marisnelvys CabrejaNo ratings yet
- 13 Solary r159 Vol 5 Issue 1Document14 pages13 Solary r159 Vol 5 Issue 1Marisnelvys CabrejaNo ratings yet
- Bernstein Sato NotesDocument44 pagesBernstein Sato NotesMarisnelvys CabrejaNo ratings yet
- Sensitivities of Eigenvalues and Eigenvectors of PDocument5 pagesSensitivities of Eigenvalues and Eigenvectors of PMarisnelvys CabrejaNo ratings yet
- Introduction to Jupyter Notebook - Practice Markdown and Python CellsDocument7 pagesIntroduction to Jupyter Notebook - Practice Markdown and Python CellsMarisnelvys CabrejaNo ratings yet
- HaarDocument6 pagesHaarMarisnelvys CabrejaNo ratings yet
- Estudiar Growth FactorDocument17 pagesEstudiar Growth FactorMarisnelvys CabrejaNo ratings yet
- 2 Introduction - IpynbDocument19 pages2 Introduction - IpynbMarisnelvys CabrejaNo ratings yet
- 8 Sample - Notebook - No - Code ( - No-Input Option)Document3 pages8 Sample - Notebook - No - Code ( - No-Input Option)Marisnelvys CabrejaNo ratings yet
- 14 Chebyshev PolynomialsDocument8 pages14 Chebyshev PolynomialsMarisnelvys CabrejaNo ratings yet
- 7 Sample - Notebook - With - Code - CellsDocument5 pages7 Sample - Notebook - With - Code - CellsMarisnelvys CabrejaNo ratings yet
- 1 Planificacion SemanalDocument1 page1 Planificacion SemanalMarisnelvys CabrejaNo ratings yet
- Scilab08 PDFDocument73 pagesScilab08 PDFJared GasparNo ratings yet
- Logarithmic FunctionsDocument16 pagesLogarithmic FunctionsJjrlNo ratings yet
- JEE MAIN 2021: Most Repeated Topics MATH Detailed AnalysisDocument36 pagesJEE MAIN 2021: Most Repeated Topics MATH Detailed AnalysisHarsh ShahNo ratings yet
- Solve Linear PDEsDocument4 pagesSolve Linear PDEsKeshav BajpaiNo ratings yet
- Ex. 2c Express in Logarithmic Form A) B) C) D) E) F) G) H)Document15 pagesEx. 2c Express in Logarithmic Form A) B) C) D) E) F) G) H)Alex noslenNo ratings yet
- Buckingham ModelDocument3 pagesBuckingham ModelFatma RajabNo ratings yet
- 2020 Kings College Budo s4 Mathematics Paper 1 Pre Uneb Test 2Document5 pages2020 Kings College Budo s4 Mathematics Paper 1 Pre Uneb Test 2Okiring JonahNo ratings yet
- Week 3: Lectures 8-9 Derivatives and Anti-Derivatives: Some Techniques With ExamplesDocument14 pagesWeek 3: Lectures 8-9 Derivatives and Anti-Derivatives: Some Techniques With ExamplesKristel AndreaNo ratings yet
- MODES OF OSCILLATIONDocument3 pagesMODES OF OSCILLATIONpaul catalinNo ratings yet
- 1 Ren APl HDocument350 pages1 Ren APl HKao SophearakNo ratings yet
- Law of SinesDocument17 pagesLaw of SinesJOSH ELORDENo ratings yet
- MT129 TMA Fall 2023-2024Document7 pagesMT129 TMA Fall 2023-2024Khalid233No ratings yet
- 3D TransformationDocument73 pages3D TransformationEr RishabNo ratings yet
- Formula Sheet For EE406: N N N N NDocument7 pagesFormula Sheet For EE406: N N N N NCFANo ratings yet
- 2019-20 F5 MAT Yearly Exam Paper 1 (Long Question)Document18 pages2019-20 F5 MAT Yearly Exam Paper 1 (Long Question)Winnie ChauNo ratings yet
- CU-2021 B.sc. (Honours) Mathematics Semester-1 Paper-CC-1 QPDocument4 pagesCU-2021 B.sc. (Honours) Mathematics Semester-1 Paper-CC-1 QPMy MathNo ratings yet
- Question Bank FEM Analysis and SolutionDocument12 pagesQuestion Bank FEM Analysis and SolutionShivam ChoudharyNo ratings yet
- CH 3. DerivativesDocument62 pagesCH 3. DerivativesHenry DunaNo ratings yet
- 2016-03-31 The Incenter-Excenter Lemma, by Evan Chen PDFDocument4 pages2016-03-31 The Incenter-Excenter Lemma, by Evan Chen PDFAngela Angie BuseskaNo ratings yet
- Assignment No.2 L.ADocument2 pagesAssignment No.2 L.ABilal KhanNo ratings yet
- Notes On Fast Fourier Transform Algorithms & Data StructuresDocument11 pagesNotes On Fast Fourier Transform Algorithms & Data Structures"The Dangerous One"No ratings yet
- 430258214maths Psa Quantitative Aptitude For Class Ix and X 2014-15Document95 pages430258214maths Psa Quantitative Aptitude For Class Ix and X 2014-15jpsmu09100% (1)
- Complex Number DPP (1 To 6)Document12 pagesComplex Number DPP (1 To 6)Shashank MittalNo ratings yet
- 3101 (Real Analysis)Document1 page3101 (Real Analysis)api-3808925No ratings yet
- Sample Question Papers - Maths Problems and SolutionsDocument49 pagesSample Question Papers - Maths Problems and SolutionsABCNo ratings yet
- Abstract Algebra ExplainedDocument30 pagesAbstract Algebra Explainedyu yuanNo ratings yet
- Geometric TransformationsDocument40 pagesGeometric TransformationssfundsNo ratings yet
- Factors and MultiplesDocument9 pagesFactors and MultipleschrisNo ratings yet
- Continuity and Discontinuity of FunctionsDocument27 pagesContinuity and Discontinuity of FunctionsKristyn GeraldezNo ratings yet
- Introduction To Tensor Calculus and Continuum Mechanics (J PDFDocument366 pagesIntroduction To Tensor Calculus and Continuum Mechanics (J PDFJhames Huarachi YarariNo ratings yet