You might also like
- A Survey of An Adaptive Weighted Spatio-Temporal Pyramid Matching For Video RetrievalDocument3 pagesA Survey of An Adaptive Weighted Spatio-Temporal Pyramid Matching For Video Retrievalseventhsensegroup100% (1)
- Video Summarization and Retrieval Using Singular Value DecompositionDocument12 pagesVideo Summarization and Retrieval Using Singular Value DecompositionIAGPLSNo ratings yet
- Gong2003 Article SummarizingAudiovisualContentsDocument10 pagesGong2003 Article SummarizingAudiovisualContentsQuintin NiemsykNo ratings yet
- Automated Video Summarization Using Speech TranscriptsDocument12 pagesAutomated Video Summarization Using Speech TranscriptsBryanNo ratings yet
- Accepted Manuscript: J. Vis. Commun. Image RDocument47 pagesAccepted Manuscript: J. Vis. Commun. Image RANSHY SINGHNo ratings yet
- Frame Recognize by De-Redundancy AlgorithmDocument5 pagesFrame Recognize by De-Redundancy Algorithmsugar cubeNo ratings yet
- sensors-23-03384-v2Document15 pagessensors-23-03384-v2sayko3233No ratings yet
- An Image-Based Approach To Video Copy Detection With Spatio-Temporal Post-FilteringDocument10 pagesAn Image-Based Approach To Video Copy Detection With Spatio-Temporal Post-FilteringAchuth VishnuNo ratings yet
- A Novel Clustering Method For Static Video SummarizationDocument17 pagesA Novel Clustering Method For Static Video SummarizationHussain DawoodNo ratings yet
- AI-based Video Summarization Using FFmpeg and NLPDocument6 pagesAI-based Video Summarization Using FFmpeg and NLPInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Semantic Text Summarization of Long Videos: March 2017Document10 pagesSemantic Text Summarization of Long Videos: March 2017AnanyaNo ratings yet
- 5.5.2 Video To Text With LSTM ModelsDocument10 pages5.5.2 Video To Text With LSTM ModelsNihal ReddyNo ratings yet
- Ibook - Pub Crowd Aware Summarization of Surveillance Videos by Deep Reinforcement LearningDocument21 pagesIbook - Pub Crowd Aware Summarization of Surveillance Videos by Deep Reinforcement LearningANSHY SINGHNo ratings yet
- An Image-Based Approach To Video Copy Detection With Spatio-Temporal Post-FilteringDocument27 pagesAn Image-Based Approach To Video Copy Detection With Spatio-Temporal Post-FilteringAchuth VishnuNo ratings yet
- Rank Pooling For Action RecognitionDocument4 pagesRank Pooling For Action RecognitionAnonymous 1aqlkZNo ratings yet
- Synopsis On: Video SummarizationDocument11 pagesSynopsis On: Video SummarizationGaurav YadavNo ratings yet
- Applsci 11 05260 v2Document17 pagesApplsci 11 05260 v2Tania ChakrabortyNo ratings yet
- Moving Object Based Collision-Free Video SynopsisDocument7 pagesMoving Object Based Collision-Free Video SynopsisHassaan AhmedNo ratings yet
- Superframes, A Temporal Video SegmentationDocument6 pagesSuperframes, A Temporal Video SegmentationAp MllNo ratings yet
- 978-1-4244-4318-5/09/$25.00 C °2009 IEEE 3DTV-CON 2009Document4 pages978-1-4244-4318-5/09/$25.00 C °2009 IEEE 3DTV-CON 2009lido1500No ratings yet
- Video Database: Role of Video Feature ExtractionDocument5 pagesVideo Database: Role of Video Feature Extractionmulayam singh yadavNo ratings yet
- Video Summarization Using Deep Semantic FeaturesDocument16 pagesVideo Summarization Using Deep Semantic FeaturessauravguptaaaNo ratings yet
- A Survey On Visual Content-Based Video Indexing and RetrievalDocument23 pagesA Survey On Visual Content-Based Video Indexing and RetrievalGS Naveen KumarNo ratings yet
- Temporal Feature Induction For Baseball Highlight ClassificationDocument4 pagesTemporal Feature Induction For Baseball Highlight ClassificationSammer HamidNo ratings yet
- Key-Shots Based Video Summarization by Applying Self-Attention MechanismDocument7 pagesKey-Shots Based Video Summarization by Applying Self-Attention Mechanismrock starNo ratings yet
- A Review Enhancement of Degraded VideoDocument4 pagesA Review Enhancement of Degraded VideoEditor IJRITCCNo ratings yet
- Ijcsit2015060459 PDFDocument6 pagesIjcsit2015060459 PDFAnonymous VVUp0Q4oeFNo ratings yet
- A Graph-Based Ranking Approach To Extract Key-FramesDocument15 pagesA Graph-Based Ranking Approach To Extract Key-Framessugar cubeNo ratings yet
- Key-Frame Detection in Raw Video StreamsDocument10 pagesKey-Frame Detection in Raw Video StreamsQuốc ThắngNo ratings yet
- A New Hybrid Algorithm For Video SegmentationDocument5 pagesA New Hybrid Algorithm For Video SegmentationiirNo ratings yet
- Enhancing Security in A Video Copy Detection System Using Content Based FingerprintingDocument7 pagesEnhancing Security in A Video Copy Detection System Using Content Based FingerprintingIJMERNo ratings yet
- MIT DriveSeg ManualDocument5 pagesMIT DriveSeg ManualsummrinaNo ratings yet
- Efficient and Robust Video Compression Using Huffman CodingDocument4 pagesEfficient and Robust Video Compression Using Huffman CodingRizal Endar WibowoNo ratings yet
- Identifying Worst and Best Drugs Using Association Rule MiningDocument7 pagesIdentifying Worst and Best Drugs Using Association Rule Miningleo MessiNo ratings yet
- Efficient Hierarchical Graph-Based Video Segmentation: Matthias Grundmann Vivek Kwatra Mei Han Irfan EssaDocument8 pagesEfficient Hierarchical Graph-Based Video Segmentation: Matthias Grundmann Vivek Kwatra Mei Han Irfan EssaPadmapriya SubramanianNo ratings yet
- Action Event Retrieval From Cricket Video Using Audio Energy Feature For Event SummarizationDocument8 pagesAction Event Retrieval From Cricket Video Using Audio Energy Feature For Event SummarizationIAEME PublicationNo ratings yet
- A Survey On The Automatic Indexing of Video Data 1999 Journal of Visual Communication and Image RepresentationDocument35 pagesA Survey On The Automatic Indexing of Video Data 1999 Journal of Visual Communication and Image RepresentationSandeep SharmaNo ratings yet
- Video:: Query-Focused Video Summarization: Dataset, Evaluation, and A Memory Network Based ApproachDocument2 pagesVideo:: Query-Focused Video Summarization: Dataset, Evaluation, and A Memory Network Based ApproachMark TallyNo ratings yet
- Video DetectionDocument4 pagesVideo DetectionJournalNX - a Multidisciplinary Peer Reviewed JournalNo ratings yet
- Efficient Storage and Analysis of Videos Through MDocument8 pagesEfficient Storage and Analysis of Videos Through Manshupriya380No ratings yet
- Survey On Recent Techniques in Content Based Video RetrievalDocument5 pagesSurvey On Recent Techniques in Content Based Video RetrievalerpublicationNo ratings yet
- Stephen W. Smoliar, Hongliang Zhang - Content Based Video Indexing and Retrieval (1994)Document11 pagesStephen W. Smoliar, Hongliang Zhang - Content Based Video Indexing and Retrieval (1994)more_than_a_dreamNo ratings yet
- JPSP - 2022 - 115Document6 pagesJPSP - 2022 - 115Karunya ChavanNo ratings yet
- Iccv 2005 86Document8 pagesIccv 2005 86zhaobingNo ratings yet
- Video Summarization Using Deep Neural Networks: A SurveyDocument26 pagesVideo Summarization Using Deep Neural Networks: A SurveyLaith QasemNo ratings yet
- Diba DynamoNet Dynamic Action and Motion Network ICCV 2019 PaperDocument10 pagesDiba DynamoNet Dynamic Action and Motion Network ICCV 2019 PaperGG GENo ratings yet
- Video Captioning Using Neural NetworksDocument13 pagesVideo Captioning Using Neural NetworksIJRASETPublicationsNo ratings yet
- MISvdbmsDocument10 pagesMISvdbmsNeba Neba NebaNo ratings yet
- Video To SequenceDocument9 pagesVideo To SequenceUtkarsh SaxenaNo ratings yet
- Video Summarization Using Fully Convolutional Sequence NetworksDocument17 pagesVideo Summarization Using Fully Convolutional Sequence NetworksDavid DivadNo ratings yet
- Ijecet: International Journal of Electronics and Communication Engineering & Technology (Ijecet)Document9 pagesIjecet: International Journal of Electronics and Communication Engineering & Technology (Ijecet)IAEME PublicationNo ratings yet
- Summarization of Web Videos by Tag Localization and Key Shot IdentificationDocument17 pagesSummarization of Web Videos by Tag Localization and Key Shot IdentificationBala KrishnanNo ratings yet
- Anjum 2017 Cloud-Based Scalable Object Detection and Classification in Video Streams AcceptedDocument35 pagesAnjum 2017 Cloud-Based Scalable Object Detection and Classification in Video Streams AcceptedVanathi AndiranNo ratings yet
- Video Liveness VerificationDocument4 pagesVideo Liveness VerificationEditor IJTSRDNo ratings yet
- Summarization of Wireless Capsule Endoscopy Video Using Deep Feature Matching and Motion AnalysisDocument13 pagesSummarization of Wireless Capsule Endoscopy Video Using Deep Feature Matching and Motion AnalysisDavid DivadNo ratings yet
- A Survey of Alignment Methods Used For Motion Based Video SequencesDocument3 pagesA Survey of Alignment Methods Used For Motion Based Video SequencesseventhsensegroupNo ratings yet
- Engineering Journal A Fire Fly Optimization Based Video Object Co-SegmentationDocument7 pagesEngineering Journal A Fire Fly Optimization Based Video Object Co-SegmentationEngineering JournalNo ratings yet
- Janwe 2017Document20 pagesJanwe 2017PRABHAKARANNo ratings yet
- VLSI Design for Video Coding: H.264/AVC Encoding from Standard Specification to ChipFrom EverandVLSI Design for Video Coding: H.264/AVC Encoding from Standard Specification to ChipNo ratings yet
- Summarization of Wireless Capsule Endoscopy Video Using Deep Feature Matching and Motion AnalysisDocument13 pagesSummarization of Wireless Capsule Endoscopy Video Using Deep Feature Matching and Motion AnalysisDavid DivadNo ratings yet
- Surface ReConstruction of Dicom Images FinalDocument8 pagesSurface ReConstruction of Dicom Images FinalDavid DivadNo ratings yet
- Nlp-Enriched Automatic Video Segmentation: Mohannad Almousa Rachid Benlamri Richard KhouryDocument6 pagesNlp-Enriched Automatic Video Segmentation: Mohannad Almousa Rachid Benlamri Richard KhouryDavid DivadNo ratings yet
- Video Summarization Using Fully Convolutional Sequence NetworksDocument17 pagesVideo Summarization Using Fully Convolutional Sequence NetworksDavid DivadNo ratings yet
- Activity No.1 in GED 103Document2 pagesActivity No.1 in GED 103Kenneth HerreraNo ratings yet
- POLE FOUNDATION ANALYSIS EXCEL TOOLDocument18 pagesPOLE FOUNDATION ANALYSIS EXCEL TOOLJosue HasbunNo ratings yet
- Modern Tips For The Modern Witch (/)Document5 pagesModern Tips For The Modern Witch (/)Rori sNo ratings yet
- Ch1 - A Perspective On TestingDocument41 pagesCh1 - A Perspective On TestingcnshariffNo ratings yet
- Eugene A. Nida - Theories of TranslationDocument15 pagesEugene A. Nida - Theories of TranslationYohanes Eko Portable100% (2)
- Autochief® C20: Engine Control and Monitoring For General ElectricDocument2 pagesAutochief® C20: Engine Control and Monitoring For General ElectricВадим ГаранNo ratings yet
- Fif-12 Om Eng Eaj23x102Document13 pagesFif-12 Om Eng Eaj23x102Schefer FabianNo ratings yet
- EDCO - Catalog - 8 - 2017 - Floor GrindingDocument64 pagesEDCO - Catalog - 8 - 2017 - Floor GrindinghrithikvNo ratings yet
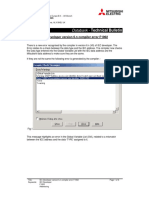
- IEC Developer version 6.n compiler error F1002Document6 pagesIEC Developer version 6.n compiler error F1002AnddyNo ratings yet
- Materiality of Cultural ConstructionDocument3 pagesMateriality of Cultural ConstructionPaul YeboahNo ratings yet
- Substation Automation HandbookDocument454 pagesSubstation Automation HandbookGiancarloEle100% (6)
- Engine Cpta Czca Czea Ea211 EngDocument360 pagesEngine Cpta Czca Czea Ea211 EngleuchiNo ratings yet
- Alfa Laval DecanterDocument16 pagesAlfa Laval DecanterAKSHAY BHATKARNo ratings yet
- ZFDC 20 1HDocument1 pageZFDC 20 1Hkentier21No ratings yet
- Development of Science in Africa - CoverageDocument2 pagesDevelopment of Science in Africa - CoverageJose JeramieNo ratings yet
- Otimizar Windows 8Document2 pagesOtimizar Windows 8ClaudioManfioNo ratings yet
- Synopsis On Training & DevelopmentDocument6 pagesSynopsis On Training & DevelopmentArchi gupta86% (14)
- Methodology of Legal Research: Challenges and OpportunitiesDocument8 pagesMethodology of Legal Research: Challenges and OpportunitiesBhan WatiNo ratings yet
- Mass TransportationDocument20 pagesMass Transportationyoyo_8998No ratings yet
- Awareness On Biomedical Waste Management Among Dental Students - A Cross Sectional Questionnaire SurveyDocument8 pagesAwareness On Biomedical Waste Management Among Dental Students - A Cross Sectional Questionnaire SurveyIJAR JOURNALNo ratings yet
- Pore and Formation PressureDocument4 pagesPore and Formation PressureramadhanipdNo ratings yet
- METAPHYSICAL POETRY A SummaryDocument3 pagesMETAPHYSICAL POETRY A Summaryrcschoolofenglish1No ratings yet
- Advantages of Chain Grate Stokers: Dept of Mechanical Engg, NitrDocument3 pagesAdvantages of Chain Grate Stokers: Dept of Mechanical Engg, NitrRameshNo ratings yet
- A320 - Command Upgrade - Trainee1 01 Jan 24Document19 pagesA320 - Command Upgrade - Trainee1 01 Jan 24Ankit YadavNo ratings yet
- BERGSTROM, Karl Jones. Playing For Togetherness (Tese)Document127 pagesBERGSTROM, Karl Jones. Playing For Togetherness (Tese)Goshai DaianNo ratings yet
- DIK 18A Intan Suhariani 218112100 CJR Research MethodologyDocument9 pagesDIK 18A Intan Suhariani 218112100 CJR Research MethodologyFadli RafiNo ratings yet
- IGNOU - Examination Form AcknowledgementDocument2 pagesIGNOU - Examination Form Acknowledgementsinghabhithakur111No ratings yet
- Dcs Ict2113 (Apr22) - LabDocument6 pagesDcs Ict2113 (Apr22) - LabMarwa NajemNo ratings yet
- Trends and Fads in Business SVDocument2 pagesTrends and Fads in Business SVMarie-Anne DentzerNo ratings yet
- Lesson Plan Sir MarcosDocument7 pagesLesson Plan Sir MarcosJhon AgustinNo ratings yet