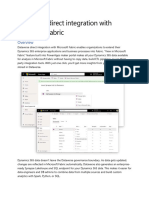
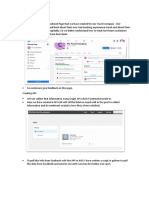
You might also like
- Azure DatalakeDocument8 pagesAzure DatalakeRahaman AbdulNo ratings yet
- On Premises Gateway Monitoring1Document12 pagesOn Premises Gateway Monitoring1abacusdotcomNo ratings yet
- Tera Data 1222Document59 pagesTera Data 1222ravi90No ratings yet
- ADF+Course+deckDocument88 pagesADF+Course+deckclouditlab9No ratings yet
- Introduction To Informatica PowercenterDocument58 pagesIntroduction To Informatica Powercenterr.thogitiNo ratings yet
- DataGrokr DevOps Intern Assignment - 20210129Document3 pagesDataGrokr DevOps Intern Assignment - 20210129msdkfhNo ratings yet
- Informatica8.6 New FeaturesDocument5 pagesInformatica8.6 New FeaturesTulasi KonduruNo ratings yet
- Informatica 8Document7 pagesInformatica 8peruri64No ratings yet
- AWS Solutions Architect Certification Case Based Practice Questions Latest Edition 2023From EverandAWS Solutions Architect Certification Case Based Practice Questions Latest Edition 2023No ratings yet
- MICROSOFT AZURE ADMINISTRATOR EXAM PREP(AZ-104) Part-3: AZ 104 EXAM STUDY GUIDEFrom EverandMICROSOFT AZURE ADMINISTRATOR EXAM PREP(AZ-104) Part-3: AZ 104 EXAM STUDY GUIDENo ratings yet
- Optimize BO Report PerformanceDocument51 pagesOptimize BO Report PerformancepavansuhaneyNo ratings yet
- First, Let Us Look Into The Question What Are Performance Issues in A Report?Document24 pagesFirst, Let Us Look Into The Question What Are Performance Issues in A Report?Amit SethiNo ratings yet
- HowTo MDGMaMaintenanceforMultiple MaterialsDocument37 pagesHowTo MDGMaMaintenanceforMultiple MaterialsSuraj ShahNo ratings yet
- Openreports-Install-Guide-1 0Document19 pagesOpenreports-Install-Guide-1 0george100% (2)
- 70-450: Pro:Microsoft Desktop Support ConsumerDocument78 pages70-450: Pro:Microsoft Desktop Support ConsumerSubramanian KNo ratings yet
- July 2011 Master of Computer Application (MCA) - Semester 5 MC0081 - . (DOT) Net Technologies - 4 CreditsDocument8 pagesJuly 2011 Master of Computer Application (MCA) - Semester 5 MC0081 - . (DOT) Net Technologies - 4 CreditsVikas KumarNo ratings yet
- TakingInterviwDocument15 pagesTakingInterviwA MISHRANo ratings yet
- SRS - How to build a Pen Test and Hacking PlatformFrom EverandSRS - How to build a Pen Test and Hacking PlatformRating: 2 out of 5 stars2/5 (1)
- SAP BO Admin QuestionsDocument4 pagesSAP BO Admin QuestionsKiran KumarNo ratings yet
- Imp FAQs1Document94 pagesImp FAQs1Govardhan AgamaNo ratings yet
- BOQuestionnaireDocument7 pagesBOQuestionnaireMangesh ChakurkarNo ratings yet
- GlossaryDocument16 pagesGlossaryapi-3727445No ratings yet
- Alcatel-Lucent Extended Communication Server Active Directory Synchronization - Installation and AdministrationDocument12 pagesAlcatel-Lucent Extended Communication Server Active Directory Synchronization - Installation and AdministrationKenza LazrakNo ratings yet
- StretchDB 1.0Document4 pagesStretchDB 1.0Jose WalkerNo ratings yet
- Cognos BI Best PracticesDocument19 pagesCognos BI Best PracticesSanthosh ANo ratings yet
- BW Glossary, Definitions & Explanations: A AggregateDocument11 pagesBW Glossary, Definitions & Explanations: A AggregateztanauliNo ratings yet
- Sync Kit: A Persistent Client-Side Database Caching Toolkit For Data Intensive WebsitesDocument11 pagesSync Kit: A Persistent Client-Side Database Caching Toolkit For Data Intensive Websitesdavid toheaNo ratings yet
- Informatica Power Center 9.0.1: Informatica Reporting and Object Migration Part I Lab#36Document23 pagesInformatica Power Center 9.0.1: Informatica Reporting and Object Migration Part I Lab#36Amit Sharma100% (1)
- Question #1topic 1: Hide Solution DiscussionDocument74 pagesQuestion #1topic 1: Hide Solution DiscussionBaji TulluruNo ratings yet
- Data Integration With Ms FabricDocument12 pagesData Integration With Ms Fabricpeej cckNo ratings yet
- Best Practices For Operating Containers: Use The Native Logging Mechanisms of ContainersDocument12 pagesBest Practices For Operating Containers: Use The Native Logging Mechanisms of ContainersRoman PotapovNo ratings yet
- A 9 New FeaturesDocument3 pagesA 9 New Featuresperuri64No ratings yet
- Share Point Diagnostics ToolDocument22 pagesShare Point Diagnostics ToolRekha JainNo ratings yet
- Open Catalog Interface (OCI) - Open Icecat XML and Full Icecat XML RepositoriesDocument27 pagesOpen Catalog Interface (OCI) - Open Icecat XML and Full Icecat XML RepositoriesBittuKmrNo ratings yet
- Cloud Readiness Tool - User Guide PDFDocument8 pagesCloud Readiness Tool - User Guide PDFRavi KumarNo ratings yet
- Chris Olinger, D-Wise Technologies, Inc., Raleigh, NC Tim Weeks, SAS Institute, Inc., Cary, NCDocument20 pagesChris Olinger, D-Wise Technologies, Inc., Raleigh, NC Tim Weeks, SAS Institute, Inc., Cary, NCクマー ヴィーンNo ratings yet
- MKPL MicrosoftSQLMetadatatoCatalog 180219 1849 1876Document12 pagesMKPL MicrosoftSQLMetadatatoCatalog 180219 1849 1876Ahsan FarooquiNo ratings yet
- What Is Caching?: 1. Page Level Output CachingDocument7 pagesWhat Is Caching?: 1. Page Level Output Cachingaravinddasa715No ratings yet
- AthnaDocument13 pagesAthnak2shNo ratings yet
- Enable tracing for BI applicationsDocument6 pagesEnable tracing for BI applicationsPrasad PrasadNo ratings yet
- The Ins and Outs of SAS® Data Integration StudioDocument16 pagesThe Ins and Outs of SAS® Data Integration StudioLemuel OrtegaNo ratings yet
- Advantage Database ServerDocument11 pagesAdvantage Database ServerhassaneinNo ratings yet
- CCB Sample Reports and BI Publisher Configuration PDFDocument19 pagesCCB Sample Reports and BI Publisher Configuration PDFasifsubhanNo ratings yet
- Contact Info for Dallas OfficeDocument3 pagesContact Info for Dallas OfficeJoseilton CavalcanteNo ratings yet
- InformaticalakshmiDocument15 pagesInformaticalakshmiMahidhar LeoNo ratings yet
- PowerBuilder Online Courses MasterDocument125 pagesPowerBuilder Online Courses MastershaouluNo ratings yet
- The Informed Company: How to Build Modern Agile Data Stacks that Drive Winning InsightsFrom EverandThe Informed Company: How to Build Modern Agile Data Stacks that Drive Winning InsightsNo ratings yet
- SQL LectureDocument23 pagesSQL LectureJai PrakashNo ratings yet
- Change Document Log Reporting ECC and BWDocument4 pagesChange Document Log Reporting ECC and BWs.zeraoui1595No ratings yet
- Delphi - Database Design PrimerDocument6 pagesDelphi - Database Design Primernaxo128No ratings yet
- Download: Choosing A Caching TechnologyDocument12 pagesDownload: Choosing A Caching Technologyrws1000No ratings yet
- ITSGHD190209 - Open Text Archive Server Installation With SQL DatabaseDocument27 pagesITSGHD190209 - Open Text Archive Server Installation With SQL Databasesuman nalbolaNo ratings yet
- Using The BigQuery Datasource - Preview User Guide-V2Document29 pagesUsing The BigQuery Datasource - Preview User Guide-V2coreylwyNo ratings yet
- CCF Usage ManualDocument8 pagesCCF Usage ManualAshutosh KumarNo ratings yet
- Make use of an example to explain the significance of XML over the web developmentDocument5 pagesMake use of an example to explain the significance of XML over the web developmentkushkruthik555No ratings yet
- Scala Akka AssignmentDocument4 pagesScala Akka AssignmentTejaswiniNo ratings yet
- Optimize Cognos Query Performance with Best PracticesDocument11 pagesOptimize Cognos Query Performance with Best PracticesPreethy SenthilNo ratings yet
- File FormatDocument1 pageFile FormatAswinNo ratings yet
- Big Data Analytics Options On AWSDocument55 pagesBig Data Analytics Options On AWSmanaskanukurthi100% (1)
- Informatica DemoDocument8 pagesInformatica DemoAswinNo ratings yet
- Analytics Workshop Redshift NotebookDocument6 pagesAnalytics Workshop Redshift NotebookAswinNo ratings yet
- Valorant CapstoneprjDocument3 pagesValorant CapstoneprjAswinNo ratings yet
- AWS - Account Creation ProcedureDocument17 pagesAWS - Account Creation ProcedureAswinNo ratings yet
- FB To s3 PartDocument3 pagesFB To s3 PartAswinNo ratings yet
- Oracle Dba SunilDocument4 pagesOracle Dba SunilAswinNo ratings yet
- Create HR User and EMP TableDocument2 pagesCreate HR User and EMP TableAswinNo ratings yet
- Danica Seleskovitch-Mariann A Lederer: Interpréter Pour TraduireDocument17 pagesDanica Seleskovitch-Mariann A Lederer: Interpréter Pour TraduireGarima KukrejaNo ratings yet
- Structural Crack Identification in Railway Prestressed Concrete Sleepers Using Dynamic Mode ShapesDocument3 pagesStructural Crack Identification in Railway Prestressed Concrete Sleepers Using Dynamic Mode ShapesNii DmNo ratings yet
- Government of India Sponsored Study on Small Industries Potential in Sultanpur DistrictDocument186 pagesGovernment of India Sponsored Study on Small Industries Potential in Sultanpur DistrictNisar Ahmed Ansari100% (1)
- The PersonalityDocument7 pagesThe PersonalityMeris dawatiNo ratings yet
- Effect of In-Store Shelf Spacing On PurchaseDocument20 pagesEffect of In-Store Shelf Spacing On Purchasesiddeshsai54458No ratings yet
- ENG302 Part 2Document7 pagesENG302 Part 2Oğuzhan DalkılıçNo ratings yet
- A Guide For School LeadersDocument28 pagesA Guide For School LeadersIsam Al HassanNo ratings yet
- Contingency PlanDocument1 pageContingency PlanPramod Bodne100% (3)
- Ici-Ultratech Build Beautiful Award For Homes: Indian Concrete InstituteDocument6 pagesIci-Ultratech Build Beautiful Award For Homes: Indian Concrete InstituteRavi NairNo ratings yet
- Time: 3 Hours Total Marks: 100: Printed Page 1 of 2 Sub Code: KEE302Document2 pagesTime: 3 Hours Total Marks: 100: Printed Page 1 of 2 Sub Code: KEE302AvinäshShärmaNo ratings yet
- Einstein and Oppenheimer's Real Relationship Was Cordial and Complicated Vanity FairDocument1 pageEinstein and Oppenheimer's Real Relationship Was Cordial and Complicated Vanity FairrkwpytdntjNo ratings yet
- Autodesk Revit 2014 ContentDocument6 pagesAutodesk Revit 2014 ContentGatot HardiyantoNo ratings yet
- Economical Operation of Nuclear PlantsDocument10 pagesEconomical Operation of Nuclear PlantsArun PatilNo ratings yet
- Cegep Linear Algebra ProblemsDocument92 pagesCegep Linear Algebra Problemsham.karimNo ratings yet
- Tecnair Close Control Catalog 0213Document36 pagesTecnair Close Control Catalog 0213Uzman HassanNo ratings yet
- 10.6 Heat Conduction Through Composite WallsDocument35 pages10.6 Heat Conduction Through Composite WallsEngr Muhammad AqibNo ratings yet
- 722.6 Transmission Conductor Plate Replacement DIYDocument3 pages722.6 Transmission Conductor Plate Replacement DIYcamaro67427100% (1)
- Lesson Plan Nº1Document7 pagesLesson Plan Nº1Veronica OrpiNo ratings yet
- Water Supply PDFDocument18 pagesWater Supply PDFtechnicalvijayNo ratings yet
- Socrates 8dDocument8 pagesSocrates 8dcarolinaNo ratings yet
- A Socio-Cultural Dimension of Local Batik Industry Development in IndoneisaDocument28 pagesA Socio-Cultural Dimension of Local Batik Industry Development in Indoneisaprihadi nugrohoNo ratings yet
- Oil & Gas Rig Roles Functions ProcessesDocument5 pagesOil & Gas Rig Roles Functions ProcessesAnant Ramdial100% (1)
- DTS Letter of Request To IndustryDocument3 pagesDTS Letter of Request To IndustryJohn Paul MartinNo ratings yet
- Learning MicroStation For General UsersDocument413 pagesLearning MicroStation For General Userslakshmi mounikaNo ratings yet
- Towards Innovative Community Building: DLSU Holds Henry Sy, Sr. Hall GroundbreakingDocument2 pagesTowards Innovative Community Building: DLSU Holds Henry Sy, Sr. Hall GroundbreakingCarl ChiangNo ratings yet
- Alfa Laval DecanterDocument16 pagesAlfa Laval DecanterAKSHAY BHATKARNo ratings yet
- CBSE KV Class VIII SA I Maths Sample Question Paper 2015Document3 pagesCBSE KV Class VIII SA I Maths Sample Question Paper 2015Amrita SenNo ratings yet
- REHAU 20UFH InstallationDocument84 pagesREHAU 20UFH InstallationngrigoreNo ratings yet
- Econometrics IIDocument4 pagesEconometrics IINia Hania SolihatNo ratings yet
- VISAYAS STATE UNIVERSITY Soil Science Lab on Rocks and MineralsDocument5 pagesVISAYAS STATE UNIVERSITY Soil Science Lab on Rocks and MineralsAleah TyNo ratings yet