You might also like
- String Algorithms in C: Efficient Text Representation and SearchFrom EverandString Algorithms in C: Efficient Text Representation and SearchNo ratings yet
- Upload Test123Document4 pagesUpload Test123Nabin ThapaNo ratings yet
- Analysis of Algorithms: Θ, O, Ω NotationsDocument4 pagesAnalysis of Algorithms: Θ, O, Ω NotationsNabin ThapaNo ratings yet
- Algorithms Performance AnalysisDocument11 pagesAlgorithms Performance Analysisprerna kanawadeNo ratings yet
- AlgorithmDocument885 pagesAlgorithmash23ish100% (1)
- Datastructuers and Algorithms in C++Document5 pagesDatastructuers and Algorithms in C++sachin kumar shawNo ratings yet
- Data Structure: Analysis of Algorithms - Set 1 (Asymptotic Analysis)Document29 pagesData Structure: Analysis of Algorithms - Set 1 (Asymptotic Analysis)priyanjayNo ratings yet
- Complexity Analysis of Algorithms (Greek For Greek)Document5 pagesComplexity Analysis of Algorithms (Greek For Greek)Nguyệt NguyệtNo ratings yet
- Introduction and Elementary Data Structures: Analysis of AlgorithmsDocument12 pagesIntroduction and Elementary Data Structures: Analysis of Algorithmsgashaw asmamawNo ratings yet
- Asymptotic Analysis of Algorithms in Data StructuresDocument11 pagesAsymptotic Analysis of Algorithms in Data StructuresHailu BadyeNo ratings yet
- Analysis of Algorithms Chapter 1 IntroductionDocument41 pagesAnalysis of Algorithms Chapter 1 Introductiongashaw asmamawNo ratings yet
- Algorithmic Designing: Unit 1-1. Time and Space ComplexityDocument5 pagesAlgorithmic Designing: Unit 1-1. Time and Space ComplexityPratik KakaniNo ratings yet
- Data Structures Algorithm ComplexityDocument16 pagesData Structures Algorithm ComplexityPascal OkerekeNo ratings yet
- DAA Unit 1,2,3-1 (1)Document46 pagesDAA Unit 1,2,3-1 (1)abdulshahed231No ratings yet
- Analyzing Algorithm ComplexityDocument5 pagesAnalyzing Algorithm ComplexityAbhishek MitraNo ratings yet
- Analysis of Algorithms Set 2 Worst Average Best CasesDocument4 pagesAnalysis of Algorithms Set 2 Worst Average Best CasesMir ArifaNo ratings yet
- D35 Data Structure2012Document182 pagesD35 Data Structure2012Ponmalar SivarajNo ratings yet
- Complexity Analysis of AlgorithmsDocument25 pagesComplexity Analysis of Algorithmsanon_514479957No ratings yet
- Data Structure Part 3Document18 pagesData Structure Part 3keybird davidNo ratings yet
- Analysis of Algorithms - 12112014 - 054619AMDocument21 pagesAnalysis of Algorithms - 12112014 - 054619AMRussel PatrickNo ratings yet
- Lecture 1 PDFDocument4 pagesLecture 1 PDFmalaika zulfiqarNo ratings yet
- ADSA - MECSE-unit-1Document8 pagesADSA - MECSE-unit-1delphin jeraldNo ratings yet
- Complexity Space N TimeDocument36 pagesComplexity Space N Timeapi-3814408100% (4)
- EEB 435 Python LECTURE 3Document34 pagesEEB 435 Python LECTURE 3oswardNo ratings yet
- Analysis of Algorithms: Running TimeDocument5 pagesAnalysis of Algorithms: Running TimeSankardeep ChakrabortyNo ratings yet
- DAA - Ch. 1 (Lecture Notes)Document24 pagesDAA - Ch. 1 (Lecture Notes)xihafaf422No ratings yet
- Module 3 - Complexity of An AlgorithmDocument7 pagesModule 3 - Complexity of An AlgorithmarturogallardoedNo ratings yet
- Lecture 2 PDFDocument5 pagesLecture 2 PDFmalaika zulfiqarNo ratings yet
- Chapter 09 PDFDocument16 pagesChapter 09 PDFJohn YangNo ratings yet
- Ics 121 DS: Class 4 Asymptotic NotationsDocument34 pagesIcs 121 DS: Class 4 Asymptotic NotationsSukritNo ratings yet
- Theory of AlgorithmsDocument57 pagesTheory of AlgorithmsDesyilalNo ratings yet
- Data StructureDocument10 pagesData StructureRowellNo ratings yet
- ALGORITHM NOTES ANALYSIS DESIGNDocument38 pagesALGORITHM NOTES ANALYSIS DESIGNFredrick OnungaNo ratings yet
- Design and Analysis IntroductionDocument7 pagesDesign and Analysis Introductionsadaf abidNo ratings yet
- DAA All1Document56 pagesDAA All1jamdadeanujNo ratings yet
- Unit 2 NotesDocument45 pagesUnit 2 NotesB2No ratings yet
- Data Structure Module 1Document10 pagesData Structure Module 1ssreeram1312.tempNo ratings yet
- Algorithm Efficiency Measuring The Efficiency of AlgorithmsDocument3 pagesAlgorithm Efficiency Measuring The Efficiency of AlgorithmsAtefrachew SeyfuNo ratings yet
- 2.2 Analyzing Algorithms: Analyzing An Algorithm Has Come To Mean Predicting The Resources That The Algorithm RequiresDocument4 pages2.2 Analyzing Algorithms: Analyzing An Algorithm Has Come To Mean Predicting The Resources That The Algorithm Requiressrinjoy chakravortyNo ratings yet
- 01Chapter-One Introduction To Analysis of AlgorithmDocument39 pages01Chapter-One Introduction To Analysis of AlgorithmtasheebedaneNo ratings yet
- Daa NotesDocument6 pagesDaa NotesainocNo ratings yet
- Analysis of AlgorithmsDocument69 pagesAnalysis of AlgorithmsHadi Abdullah KhanNo ratings yet
- Algorithm Complexity Section 1Document6 pagesAlgorithm Complexity Section 1Prabhuanand SivashanmugamNo ratings yet
- DAA_U1-R18Document23 pagesDAA_U1-R18dhosheka123No ratings yet
- Growth of FunctionsDocument11 pagesGrowth of FunctionsRohit ChaudharyNo ratings yet
- Analysis of AlgorithmsDocument26 pagesAnalysis of AlgorithmsDanielMandefroNo ratings yet
- Analysis of AlgorithmsDocument5 pagesAnalysis of AlgorithmsDanish HussainNo ratings yet
- Analysis of AlgorithmsDocument17 pagesAnalysis of AlgorithmsXuân Sơn NguyễnNo ratings yet
- Understanding Algorithm ComplexityDocument37 pagesUnderstanding Algorithm ComplexityMohammed Yaseen Junaid 04No ratings yet
- DS Unit 1Document42 pagesDS Unit 1ashishmohan625No ratings yet
- Foca FileDocument16 pagesFoca FileShaweta ThakurNo ratings yet
- Design Ana of Algo HandbkDocument21 pagesDesign Ana of Algo HandbkEboka ChukwukaNo ratings yet
- Lecture 1Document35 pagesLecture 1Mithal KothariNo ratings yet
- Algorithms TutorialsDocument577 pagesAlgorithms Tutorialsanubhavjain28decNo ratings yet
- Time Complexity of AlgorithmsDocument28 pagesTime Complexity of Algorithmswjdan mohammedNo ratings yet
- AL101 MidtermDocument43 pagesAL101 Midtermdeb galangNo ratings yet
- Design and Analysis-Unit 1Document74 pagesDesign and Analysis-Unit 1jaipalsinghmalik47No ratings yet
- PROBLEM 7 - CDDocument4 pagesPROBLEM 7 - CDRavidya ShripatNo ratings yet
- PHD Thesis - Dalong Zhao-ZnO TFT Thin Film Passivation - Noise Analysis, Hooge ParameterDocument169 pagesPHD Thesis - Dalong Zhao-ZnO TFT Thin Film Passivation - Noise Analysis, Hooge Parameterjiaxin zhangNo ratings yet
- Phy 111 - Eos Exam 2015Document7 pagesPhy 111 - Eos Exam 2015caphus mazengeraNo ratings yet
- .Design and Development of Motorized Multipurpose MachineDocument3 pages.Design and Development of Motorized Multipurpose MachineANKITA MORENo ratings yet
- Free Fall ExperimentDocument31 pagesFree Fall ExperimentLeerzejPuntoNo ratings yet
- Official Statement On Public RelationsDocument1 pageOfficial Statement On Public RelationsAlexandra ZachiNo ratings yet
- Atma Bodha of Shri SankaracharyaDocument1 pageAtma Bodha of Shri SankaracharyaMerike TazaNo ratings yet
- Base Case Analysis Best CaseDocument6 pagesBase Case Analysis Best CaseMaphee CastellNo ratings yet
- 722.6 Transmission Conductor Plate Replacement DIYDocument3 pages722.6 Transmission Conductor Plate Replacement DIYcamaro67427100% (1)
- ABB Softstarters, Type PSR, PSS, PST/PSTBDocument50 pagesABB Softstarters, Type PSR, PSS, PST/PSTBElias100% (1)
- Government of India Sponsored Study on Small Industries Potential in Sultanpur DistrictDocument186 pagesGovernment of India Sponsored Study on Small Industries Potential in Sultanpur DistrictNisar Ahmed Ansari100% (1)
- Syllabus - EU Institutions and Comparative Political System - 2023springDocument10 pagesSyllabus - EU Institutions and Comparative Political System - 2023springreif annieNo ratings yet
- Autodesk Revit 2014 ContentDocument6 pagesAutodesk Revit 2014 ContentGatot HardiyantoNo ratings yet
- Design of A Small Flight Control SystemDocument120 pagesDesign of A Small Flight Control SystemRuben RubenNo ratings yet
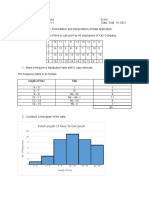
- Cedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDocument4 pagesCedrix James Estoquia - OLLC Lesson 4.6 Presentation and Interpretation of Data ApplicationDeuK WR100% (1)
- Product Item Code Model Item Description MRP Count Down PricesDocument1 pageProduct Item Code Model Item Description MRP Count Down Pricesලහිරු විතානාච්චිNo ratings yet
- Guardian Brand Book - 042019Document15 pagesGuardian Brand Book - 042019FTU.CS2 Nguyễn Việt HưngNo ratings yet
- Engine Cpta Czca Czea Ea211 EngDocument360 pagesEngine Cpta Czca Czea Ea211 EngleuchiNo ratings yet
- CMO Olympiad Book For Class 3Document13 pagesCMO Olympiad Book For Class 3Srividya BaiNo ratings yet
- Conducting Properties of MaterialsDocument28 pagesConducting Properties of MaterialsMarzook JrNo ratings yet
- Lecture 8: Dynamics Characteristics of SCR: Dr. Aadesh Kumar AryaDocument9 pagesLecture 8: Dynamics Characteristics of SCR: Dr. Aadesh Kumar Aryaaadesh kumar aryaNo ratings yet
- Investigação de Um Novo Circuito de Balanceamento de Tensão para Turbinas Eólicas Baseadas em PMSG Offshore Conectadas em ParaleloDocument7 pagesInvestigação de Um Novo Circuito de Balanceamento de Tensão para Turbinas Eólicas Baseadas em PMSG Offshore Conectadas em ParaleloDaniel reisNo ratings yet
- Methodology of Legal Research: Challenges and OpportunitiesDocument8 pagesMethodology of Legal Research: Challenges and OpportunitiesBhan WatiNo ratings yet
- Equipment & Piping Layout T.N. GopinathDocument88 pagesEquipment & Piping Layout T.N. Gopinathhirenkumar patelNo ratings yet
- The School and The Community: Prepared By: Sen Xiao Jun Mohana Sundra Segaran Kaviyanayagi PonuduraiDocument26 pagesThe School and The Community: Prepared By: Sen Xiao Jun Mohana Sundra Segaran Kaviyanayagi PonuduraiKaviya SKTDSNo ratings yet
- Fireclass: FC503 & FC506Document16 pagesFireclass: FC503 & FC506Mersal AliraqiNo ratings yet
- Substation Automation HandbookDocument454 pagesSubstation Automation HandbookGiancarloEle100% (6)
- SARTIKA LESTARI PCR COVID-19 POSITIVEDocument1 pageSARTIKA LESTARI PCR COVID-19 POSITIVEsartika lestariNo ratings yet
- ARC JMK-Research June-2021Document6 pagesARC JMK-Research June-2021Karthik SengodanNo ratings yet
- Pump Card Analysis Simplified and ImprovedDocument14 pagesPump Card Analysis Simplified and ImprovedOsmund MwangupiliNo ratings yet